Post-training Quantization for Text-to-Image Diffusion Models with Progressive Calibration and Activation Relaxing

0
✅
Sign in to get full access
Overview
- Diffusion models, like the popular Stable Diffusion, have high computational overhead, making them challenging to deploy.
- Recent studies have used post-training quantization (PTQ) to compress diffusion models, but most focus on unconditional models rather than text-to-image models.
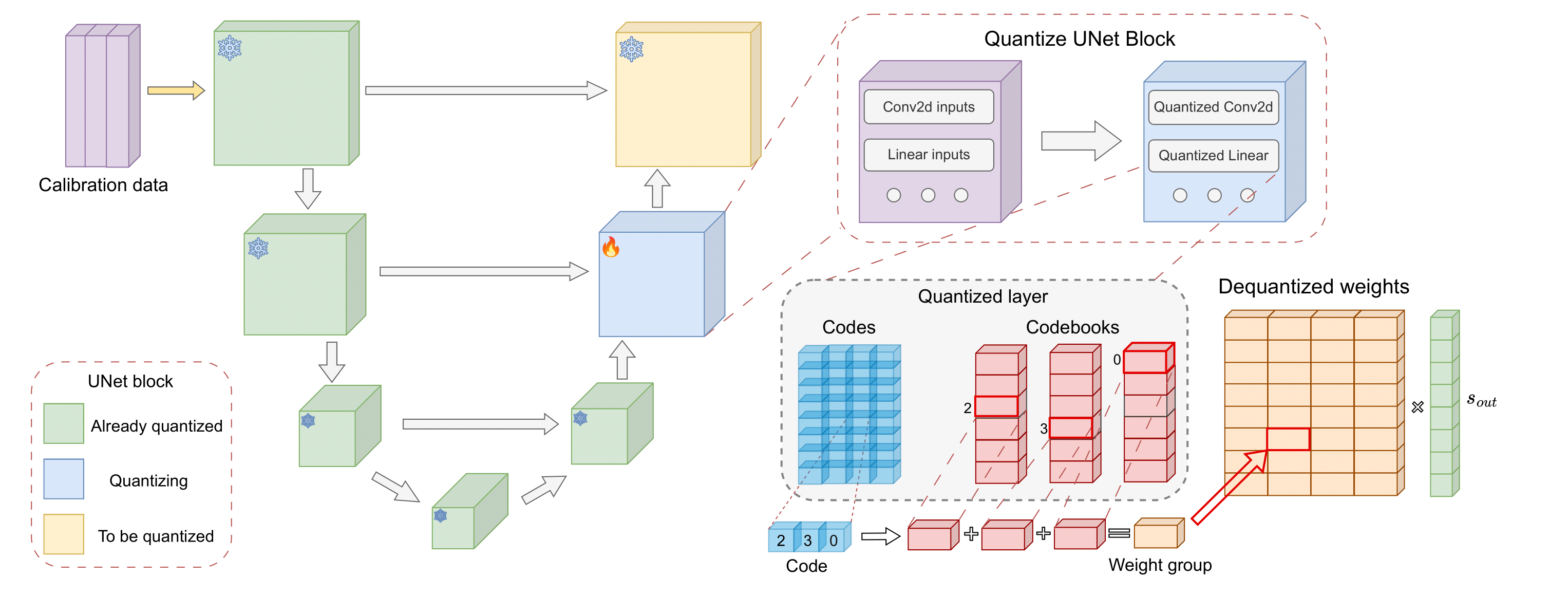
- This paper proposes a novel PTQ method called PCR (Progressive Calibration and Relaxing) for compressing text-to-image diffusion models.
- The authors also introduce a new benchmark, QDiffBench, to more accurately evaluate the quantization of text-to-image diffusion models.
Plain English Explanation
Diffusion models, which are used to generate images from text, require a lot of computing power to run. This can make them difficult to use, especially on devices with limited resources. Researchers have explored ways to compress these models using a technique called post-training quantization, which reduces the memory and processing requirements.
However, most of this work has focused on simpler, unconditional diffusion models, rather than the more complex text-to-image models like Stable Diffusion. The authors of this paper wanted to develop a better way to compress text-to-image diffusion models while maintaining their performance.
To do this, they created a new quantization method called PCR, which uses a "progressive calibration" strategy to account for errors that build up over time, and an "activation relaxing" technique to further improve the model's performance. They also found that the standard ways of evaluating quantized diffusion models don't work well for text-to-image models, so they created a new benchmark called QDiffBench to provide a more accurate assessment.
The authors tested their PCR method on Stable Diffusion and Stable Diffusion XL, and showed that it outperformed previous quantization techniques. They were even able to quantize the larger Stable Diffusion XL model without significantly degrading its performance, which is a notable achievement.
Technical Explanation
The paper proposes a novel post-training quantization (PTQ) method called PCR (Progressive Calibration and Relaxing) for compressing text-to-image diffusion models, such as Stable Diffusion and Stable Diffusion XL.
The PCR method consists of two key components:
-
Progressive Calibration: This strategy considers the accumulated quantization error across timesteps, rather than assuming a uniform error distribution. This helps the quantization process adapt to the unique characteristics of each timestep.
-
Activation Relaxing: This technique improves the performance of the quantized model with negligible computational overhead. It adjusts the activation ranges to better match the model's behavior after quantization.
Additionally, the authors identify issues with the existing metrics used to evaluate quantized text-to-image diffusion models. They propose a new benchmark, QDiffBench, which uses data from the same domain as the model's training data for a more accurate evaluation. QDiffBench also considers the model's generalization performance beyond the calibration dataset.
Experiments on Stable Diffusion and Stable Diffusion XL demonstrate the effectiveness of the PCR method and the QDiffBench benchmark. The authors show that PCR outperforms previous quantization techniques, and they are the first to achieve quantization of the Stable Diffusion XL model while maintaining its performance.
