Prompt-Driven Contrastive Learning for Transferable Adversarial Attacks

0
Sign in to get full access
Overview
- This paper presents a method called "Prompt-Driven Contrastive Learning" for generating transferable adversarial attacks against vision-language models.
- The approach leverages prompt engineering and contrastive learning to craft adversarial examples that can effectively transfer across different models and tasks.
- Experiments show the proposed method outperforms prior techniques in terms of attack transferability and performance.
Plain English Explanation
The paper introduces a new way to create adversarial attacks that can be used against vision-language models. Adversarial attacks are small, carefully crafted changes to an image or text that can trick an AI model into making mistakes.
The key idea is to use prompt engineering and contrastive learning to generate adversarial examples that can effectively transfer, or be used to attack, different models and tasks. This means the same adversarial example can be used to fool multiple AI systems, not just one.
The researchers show their approach outperforms previous methods at creating these transferable adversarial attacks, which is important for understanding the security and robustness of real-world AI applications.
Technical Explanation
The paper proposes a "Prompt-Driven Contrastive Learning" (PDCL) framework for generating transferable adversarial attacks against vision-language models. The key components are:
-
Prompt Engineering: The researchers craft prompts that guide the adversarial example generation process to produce samples that are visually similar to the original input but semantically different.
-
Contrastive Learning: They use a contrastive learning objective to push the adversarial examples to be dissimilar to the original inputs in the model's latent space, while still maintaining perceptual similarity.
-
Transfer Evaluation: The generated adversarial examples are evaluated for their ability to transfer and fool different vision-language models, not just the one used during training.
Experiments show PDCL outperforms prior transferable attack methods in terms of attack success rate and transfer performance across a range of vision-language benchmarks.
Critical Analysis
The paper provides a novel and effective approach for generating transferable adversarial attacks, which is an important problem for understanding the robustness and security of AI systems. However, a few limitations and potential issues are worth noting:
- The method assumes access to the target model's architecture and training data, which may not always be the case in real-world scenarios.
