AD-CLIP: Adapting Domains in Prompt Space Using CLIP

0
👁️
Sign in to get full access
Overview
- Deep learning models often struggle to perform well when the training and test data come from different domains.
- Unsupervised domain adaptation (DA) is a popular solution to this problem, but current DA techniques rely on visual backbones that may lack semantic richness.
- Large-scale vision-language foundation models like CLIP have potential for DA, but their effectiveness has not been fully explored.
- To address this, the authors introduce AD-CLIP, a domain-agnostic prompt learning strategy for CLIP that aims to solve the DA problem in the prompt space.
Plain English Explanation
The paper focuses on a common problem in machine learning called domain adaptation. Domain adaptation occurs when the data used to train a model (the source domain) is different from the data the model is applied to (the target domain). This can cause the model to perform poorly on the target domain.
To address this, the researchers developed a new technique called AD-CLIP. AD-CLIP uses a popular vision-language model called CLIP to learn domain-agnostic prompts - short text phrases that can be used to classify images from different domains.
The key idea is to leverage CLIP's frozen vision backbone to extract both the style (or domain) information and the content information from images. This information is then used to learn prompts that are designed to work well across different domains, without requiring any labeled target domain data.
The researchers tested AD-CLIP on several benchmark domain adaptation datasets and found it outperformed existing approaches. This suggests that using large language models like CLIP in a prompt-based manner can be an effective way to tackle domain adaptation challenges.
Technical Explanation
The authors propose AD-CLIP, a domain-agnostic prompt learning strategy for the CLIP model. CLIP is a large-scale vision-language foundation model that has shown promising results, but its effectiveness for domain adaptation has not been fully explored.
The key components of AD-CLIP are:
-
Leveraging CLIP's Vision Backbone: The authors use the frozen vision backbone of CLIP to extract both image style (domain) and content information. This information is then used to learn prompt tokens that are designed to be domain-invariant and class-generalizable.
-
Supervised Contrastive Learning: In the source domain, the authors use standard supervised contrastive learning to train the prompt tokens.
-
Entropy Minimization: To align the domains in the embedding space, the authors propose an entropy minimization strategy using the target domain data.
-
Cross-Domain Style Mapping: For the scenario where only target domain samples are available during testing, the authors propose a cross-domain style mapping network to hallucinate domain-agnostic prompt tokens.
The authors evaluate AD-CLIP on three benchmark domain adaptation datasets and demonstrate its effectiveness compared to existing techniques. This suggests that using prompts with large vision-language models like CLIP can be a promising approach for tackling domain adaptation challenges.
Critical Analysis
The paper presents a novel and promising approach to domain adaptation using CLIP, a large-scale vision-language model. The key strengths of the work include:
-
Leveraging CLIP's Semantic Richness: By using CLIP's frozen vision backbone to extract both style and content information, the authors are able to capture richer semantic representations compared to approaches that rely solely on visual features.
-
Domain-Agnostic Prompt Learning: The prompt-based approach allows the model to learn representations that are inherently more transferable across domains, without requiring labeled target domain data.
-
Strong Empirical Performance: The authors demonstrate the effectiveness of AD-CLIP on several benchmark datasets, outperforming existing domain adaptation techniques.
However, the paper also has some limitations:
-
Computational Complexity: The proposed approach, especially the cross-domain style mapping component, may be computationally intensive and require significant training resources.
-
Generalization to Other Tasks: The authors focus solely on image classification tasks, and it's unclear how well the approach would generalize to other domain adaptation scenarios, such as those involving text or multimodal data.
-
Lack of Ablation Studies: The paper could have benefited from more detailed ablation studies to better understand the individual contributions of the different components of the AD-CLIP framework.
Overall, the paper presents a compelling approach to addressing domain adaptation challenges using large vision-language models like CLIP. Future research could explore ways to improve the computational efficiency of the approach and investigate its applicability to a broader range of domain adaptation problems.
Conclusion
The paper introduces AD-CLIP, a domain-agnostic prompt learning strategy that leverages the semantic richness of the CLIP model to tackle the problem of unsupervised domain adaptation. By extracting both style and content information from images and using this to learn domain-invariant prompts, AD-CLIP demonstrates strong empirical performance on several benchmark datasets.
