AdAdaGrad: Adaptive Batch Size Schemes for Adaptive Gradient Methods
2402.11215
0
0
Abstract
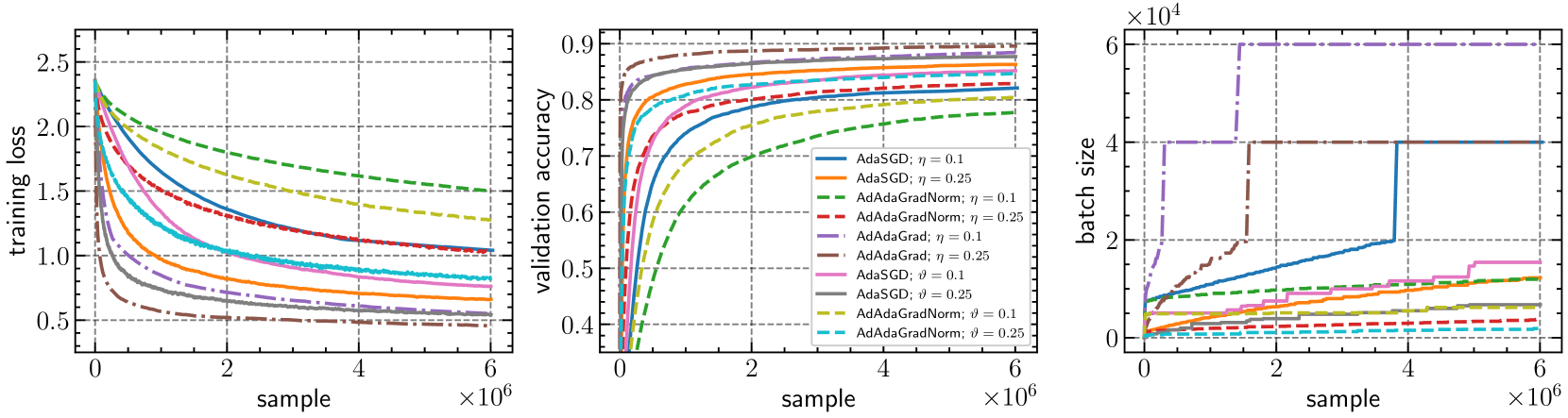
The choice of batch sizes in minibatch stochastic gradient optimizers is critical in large-scale model training for both optimization and generalization performance. Although large-batch training is arguably the dominant training paradigm for large-scale deep learning due to hardware advances, the generalization performance of the model deteriorates compared to small-batch training, leading to the so-called generalization gap phenomenon. To mitigate this, we investigate adaptive batch size strategies derived from adaptive sampling methods, originally developed only for stochastic gradient descent. Given the significant interplay between learning rates and batch sizes, and considering the prevalence of adaptive gradient methods in deep learning, we emphasize the need for adaptive batch size strategies in these contexts. We introduce AdAdaGrad and its scalar variant AdAdaGradNorm, which progressively increase batch sizes during training, while model updates are performed using AdaGrad and AdaGradNorm. We prove that AdAdaGradNorm converges with high probability at a rate of $mathscr{O}(1/K)$ to find a first-order stationary point of smooth nonconvex functions within $K$ iterations. AdAdaGrad also demonstrates similar convergence properties when integrated with a novel coordinate-wise variant of our adaptive batch size strategies. We corroborate our theoretical claims by performing image classification experiments, highlighting the merits of the proposed schemes in terms of both training efficiency and model generalization. Our work unveils the potential of adaptive batch size strategies for adaptive gradient optimizers in large-scale model training.
Create account to get full access
Overview
- This paper introduces a novel adaptive batch size scheme called AdAdaGrad, which aims to improve the performance of adaptive gradient methods in optimization problems.
- The authors demonstrate that AdAdaGrad can outperform existing batch size selection strategies, particularly in scenarios with high noise or curvature in the objective function.
- The paper provides theoretical analyses and empirical evaluations to support the effectiveness of the proposed approach.
Plain English Explanation
The paper discusses a new technique called AdAdaGrad that can help improve the efficiency of optimizing complex machine learning models. Optimization is a key step in training machine learning models, where the goal is to find the best set of parameters that minimize the overall error or "loss" of the model.
Adaptive gradient methods like AdaGrad are popular optimization algorithms that can automatically adjust the learning rate during training to improve convergence. However, these methods also need to choose the batch size, which is the number of training examples used to compute each update. The authors found that setting the batch size adaptively, based on the gradient information, can further boost the performance of these optimization algorithms, particularly in cases where the objective function has a lot of noise or complex curvature.