- The experiments focus on vision-language models, so the generalizability to other model types is unclear.
- The paper does not discuss potential defenses or mitigation strategies against the proposed attack method.
- There could be ethical concerns around the development of more powerful adversarial attack techniques, even if the intent is to improve model robustness.
Overall, the research advances the state-of-the-art in transferable adversarial attacks, but further work is needed to fully understand the implications and practical limitations of the approach.
Conclusion
This paper introduces a novel "Prompt-Driven Contrastive Learning" framework for generating transferable adversarial attacks against vision-language models. The key ideas are to use prompt engineering and contrastive learning to craft adversarial examples that can effectively transfer across different AI systems.
The proposed method outperforms prior techniques, demonstrating the importance of understanding the security and robustness of real-world AI applications. While the research advances the field, there are also important limitations and ethical considerations that warrant further investigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompt-Driven Contrastive Learning for Transferable Adversarial Attacks
Hunmin Yang, Jongoh Jeong, Kuk-Jin Yoon
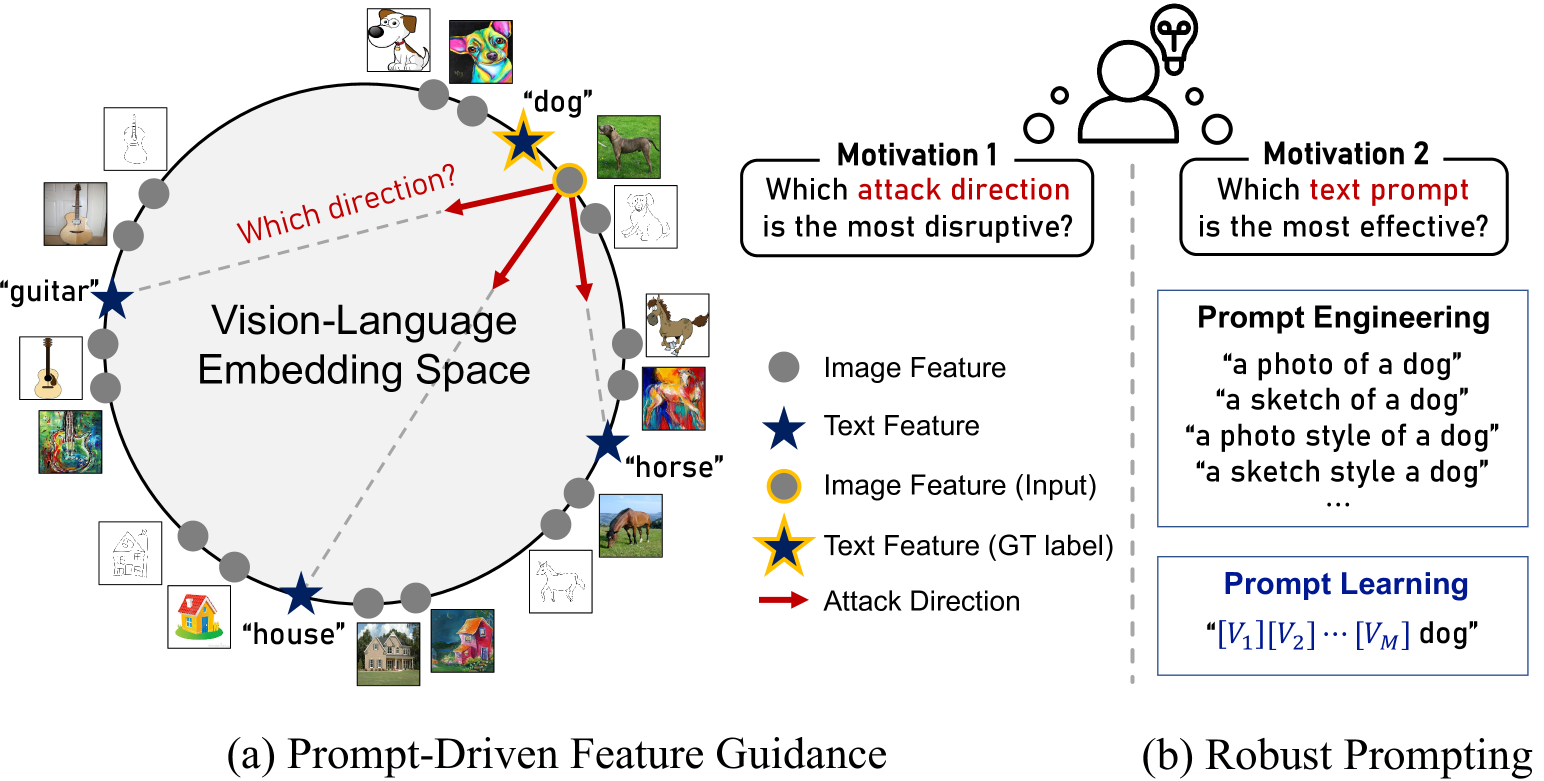
Recent vision-language foundation models, such as CLIP, have demonstrated superior capabilities in learning representations that can be transferable across diverse range of downstream tasks and domains. With the emergence of such powerful models, it has become crucial to effectively leverage their capabilities in tackling challenging vision tasks. On the other hand, only a few works have focused on devising adversarial examples that transfer well to both unknown domains and model architectures. In this paper, we propose a novel transfer attack method called PDCL-Attack, which leverages the CLIP model to enhance the transferability of adversarial perturbations generated by a generative model-based attack framework. Specifically, we formulate an effective prompt-driven feature guidance by harnessing the semantic representation power of text, particularly from the ground-truth class labels of input images. To the best of our knowledge, we are the first to introduce prompt learning to enhance the transferable generative attacks. Extensive experiments conducted across various cross-domain and cross-model settings empirically validate our approach, demonstrating its superiority over state-of-the-art methods.
