Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization

0
Sign in to get full access
Overview
- This paper proposes a method for accurately compressing text-to-image diffusion models using vector quantization.
- The key contributions include an efficient vector quantization technique and a practical method for finetuning the compressed model without retraining from scratch.
- The compressed model demonstrates comparable performance to the original model while achieving significant storage and inference speedup.
Plain English Explanation
Compression of Text-to-Image Diffusion Models
This research paper explores a way to reduce the size and speed up the performance of text-to-image diffusion models, which are AI systems that can generate images from text descriptions.
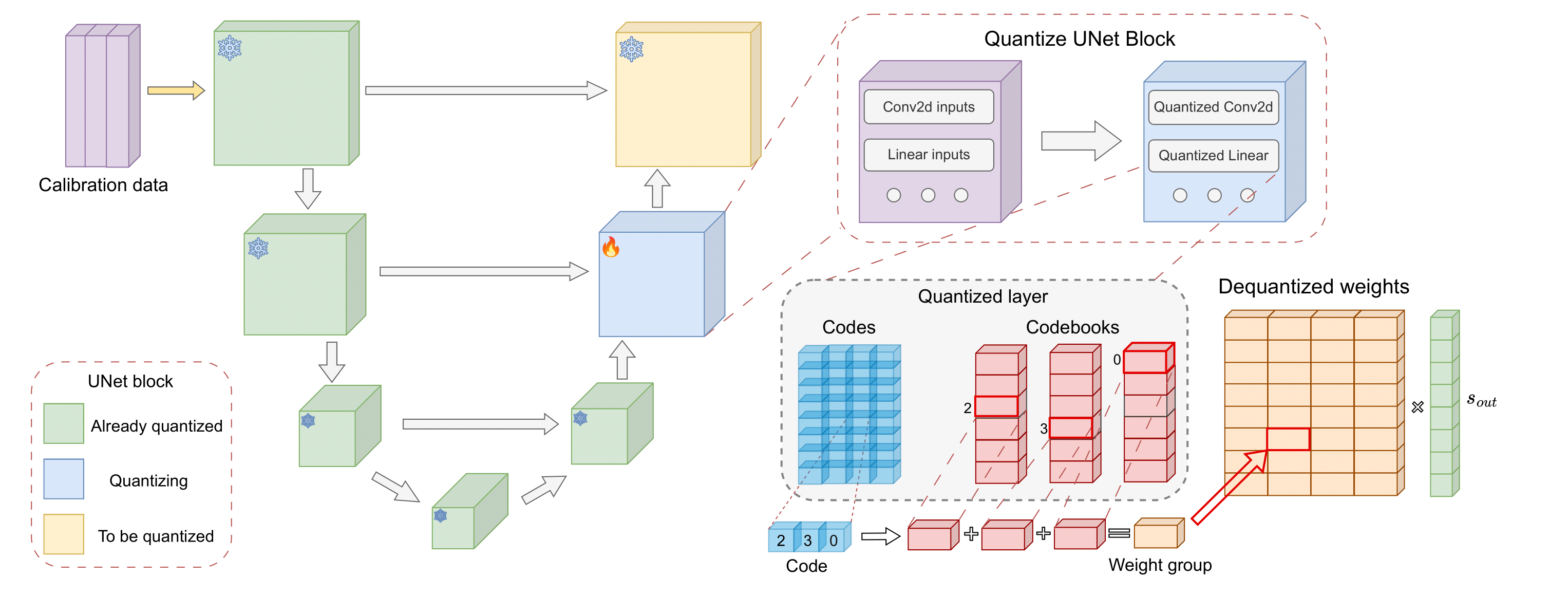
The main idea is to use a technique called vector quantization to compress the internal parameters of the diffusion model. Vector quantization involves representing complex data (like the model's parameters) using a smaller set of "codebook" values. This allows the model to be stored and run much more efficiently, without a big loss in image quality.
Additionally, the researchers developed a practical method to fine-tune the compressed model - that is, to further improve its performance on specific tasks - without having to retrain the entire model from scratch. This makes the compression technique more usable in real-world applications.
The end result is a compressed text-to-image model that maintains comparable performance to the original, full-size model, but with significantly reduced storage requirements and faster inference speed. This could enable the deployment of these powerful AI models on devices with limited computing resources, or allow for more efficient use of cloud computing infrastructure.
Technical Explanation
The key technical contributions of this paper are:
-
Vector Quantization Technique: The researchers developed an efficient vector quantization method to compress the diffusion model's parameters. This involves learning a compact "codebook" that can represent the original parameter values with minimal distortion.
-
Fine-Tuning Compressed Model: They also proposed a practical approach to fine-tune the compressed model without retraining from scratch. This allows further performance improvements on specific tasks while preserving the benefits of the initial compression.
The paper evaluates their compression method on several text-to-image diffusion models, including DALL-E 2 and Stable Diffusion. The results show that the compressed models can achieve up to 8x smaller model size and 2.5x faster inference compared to the original models, while maintaining similar image generation quality.
Some key technical insights from the experiments include:
- Careful design of the vector quantization codebook is critical for preserving model performance.
- Fine-tuning the compressed model is an effective way to regain any lost capability compared to the original.
- The compression method is generally applicable across different diffusion model architectures.
Critical Analysis
The paper provides a thorough and well-executed study on compressing text-to-image diffusion models. The technical contributions are significant, as the ability to efficiently compress these large, powerful models opens up new possibilities for their deployment and use.
However, the paper does not extensively discuss potential limitations or caveats of the approach. For example, it's unclear how the compression method would scale to even larger or more complex diffusion models, or how it might interact with other model optimization techniques like pruning or quantization.
Additionally, while the fine-tuning method is a valuable contribution, the paper does not explore the full range of fine-tuning capabilities. It would be interesting to see how the compressed models perform on a wider variety of downstream tasks beyond just the original training distribution.
Overall, this research represents an important step forward in making text-to-image diffusion models more practical and accessible. Further work could explore the broader implications and limitations of this compression technique.
Conclusion
This paper presents a novel technique for accurately compressing text-to-image diffusion models using vector quantization. The key innovations include an efficient vector quantization method and a practical approach for fine-tuning the compressed model.
The results demonstrate that the compressed models can achieve significant reductions in storage size and inference time, while maintaining comparable performance to the original full-size models. This could enable the deployment of powerful text-to-image AI systems on a wider range of hardware platforms, from edge devices to cloud infrastructure.
The compression technique represents an important advance in making cutting-edge generative AI models more accessible and practical for real-world applications. Further research exploring the scalability and broader implications of this approach could yield valuable insights for the field of generative AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Vage Egiazarian, Denis Kuznedelev, Anton Voronov, Ruslan Svirschevski, Michael Goin, Daniil Pavlov, Dan Alistarh, Dmitry Baranchuk
Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
Read more9/4/2024