The key idea behind AdAdaGrad is to use the same adaptive mechanism used to update the learning rate to also update the batch size. This allows the algorithm to automatically adjust both the learning rate and the batch size throughout the training process to better handle the challenges of the optimization landscape. The authors provide theoretical analysis to explain why this approach works, and show through experiments that it can outperform other batch size selection strategies on a variety of machine learning tasks.
Technical Explanation
The paper introduces a new adaptive batch size scheme called AdAdaGrad, which builds upon the popular AdaGrad optimization algorithm. AdaGrad is an adaptive gradient method that adjusts the learning rate for each parameter based on the historical magnitude of the gradients. The authors observed that the choice of batch size can also have a significant impact on the performance of adaptive gradient methods, especially in scenarios with high noise or curvature in the objective function.
To address this, the authors propose AdAdaGrad, which extends AdaGrad to also adapt the batch size during the optimization process. The key idea is to use the same adaptive mechanism used to update the learning rate to also update the batch size. Specifically, the batch size is updated inversely proportional to the root-mean-square (RMS) of the past gradients, similar to how AdaGrad updates the learning rate.
The authors provide a theoretical analysis to show that AdAdaGrad can achieve better convergence guarantees compared to alternative batch size selection strategies, particularly in the presence of high noise or curvature in the objective function. They also demonstrate the empirical effectiveness of AdAdaGrad through experiments on a variety of machine learning tasks, including image classification, language modeling, and reinforcement learning.
Critical Analysis
The paper presents a well-designed and thorough study of the AdAdaGrad algorithm and its performance compared to other batch size selection strategies. The theoretical analysis provides a strong theoretical foundation for the proposed approach, and the experimental results convincingly demonstrate the benefits of AdAdaGrad across a range of machine learning tasks.
One potential limitation of the study is that it focuses primarily on the performance of AdAdaGrad in optimization problems with high noise or curvature. While this is an important and relevant scenario, it would be interesting to see how AdAdaGrad performs in other optimization settings, such as those with different types of objective functions or constraints.
Additionally, the paper does not discuss the computational overhead or practical implementation details of AdAdaGrad, which could be important considerations for real-world applications. Further research could explore the trade-offs between the performance gains and the computational cost of the AdAdaGrad algorithm.
Conclusion
In summary, the AdAdaGrad algorithm presented in this paper represents a promising advancement in adaptive gradient optimization methods. By adapting both the learning rate and the batch size during the optimization process, AdAdaGrad can effectively handle challenges posed by high noise or complex curvature in the objective function, leading to improved convergence and performance on a wide range of machine learning tasks. The theoretical and empirical analyses provided in the paper offer valuable insights and a solid foundation for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Communication-Efficient Adaptive Batch Size Strategies for Distributed Local Gradient Methods
Tim Tsz-Kit Lau, Weijian Li, Chenwei Xu, Han Liu, Mladen Kolar
0
0
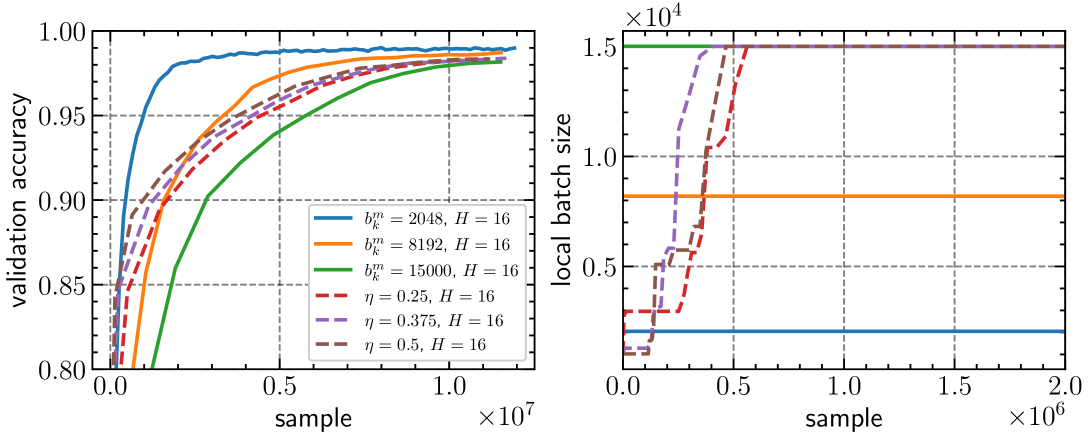
Modern deep neural networks often require distributed training with many workers due to their large size. As worker numbers increase, communication overheads become the main bottleneck in data-parallel minibatch stochastic gradient methods with per-iteration gradient synchronization. Local gradient methods like Local SGD reduce communication by only syncing after several local steps. Despite understanding their convergence in i.i.d. and heterogeneous settings and knowing the importance of batch sizes for efficiency and generalization, optimal local batch sizes are difficult to determine. We introduce adaptive batch size strategies for local gradient methods that increase batch sizes adaptively to reduce minibatch gradient variance. We provide convergence guarantees under homogeneous data conditions and support our claims with image classification experiments, demonstrating the effectiveness of our strategies in training and generalization.
