Active and Passive Causal Inference Learning

0
🤯
Sign in to get full access
Overview
- This paper serves as an introduction to causal inference for machine learning researchers, engineers, and students.
- It outlines key assumptions needed for causal identification, such as exchangeability, positivity, consistency, and the absence of interference.
- The paper categorizes causal inference techniques into two buckets: active and passive approaches.
- It describes randomized controlled trials, bandit-based approaches, classical methods like matching and inverse probability weighting, and recent deep learning-based algorithms.
- The paper also discusses missing aspects of causal inference, such as collider biases, to provide a diverse set of starting points for further research.
Plain English Explanation
Causal inference is the process of determining the cause-and-effect relationships between different factors. This paper aims to provide a starting point for those interested in learning about causal inference, but who may not be familiar with the topic.
The paper begins by explaining some key assumptions that are essential for being able to identify causal relationships. These include the idea of exchangeability, where the factors being studied are similar enough to be compared, positivity, where there is a non-zero chance of each factor being present, consistency, where the factors have a clear and consistent effect, and the absence of interference, where the factors don't influence each other in unexpected ways.
The paper then goes on to describe two main categories of causal inference techniques: active approaches and passive approaches. Active approaches involve actively manipulating the factors, such as through randomized controlled trials or bandit-based methods. Passive approaches, on the other hand, rely on observational data and techniques like matching and inverse probability weighting to infer causal relationships.
The paper finishes by highlighting some of the gaps in causal inference, such as the issue of collider biases, to provide readers with a diverse set of starting points for further research and exploration in this important field.
Technical Explanation
The paper starts by outlining a set of key assumptions that are collectively needed for causal identification, including exchangeability, positivity, consistency, and the absence of interference. These assumptions form the foundation for the causal inference techniques described in the paper.
The authors then categorize causal inference techniques into two main approaches: active and passive. In the active category, the paper discusses randomized controlled trials, where factors are actively manipulated, and bandit-based approaches, which involve iterative experimentation and learning.
In the passive category, the paper covers classical techniques such as matching and inverse probability weighting, which use observational data to infer causal relationships. It also discusses more recent deep learning-based algorithms for causal inference.
The paper concludes by highlighting some of the missing aspects of causal inference, such as the problem of collider biases, which can distort causal estimates. This is done to provide readers with a comprehensive understanding of the field and to encourage further research and exploration.
Critical Analysis
The paper provides a solid introduction to the key concepts and techniques in causal inference, making it a valuable resource for machine learning researchers, engineers, and students. By clearly categorizing the approaches into active and passive methods, the paper helps readers understand the different strategies available for inferring causal relationships.
However, the paper could have delved deeper into the various assumptions and their implications. For example, the paper could have provided more detailed examples or case studies to illustrate the importance of assumptions like exchangeability and the consequences of violating them.
Additionally, the paper could have discussed the trade-offs and limitations of the different causal inference techniques presented. For instance, it could have highlighted the strengths and weaknesses of randomized controlled trials compared to observational methods, or the challenges associated with implementing deep learning-based causal inference algorithms in practice.
Overall, the paper provides a solid foundation for understanding causal inference, but there is still room for further exploration and discussion of the nuances and complexities involved in this field.
Conclusion
This paper serves as an accessible introduction to the field of causal inference, which is essential for machine learning researchers, engineers, and students who want to understand the underlying causes of the phenomena they study. By outlining the key assumptions and categorizing the various causal inference techniques, the paper provides a comprehensive starting point for those new to the topic.