This work highlights the potential of large-scale vision-language models like CLIP for addressing challenging domain adaptation problems, where traditional approaches that rely solely on visual features may fall short. The prompt-based, domain-agnostic learning strategy proposed in this paper represents an important step forward in the field of domain adaptation, and could have significant implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
AD-CLIP: Adapting Domains in Prompt Space Using CLIP
Mainak Singha, Harsh Pal, Ankit Jha, Biplab Banerjee
Although deep learning models have shown impressive performance on supervised learning tasks, they often struggle to generalize well when the training (source) and test (target) domains differ. Unsupervised domain adaptation (DA) has emerged as a popular solution to this problem. However, current DA techniques rely on visual backbones, which may lack semantic richness. Despite the potential of large-scale vision-language foundation models like CLIP, their effectiveness for DA has yet to be fully explored. To address this gap, we introduce textsc{AD-CLIP}, a domain-agnostic prompt learning strategy for CLIP that aims to solve the DA problem in the prompt space. We leverage the frozen vision backbone of CLIP to extract both image style (domain) and content information, which we apply to learn prompt tokens. Our prompts are designed to be domain-invariant and class-generalizable, by conditioning prompt learning on image style and content features simultaneously. We use standard supervised contrastive learning in the source domain, while proposing an entropy minimization strategy to align domains in the embedding space given the target domain data. We also consider a scenario where only target domain samples are available during testing, without any source domain data, and propose a cross-domain style mapping network to hallucinate domain-agnostic tokens. Our extensive experiments on three benchmark DA datasets demonstrate the effectiveness of textsc{AD-CLIP} compared to existing literature. Code is available at url{https://github.com/mainaksingha01/AD-CLIP}
Read more9/17/2024

0
Rethinking Domain Adaptation and Generalization in the Era of CLIP
Ruoyu Feng, Tao Yu, Xin Jin, Xiaoyuan Yu, Lei Xiao, Zhibo Chen
In recent studies on domain adaptation, significant emphasis has been placed on the advancement of learning shared knowledge from a source domain to a target domain. Recently, the large vision-language pre-trained model, i.e., CLIP has shown strong ability on zero-shot recognition, and parameter efficient tuning can further improve its performance on specific tasks. This work demonstrates that a simple domain prior boosts CLIP's zero-shot recognition in a specific domain. Besides, CLIP's adaptation relies less on source domain data due to its diverse pre-training dataset. Furthermore, we create a benchmark for zero-shot adaptation and pseudo-labeling based self-training with CLIP. Last but not least, we propose to improve the task generalization ability of CLIP from multiple unlabeled domains, which is a more practical and unique scenario. We believe our findings motivate a rethinking of domain adaptation benchmarks and the associated role of related algorithms in the era of CLIP.
