Large Batch Analysis for Adagrad Under Anisotropic Smoothness
2406.15244
0
0
Abstract
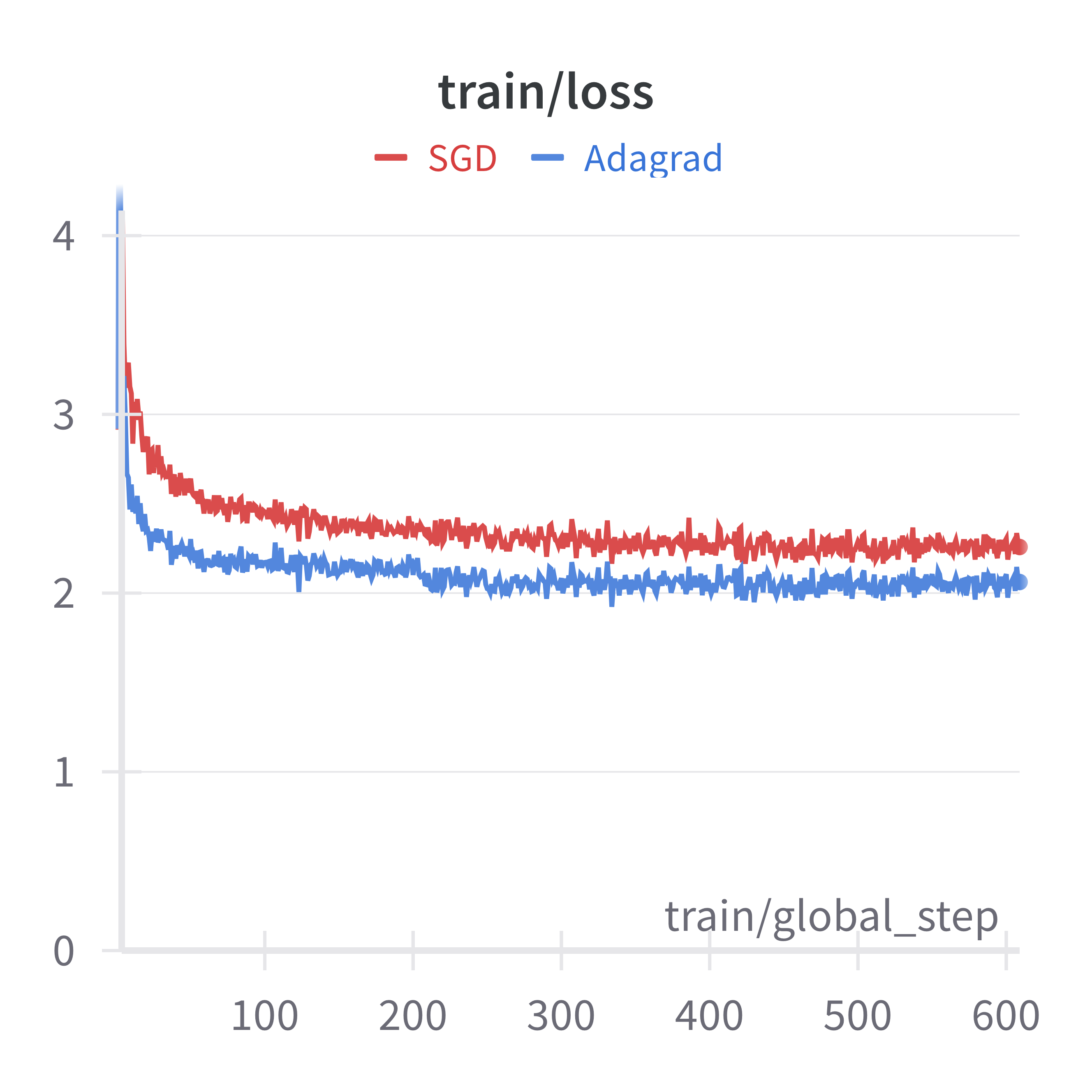
Adaptive gradient algorithms have been widely adopted in training large-scale deep neural networks, especially large foundation models. Despite their huge success in practice, their theoretical advantages over stochastic gradient descent (SGD) have not been fully understood, especially in the large batch-size setting commonly used in practice. This is because the only theoretical result that can demonstrate the benefit of Adagrad over SGD was obtained in the original paper of Adagrad for nonsmooth objective functions. However, for nonsmooth objective functions, there can be a linear slowdown of convergence when batch size increases, and thus a convergence analysis based on nonsmooth assumption cannot be used for large batch algorithms. In this work, we resolve this gap between theory and practice by providing a new analysis of Adagrad on both convex and nonconvex smooth objectives suitable for the large batch setting. It is shown that under the anisotropic smoothness and noise conditions, increased batch size does not slow down convergence for Adagrad, and thus it can still achieve a faster convergence guarantee over SGD even in the large batch setting. We present detailed comparisons between SGD and Adagrad to provide a better understanding of the benefits of adaptive gradient methods. Experiments in logistic regression and instruction following fine-tuning tasks provide strong evidence to support our theoretical analysis.