The paper's emphasis on both active and passive approaches, as well as its discussion of emerging deep learning-based methods, ensures that readers are exposed to a diverse range of causal inference strategies. Although the paper could have delved deeper into certain aspects, it successfully fulfills its goal of serving as a primer for those interested in exploring the exciting and rapidly evolving field of causal inference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Active and Passive Causal Inference Learning
Daniel Jiwoong Im, Kyunghyun Cho
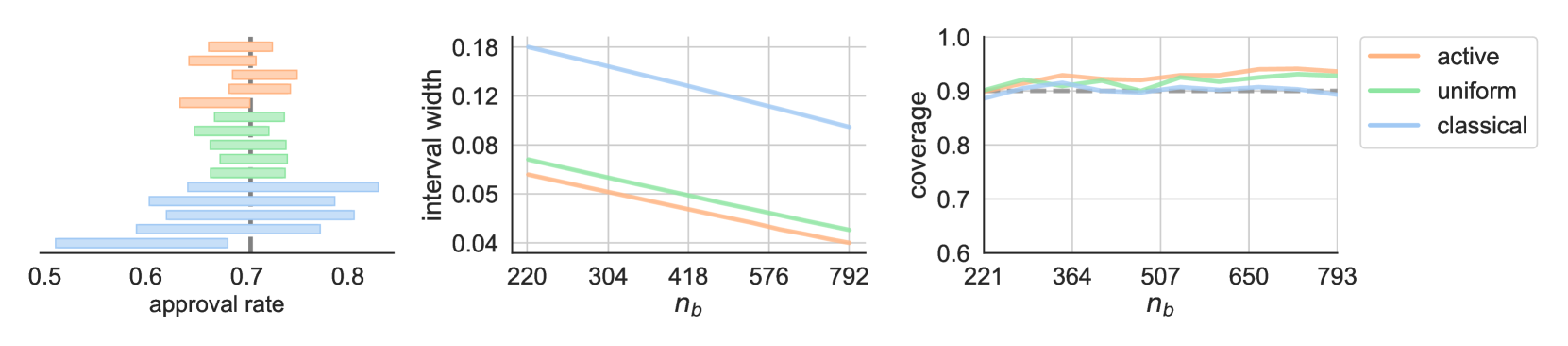
This paper serves as a starting point for machine learning researchers, engineers and students who are interested in but not yet familiar with causal inference. We start by laying out an important set of assumptions that are collectively needed for causal identification, such as exchangeability, positivity, consistency and the absence of interference. From these assumptions, we build out a set of important causal inference techniques, which we do so by categorizing them into two buckets; active and passive approaches. We describe and discuss randomized controlled trials and bandit-based approaches from the active category. We then describe classical approaches, such as matching and inverse probability weighting, in the passive category, followed by more recent deep learning based algorithms. By finishing the paper with some of the missing aspects of causal inference from this paper, such as collider biases, we expect this paper to provide readers with a diverse set of starting points for further reading and research in causal inference and discovery.
Read more8/28/2024
0
Active Statistical Inference
Tijana Zrnic, Emmanuel J. Cand`es
Inspired by the concept of active learning, we propose active inference$unicode{x2013}$a methodology for statistical inference with machine-learning-assisted data collection. Assuming a budget on the number of labels that can be collected, the methodology uses a machine learning model to identify which data points would be most beneficial to label, thus effectively utilizing the budget. It operates on a simple yet powerful intuition: prioritize the collection of labels for data points where the model exhibits uncertainty, and rely on the model's predictions where it is confident. Active inference constructs provably valid confidence intervals and hypothesis tests while leveraging any black-box machine learning model and handling any data distribution. The key point is that it achieves the same level of accuracy with far fewer samples than existing baselines relying on non-adaptively-collected data. This means that for the same number of collected samples, active inference enables smaller confidence intervals and more powerful p-values. We evaluate active inference on datasets from public opinion research, census analysis, and proteomics.
Read more5/30/2024
🤯
0
A Brief Introduction to Causal Inference in Machine Learning
Kyunghyun Cho
This is a lecture note produced for DS-GA 3001.003 Special Topics in DS - Causal Inference in Machine Learning at the Center for Data Science, New York University in Spring, 2024. This course was created to target master's and PhD level students with basic background in machine learning but who were not exposed to causal inference or causal reasoning in general previously. In particular, this course focuses on introducing such students to expand their view and knowledge of machine learning to incorporate causal reasoning, as this aspect is at the core of so-called out-of-distribution generalization (or lack thereof.)
Read more5/15/2024

0
Active Causal Learning for Decoding Chemical Complexities with Targeted Interventions
Zachary R. Fox, Ayana Ghosh
Predicting and enhancing inherent properties based on molecular structures is paramount to design tasks in medicine, materials science, and environmental management. Most of the current machine learning and deep learning approaches have become standard for predictions, but they face challenges when applied across different datasets due to reliance on correlations between molecular representation and target properties. These approaches typically depend on large datasets to capture the diversity within the chemical space, facilitating a more accurate approximation, interpolation, or extrapolation of the chemical behavior of molecules. In our research, we introduce an active learning approach that discerns underlying cause-effect relationships through strategic sampling with the use of a graph loss function. This method identifies the smallest subset of the dataset capable of encoding the most information representative of a much larger chemical space. The identified causal relations are then leveraged to conduct systematic interventions, optimizing the design task within a chemical space that the models have not encountered previously. While our implementation focused on the QM9 quantum-chemical dataset for a specific design task-finding molecules with a large dipole moment-our active causal learning approach, driven by intelligent sampling and interventions, holds potential for broader applications in molecular, materials design and discovery.
Read more4/8/2024