Read more7/23/2024
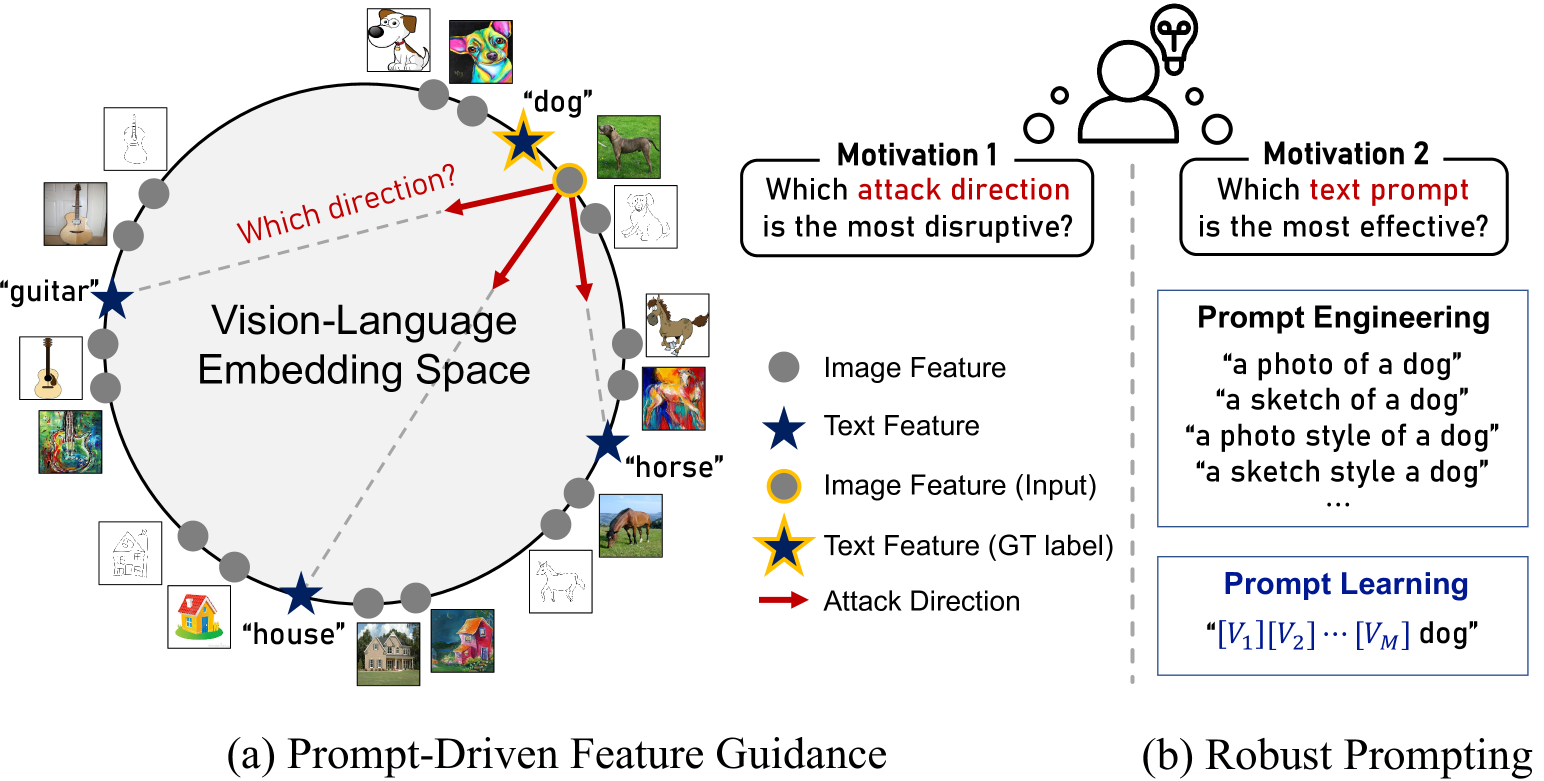
0
Prompt-Driven Contrastive Learning for Transferable Adversarial Attacks
Hunmin Yang, Jongoh Jeong, Kuk-Jin Yoon
Recent vision-language foundation models, such as CLIP, have demonstrated superior capabilities in learning representations that can be transferable across diverse range of downstream tasks and domains. With the emergence of such powerful models, it has become crucial to effectively leverage their capabilities in tackling challenging vision tasks. On the other hand, only a few works have focused on devising adversarial examples that transfer well to both unknown domains and model architectures. In this paper, we propose a novel transfer attack method called PDCL-Attack, which leverages the CLIP model to enhance the transferability of adversarial perturbations generated by a generative model-based attack framework. Specifically, we formulate an effective prompt-driven feature guidance by harnessing the semantic representation power of text, particularly from the ground-truth class labels of input images. To the best of our knowledge, we are the first to introduce prompt learning to enhance the transferable generative attacks. Extensive experiments conducted across various cross-domain and cross-model settings empirically validate our approach, demonstrating its superiority over state-of-the-art methods.
Read more7/31/2024
🤿
0
Adaptive Prompt Learning with Negative Textual Semantics and Uncertainty Modeling for Universal Multi-Source Domain Adaptation
Yuxiang Yang, Lu Wen, Yuanyuan Xu, Jiliu Zhou, Yan Wang
Universal Multi-source Domain Adaptation (UniMDA) transfers knowledge from multiple labeled source domains to an unlabeled target domain under domain shifts (different data distribution) and class shifts (unknown target classes). Existing solutions focus on excavating image features to detect unknown samples, ignoring abundant information contained in textual semantics. In this paper, we propose an Adaptive Prompt learning with Negative textual semantics and uncErtainty modeling method based on Contrastive Language-Image Pre-training (APNE-CLIP) for UniMDA classification tasks. Concretely, we utilize the CLIP with adaptive prompts to leverage textual information of class semantics and domain representations, helping the model identify unknown samples and address domain shifts. Additionally, we design a novel global instance-level alignment objective by utilizing negative textual semantics to achieve more precise image-text pair alignment. Furthermore, we propose an energy-based uncertainty modeling strategy to enlarge the margin distance between known and unknown samples. Extensive experiments demonstrate the superiority of our proposed method.
Read more4/24/2024