Create account to get full access
Overview
- This paper analyzes the performance of the Adagrad optimization algorithm under the assumption of anisotropic smoothness, which means the function being optimized has different levels of smoothness in different directions.
- The authors show that Adagrad can achieve optimal convergence rates in this setting, outperforming other adaptive gradient algorithms like AdaGrad and Adam.
- The paper also provides new theoretical insights into the behavior of Adagrad and develops a new analysis framework for studying adaptive gradient methods under anisotropic smoothness.
Plain English Explanation
Optimization algorithms like Adagrad are used to train machine learning models by adjusting the model parameters to minimize a loss function. The function being optimized often has different levels of "smoothness" in different directions, meaning it changes more rapidly in some directions than others. This is known as anisotropic smoothness.
The authors of this paper show that Adagrad, a popular adaptive gradient algorithm, can perform very well in this anisotropic setting. Adaptive algorithms like Adagrad and Adam adjust their updates based on the historical gradients, which can help them converge faster than simpler algorithms like gradient descent.
The key insight is that Adagrad's ability to adapt its updates based on the geometry of the function can actually help it converge optimally in the anisotropic setting, outperforming other adaptive methods. The authors develop a new theoretical framework for analyzing this behavior, providing important insights into how Adagrad and other adaptive algorithms work.
Technical Explanation
The paper studies the convergence of the Adagrad optimization algorithm under the assumption of anisotropic smoothness. Anisotropic smoothness means that the function being optimized has different levels of smoothness (how quickly it changes) in different directions.
The authors show that Adagrad can achieve an optimal convergence rate in this setting, matching the performance of the idealized "oracle" algorithm that knows the function's smoothness in advance. This outperforms other adaptive gradient methods like AdaGrad and Adam, which do not adapt as effectively to the anisotropic structure.
Theoretically, the authors develop a new framework for analyzing adaptive gradient methods under anisotropic smoothness. This involves carefully bounding the algorithm's progress in different directions based on the local geometry of the function. The analysis reveals how Adagrad's adaptive updates allow it to take advantage of the anisotropic structure, leading to the optimal convergence guarantee.
Critical Analysis
The paper provides strong theoretical support for the effectiveness of Adagrad in settings with anisotropic smoothness. The analysis is technically sophisticated and the results are quite compelling, showing Adagrad can outperform other well-known adaptive methods.
However, the paper does not explore the practical implications or empirical performance of Adagrad in real-world machine learning tasks with anisotropic functions. While the theory is valuable, it would be helpful to see how the algorithms perform on relevant benchmarks or applications.
Additionally, the paper focuses solely on the convergence of the optimization algorithms, without considering other important factors like the final solution quality or computational efficiency. Real-world practitioners may be interested in a more holistic evaluation of the algorithms' strengths and weaknesses.
Further research could investigate the robustness of Adagrad's performance to modeling assumptions, extend the analysis to other adaptive methods, or explore the tradeoffs between different optimization algorithms in more depth. Overall, this paper makes an important theoretical contribution, but additional empirical and practical insights would help bridge the gap to real-world machine learning problems.
Conclusion
This paper presents a detailed analysis of the Adagrad optimization algorithm under the assumption of anisotropic smoothness. The authors show that Adagrad can achieve optimal convergence rates in this setting, outperforming other adaptive gradient methods like AdaGrad and Adam.
The key technical contribution is a new analytical framework for studying adaptive gradient algorithms under anisotropic smoothness. This framework reveals how Adagrad's adaptive updates allow it to effectively exploit the geometric structure of the optimization problem, leading to its strong theoretical performance.