6/21/2024
Large Batch Analysis for Adagrad Under Anisotropic Smoothness
Yuxing Liu, Rui Pan, Tong Zhang
0
0
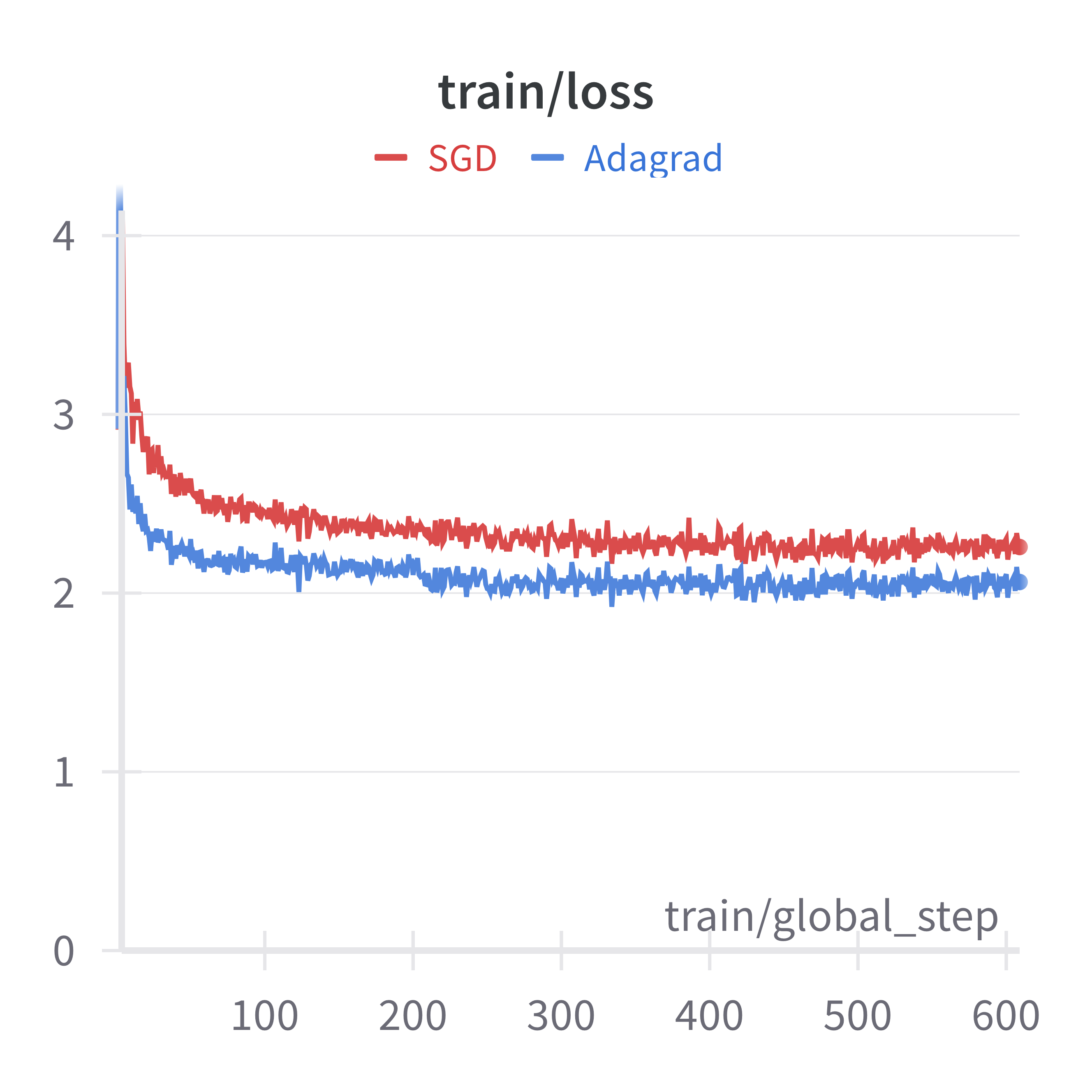
Adaptive gradient algorithms have been widely adopted in training large-scale deep neural networks, especially large foundation models. Despite their huge success in practice, their theoretical advantages over stochastic gradient descent (SGD) have not been fully understood, especially in the large batch-size setting commonly used in practice. This is because the only theoretical result that can demonstrate the benefit of Adagrad over SGD was obtained in the original paper of Adagrad for nonsmooth objective functions. However, for nonsmooth objective functions, there can be a linear slowdown of convergence when batch size increases, and thus a convergence analysis based on nonsmooth assumption cannot be used for large batch algorithms. In this work, we resolve this gap between theory and practice by providing a new analysis of Adagrad on both convex and nonconvex smooth objectives suitable for the large batch setting. It is shown that under the anisotropic smoothness and noise conditions, increased batch size does not slow down convergence for Adagrad, and thus it can still achieve a faster convergence guarantee over SGD even in the large batch setting. We present detailed comparisons between SGD and Adagrad to provide a better understanding of the benefits of adaptive gradient methods. Experiments in logistic regression and instruction following fine-tuning tasks provide strong evidence to support our theoretical analysis.
6/24/2024
🛸
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
Shuaipeng Li, Penghao Zhao, Hailin Zhang, Xingwu Sun, Hao Wu, Dian Jiao, Weiyan Wang, Chengjun Liu, Zheng Fang, Jinbao Xue, Yangyu Tao, Bin Cui, Di Wang
0
0
In current deep learning tasks, Adam style optimizers such as Adam, Adagrad, RMSProp, Adafactor, and Lion have been widely used as alternatives to SGD style optimizers. These optimizers typically update model parameters using the sign of gradients, resulting in more stable convergence curves. The learning rate and the batch size are the most critical hyperparameters for optimizers, which require careful tuning to enable effective convergence. Previous research has shown that the optimal learning rate increases linearly or follows similar rules with batch size for SGD style optimizers. However, this conclusion is not applicable to Adam style optimizers. In this paper, we elucidate the connection between optimal learning rates and batch sizes for Adam style optimizers through both