0
MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization
Tianchen Zhao, Xuefei Ning, Tongcheng Fang, Enshu Liu, Guyue Huang, Zinan Lin, Shengen Yan, Guohao Dai, Yu Wang
Diffusion models have achieved significant visual generation quality. However, their significant computational and memory costs pose challenge for their application on resource-constrained mobile devices or even desktop GPUs. Recent few-step diffusion models reduces the inference time by reducing the denoising steps. However, their memory consumptions are still excessive. The Post Training Quantization (PTQ) replaces high bit-width FP representation with low-bit integer values (INT4/8) , which is an effective and efficient technique to reduce the memory cost. However, when applying to few-step diffusion models, existing quantization methods face challenges in preserving both the image quality and text alignment. To address this issue, we propose an mixed-precision quantization framework - MixDQ. Firstly, We design specialized BOS-aware quantization method for highly sensitive text embedding quantization. Then, we conduct metric-decoupled sensitivity analysis to measure the sensitivity of each layer. Finally, we develop an integer-programming-based method to conduct bit-width allocation. While existing quantization methods fall short at W8A8, MixDQ could achieve W8A8 without performance loss, and W4A8 with negligible visual degradation. Compared with FP16, we achieve 3-4x reduction in model size and memory cost, and 1.45x latency speedup.
Read more5/31/2024
✅
0
Post-training Quantization for Text-to-Image Diffusion Models with Progressive Calibration and Activation Relaxing
Siao Tang, Xin Wang, Hong Chen, Chaoyu Guan, Zewen Wu, Yansong Tang, Wenwu Zhu
High computational overhead is a troublesome problem for diffusion models. Recent studies have leveraged post-training quantization (PTQ) to compress diffusion models. However, most of them only focus on unconditional models, leaving the quantization of widely-used pretrained text-to-image models, e.g., Stable Diffusion, largely unexplored. In this paper, we propose a novel post-training quantization method PCR (Progressive Calibration and Relaxing) for text-to-image diffusion models, which consists of a progressive calibration strategy that considers the accumulated quantization error across timesteps, and an activation relaxing strategy that improves the performance with negligible cost. Additionally, we demonstrate the previous metrics for text-to-image diffusion model quantization are not accurate due to the distribution gap. To tackle the problem, we propose a novel QDiffBench benchmark, which utilizes data in the same domain for more accurate evaluation. Besides, QDiffBench also considers the generalization performance of the quantized model outside the calibration dataset. Extensive experiments on Stable Diffusion and Stable Diffusion XL demonstrate the superiority of our method and benchmark. Moreover, we are the first to achieve quantization for Stable Diffusion XL while maintaining the performance.
Read more7/9/2024

0
ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers for Image and Video Generation
Tianchen Zhao, Tongcheng Fang, Enshu Liu, Rui Wan, Widyadewi Soedarmadji, Shiyao Li, Zinan Lin, Guohao Dai, Shengen Yan, Huazhong Yang, Xuefei Ning, Yu Wang
Diffusion transformers (DiTs) have exhibited remarkable performance in visual generation tasks, such as generating realistic images or videos based on textual instructions. However, larger model sizes and multi-frame processing for video generation lead to increased computational and memory costs, posing challenges for practical deployment on edge devices. Post-Training Quantization (PTQ) is an effective method for reducing memory costs and computational complexity. When quantizing diffusion transformers, we find that applying existing diffusion quantization methods designed for U-Net faces challenges in preserving quality. After analyzing the major challenges for quantizing diffusion transformers, we design an improved quantization scheme: ViDiT-Q: Video and Image Diffusion Transformer Quantization) to address these issues. Furthermore, we identify highly sensitive layers and timesteps hinder quantization for lower bit-widths. To tackle this, we improve ViDiT-Q with a novel metric-decoupled mixed-precision quantization method (ViDiT-Q-MP). We validate the effectiveness of ViDiT-Q across a variety of text-to-image and video models. While baseline quantization methods fail at W8A8 and produce unreadable content at W4A8, ViDiT-Q achieves lossless W8A8 quantization. ViDiTQ-MP achieves W4A8 with negligible visual quality degradation, resulting in a 2.5x memory optimization and a 1.5x latency speedup.
Read more7/2/2024