Critical Analysis
The paper presents a valuable contribution to the field of efficient diffusion model deployment, addressing the important challenge of high computational overhead. The authors' insights on the limitations of existing quantization evaluation metrics for text-to-image models and the development of the QDiffBench benchmark are particularly noteworthy.
However, the paper could have delved deeper into the potential limitations of the PCR method. For example, it would be interesting to understand how the progressive calibration and activation relaxing strategies perform under different levels of model complexity or data distribution shifts. Additionally, the authors could have explored the generalizability of their approach to other types of diffusion models beyond text-to-image, such as conditional diffusion models or diffusion transformers.
Overall, this paper makes a significant contribution to the field of efficient diffusion model deployment and provides a solid foundation for further research in this area.
Conclusion
This paper presents a novel post-training quantization method, PCR, for compressing text-to-image diffusion models like Stable Diffusion. The authors' key innovations include a progressive calibration strategy and an activation relaxing technique, which together improve the performance of the quantized models.
Additionally, the authors identify limitations in the existing evaluation metrics for quantized text-to-image diffusion models and introduce a new benchmark, QDiffBench, to address these issues. Extensive experiments demonstrate the effectiveness of the PCR method and the improved accuracy of the QDiffBench benchmark.
The ability to efficiently deploy high-performance diffusion models has important implications for a wide range of real-world applications, from generative art to content creation. The advances presented in this paper represent a significant step forward in making these powerful models more accessible and practical to use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
Post-training Quantization for Text-to-Image Diffusion Models with Progressive Calibration and Activation Relaxing
Siao Tang, Xin Wang, Hong Chen, Chaoyu Guan, Zewen Wu, Yansong Tang, Wenwu Zhu
High computational overhead is a troublesome problem for diffusion models. Recent studies have leveraged post-training quantization (PTQ) to compress diffusion models. However, most of them only focus on unconditional models, leaving the quantization of widely-used pretrained text-to-image models, e.g., Stable Diffusion, largely unexplored. In this paper, we propose a novel post-training quantization method PCR (Progressive Calibration and Relaxing) for text-to-image diffusion models, which consists of a progressive calibration strategy that considers the accumulated quantization error across timesteps, and an activation relaxing strategy that improves the performance with negligible cost. Additionally, we demonstrate the previous metrics for text-to-image diffusion model quantization are not accurate due to the distribution gap. To tackle the problem, we propose a novel QDiffBench benchmark, which utilizes data in the same domain for more accurate evaluation. Besides, QDiffBench also considers the generalization performance of the quantized model outside the calibration dataset. Extensive experiments on Stable Diffusion and Stable Diffusion XL demonstrate the superiority of our method and benchmark. Moreover, we are the first to achieve quantization for Stable Diffusion XL while maintaining the performance.
Read more7/9/2024
0
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Vage Egiazarian, Denis Kuznedelev, Anton Voronov, Ruslan Svirschevski, Michael Goin, Daniil Pavlov, Dan Alistarh, Dmitry Baranchuk
Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
Read more9/4/2024
🔍
0
Towards Accurate Post-training Quantization for Diffusion Models
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, Jiwen Lu
In this paper, we propose an accurate data-free post-training quantization framework of diffusion models (ADP-DM) for efficient image generation. Conventional data-free quantization methods learn shared quantization functions for tensor discretization regardless of the generation timesteps, while the activation distribution differs significantly across various timesteps. The calibration images are acquired in random timesteps which fail to provide sufficient information for generalizable quantization function learning. Both issues cause sizable quantization errors with obvious image generation performance degradation. On the contrary, we design group-wise quantization functions for activation discretization in different timesteps and sample the optimal timestep for informative calibration image generation, so that our quantized diffusion model can reduce the discretization errors with negligible computational overhead. Specifically, we partition the timesteps according to the importance weights of quantization functions in different groups, which are optimized by differentiable search algorithms. We also select the optimal timestep for calibration image generation by structural risk minimizing principle in order to enhance the generalization ability in the deployment of quantized diffusion model. Extensive experimental results show that our method outperforms the state-of-the-art post-training quantization of diffusion model by a sizable margin with similar computational cost.
Read more5/1/2024
📉
0
QVD: Post-training Quantization for Video Diffusion Models
Shilong Tian, Hong Chen, Chengtao Lv, Yu Liu, Jinyang Guo, Xianglong Liu, Shengxi Li, Hao Yang, Tao Xie
Recently, video diffusion models (VDMs) have garnered significant attention due to their notable advancements in generating coherent and realistic video content. However, processing multiple frame features concurrently, coupled with the considerable model size, results in high latency and extensive memory consumption, hindering their broader application. Post-training quantization (PTQ) is an effective technique to reduce memory footprint and improve computational efficiency. Unlike image diffusion, we observe that the temporal features, which are integrated into all frame features, exhibit pronounced skewness. Furthermore, we investigate significant inter-channel disparities and asymmetries in the activation of video diffusion models, resulting in low coverage of quantization levels by individual channels and increasing the challenge of quantization. To address these issues, we introduce the first PTQ strategy tailored for video diffusion models, dubbed QVD. Specifically, we propose the High Temporal Discriminability Quantization (HTDQ) method, designed for temporal features, which retains the high discriminability of quantized features, providing precise temporal guidance for all video frames. In addition, we present the Scattered Channel Range Integration (SCRI) method which aims to improve the coverage of quantization levels across individual channels. Experimental validations across various models, datasets, and bit-width settings demonstrate the effectiveness of our QVD in terms of diverse metrics. In particular, we achieve near-lossless performance degradation on W8A8, outperforming the current methods by 205.12 in FVD.
Read more7/18/2024