theoretical analysis and extensive experiments. First, we raise the scaling law between batch sizes and optimal learning rates in the sign of gradient case, in which we prove that the optimal learning rate first rises and then falls as the batch size increases. Moreover, the peak value of the surge will gradually move toward the larger batch size as training progresses. Second, we conducted experiments on various CV and NLP tasks and verified the correctness of the scaling law.
6/5/2024
🛠️
Learning rate adaptive stochastic gradient descent optimization methods: numerical simulations for deep learning methods for partial differential equations and convergence analyses
Steffen Dereich, Arnulf Jentzen, Adrian Riekert
0
0
It is known that the standard stochastic gradient descent (SGD) optimization method, as well as accelerated and adaptive SGD optimization methods such as the Adam optimizer fail to converge if the learning rates do not converge to zero (as, for example, in the situation of constant learning rates). Numerical simulations often use human-tuned deterministic learning rate schedules or small constant learning rates. The default learning rate schedules for SGD optimization methods in machine learning implementation frameworks such as TensorFlow and Pytorch are constant learning rates. In this work we propose and study a learning-rate-adaptive approach for SGD optimization methods in which the learning rate is adjusted based on empirical estimates for the values of the objective function of the considered optimization problem (the function that one intends to minimize). In particular, we propose a learning-rate-adaptive variant of the Adam optimizer and implement it in case of several neural network learning problems, particularly, in the context of deep learning approximation methods for partial differential equations such as deep Kolmogorov methods, physics-informed neural networks, and deep Ritz methods. In each of the presented learning problems the proposed learning-rate-adaptive variant of the Adam optimizer faster reduces the value of the objective function than the Adam optimizer with the default learning rate. For a simple class of quadratic minimization problems we also rigorously prove that a learning-rate-adaptive variant of the SGD optimization method converges to the minimizer of the considered minimization problem. Our convergence proof is based on an analysis of the laws of invariant measures of the SGD method as well as on a more general convergence analysis for SGD with random but predictable learning rates which we develop in this work.
6/21/2024