Read more7/31/2024

0
Revisiting the Robust Generalization of Adversarial Prompt Tuning
Fan Yang, Mingxuan Xia, Sangzhou Xia, Chicheng Ma, Hui Hui
Understanding the vulnerability of large-scale pre-trained vision-language models like CLIP against adversarial attacks is key to ensuring zero-shot generalization capacity on various downstream tasks. State-of-the-art defense mechanisms generally adopt prompt learning strategies for adversarial fine-tuning to improve the adversarial robustness of the pre-trained model while keeping the efficiency of adapting to downstream tasks. Such a setup leads to the problem of over-fitting which impedes further improvement of the model's generalization capacity on both clean and adversarial examples. In this work, we propose an adaptive Consistency-guided Adversarial Prompt Tuning (i.e., CAPT) framework that utilizes multi-modal prompt learning to enhance the alignment of image and text features for adversarial examples and leverage the strong generalization of pre-trained CLIP to guide the model-enhancing its robust generalization on adversarial examples while maintaining its accuracy on clean ones. We also design a novel adaptive consistency objective function to balance the consistency of adversarial inputs and clean inputs between the fine-tuning model and the pre-trained model. We conduct extensive experiments across 14 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show the superiority of CAPT over other state-of-the-art adaption methods. CAPT demonstrated excellent performance in terms of the in-distribution performance and the generalization under input distribution shift and across datasets.
Read more5/21/2024
🌿
0
Adversarial Prompt Tuning for Vision-Language Models
Jiaming Zhang, Xingjun Ma, Xin Wang, Lingyu Qiu, Jiaqi Wang, Yu-Gang Jiang, Jitao Sang
With the rapid advancement of multimodal learning, pre-trained Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capacities in bridging the gap between visual and language modalities. However, these models remain vulnerable to adversarial attacks, particularly in the image modality, presenting considerable security risks. This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in VLMs. AdvPT innovatively leverages learnable text prompts and aligns them with adversarial image embeddings, to address the vulnerabilities inherent in VLMs without the need for extensive parameter training or modification of the model architecture. We demonstrate that AdvPT improves resistance against white-box and black-box adversarial attacks and exhibits a synergistic effect when combined with existing image-processing-based defense techniques, further boosting defensive capabilities. Comprehensive experimental analyses provide insights into adversarial prompt tuning, a novel paradigm devoted to improving resistance to adversarial images through textual input modifications, paving the way for future robust multimodal learning research. These findings open up new possibilities for enhancing the security of VLMs. Our code is available at https://github.com/jiamingzhang94/Adversarial-Prompt-Tuning.
Read more8/20/2024
👁️
0
AD-CLIP: Adapting Domains in Prompt Space Using CLIP
Mainak Singha, Harsh Pal, Ankit Jha, Biplab Banerjee
Although deep learning models have shown impressive performance on supervised learning tasks, they often struggle to generalize well when the training (source) and test (target) domains differ. Unsupervised domain adaptation (DA) has emerged as a popular solution to this problem. However, current DA techniques rely on visual backbones, which may lack semantic richness. Despite the potential of large-scale vision-language foundation models like CLIP, their effectiveness for DA has yet to be fully explored. To address this gap, we introduce textsc{AD-CLIP}, a domain-agnostic prompt learning strategy for CLIP that aims to solve the DA problem in the prompt space. We leverage the frozen vision backbone of CLIP to extract both image style (domain) and content information, which we apply to learn prompt tokens. Our prompts are designed to be domain-invariant and class-generalizable, by conditioning prompt learning on image style and content features simultaneously. We use standard supervised contrastive learning in the source domain, while proposing an entropy minimization strategy to align domains in the embedding space given the target domain data. We also consider a scenario where only target domain samples are available during testing, without any source domain data, and propose a cross-domain style mapping network to hallucinate domain-agnostic tokens. Our extensive experiments on three benchmark DA datasets demonstrate the effectiveness of textsc{AD-CLIP} compared to existing literature. Code is available at url{https://github.com/mainaksingha01/AD-CLIP}
Read more9/17/2024