While the paper focuses on the theoretical analysis, the results suggest Adagrad may be a particularly well-suited algorithm for real-world machine learning tasks with functions exhibiting anisotropic smoothness. Further empirical evaluation and practical insights could help solidify Adagrad's position as a leading optimization method for a wider range of machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
AdAdaGrad: Adaptive Batch Size Schemes for Adaptive Gradient Methods
Tim Tsz-Kit Lau, Han Liu, Mladen Kolar
0
0
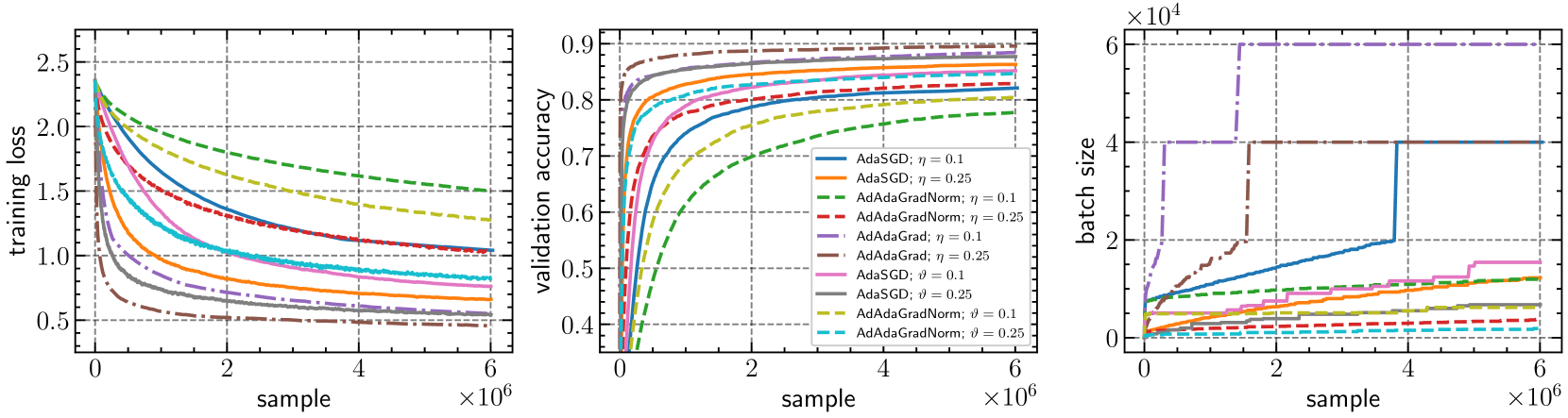
The choice of batch sizes in minibatch stochastic gradient optimizers is critical in large-scale model training for both optimization and generalization performance. Although large-batch training is arguably the dominant training paradigm for large-scale deep learning due to hardware advances, the generalization performance of the model deteriorates compared to small-batch training, leading to the so-called generalization gap phenomenon. To mitigate this, we investigate adaptive batch size strategies derived from adaptive sampling methods, originally developed only for stochastic gradient descent. Given the significant interplay between learning rates and batch sizes, and considering the prevalence of adaptive gradient methods in deep learning, we emphasize the need for adaptive batch size strategies in these contexts. We introduce AdAdaGrad and its scalar variant AdAdaGradNorm, which progressively increase batch sizes during training, while model updates are performed using AdaGrad and AdaGradNorm. We prove that AdAdaGradNorm converges with high probability at a rate of $mathscr{O}(1/K)$ to find a first-order stationary point of smooth nonconvex functions within $K$ iterations. AdAdaGrad also demonstrates similar convergence properties when integrated with a novel coordinate-wise variant of our adaptive batch size strategies. We corroborate our theoretical claims by performing image classification experiments, highlighting the merits of the proposed schemes in terms of both training efficiency and model generalization. Our work unveils the potential of adaptive batch size strategies for adaptive gradient optimizers in large-scale model training.
5/29/2024
🔗
Convergence Analysis of Adaptive Gradient Methods under Refined Smoothness and Noise Assumptions
Devyani Maladkar, Ruichen Jiang, Aryan Mokhtari
0
0
Adaptive gradient methods are arguably the most successful optimization algorithms for neural network training. While it is well-known that adaptive gradient methods can achieve better dimensional dependence than stochastic gradient descent (SGD) under favorable geometry for stochastic convex optimization, the theoretical justification for their success in stochastic non-convex optimization remains elusive. In this paper, we aim to close this gap by analyzing the convergence rates of AdaGrad measured by the $ell_1$-norm of the gradient. Specifically, when the objective has $L$-Lipschitz gradient and the stochastic gradient variance is bounded by $sigma^2$, we prove a worst-case convergence rate of $tilde{mathcal{O}}(frac{sqrt{d}L}{sqrt{T}} + frac{sqrt{d} sigma}{T^{1/4}})$, where $d$ is the dimension of the problem.We also present a lower bound of ${Omega}(frac{sqrt{d}}{sqrt{T}})$ for minimizing the gradient $ell_1$-norm in the deterministic setting, showing the tightness of our upper bound in the noiseless case. Moreover, under more fine-grained assumptions on the smoothness structure of the objective and the gradient noise and under favorable gradient $ell_1/ell_2$ geometry, we show that AdaGrad can potentially shave a factor of $sqrt{d}$ compared to SGD. To the best of our knowledge, this is the first result for adaptive gradient methods that demonstrates a provable gain over SGD in the non-convex setting.
6/10/2024
🛠️
On the Convergence of Adaptive Gradient Methods for Nonconvex Optimization
Dongruo Zhou, Jinghui Chen, Yuan Cao, Ziyan Yang, Quanquan Gu
0
0
Adaptive gradient methods are workhorses in deep learning. However, the convergence guarantees of adaptive gradient methods for nonconvex optimization have not been thoroughly studied. In this paper, we provide a fine-grained convergence analysis for a general class of adaptive gradient methods including AMSGrad, RMSProp and AdaGrad. For smooth nonconvex functions, we prove that adaptive gradient methods in expectation converge to a first-order stationary point. Our convergence rate is better than existing results for adaptive gradient methods in terms of dimension. In addition, we also prove high probability bounds on the convergence rates of AMSGrad, RMSProp as well as AdaGrad, which have not been established before. Our analyses shed light on better understanding the mechanism behind adaptive gradient methods in optimizing nonconvex objectives.
6/21/2024
Random Scaling and Momentum for Non-smooth Non-convex Optimization
Qinzi Zhang, Ashok Cutkosky
0
0
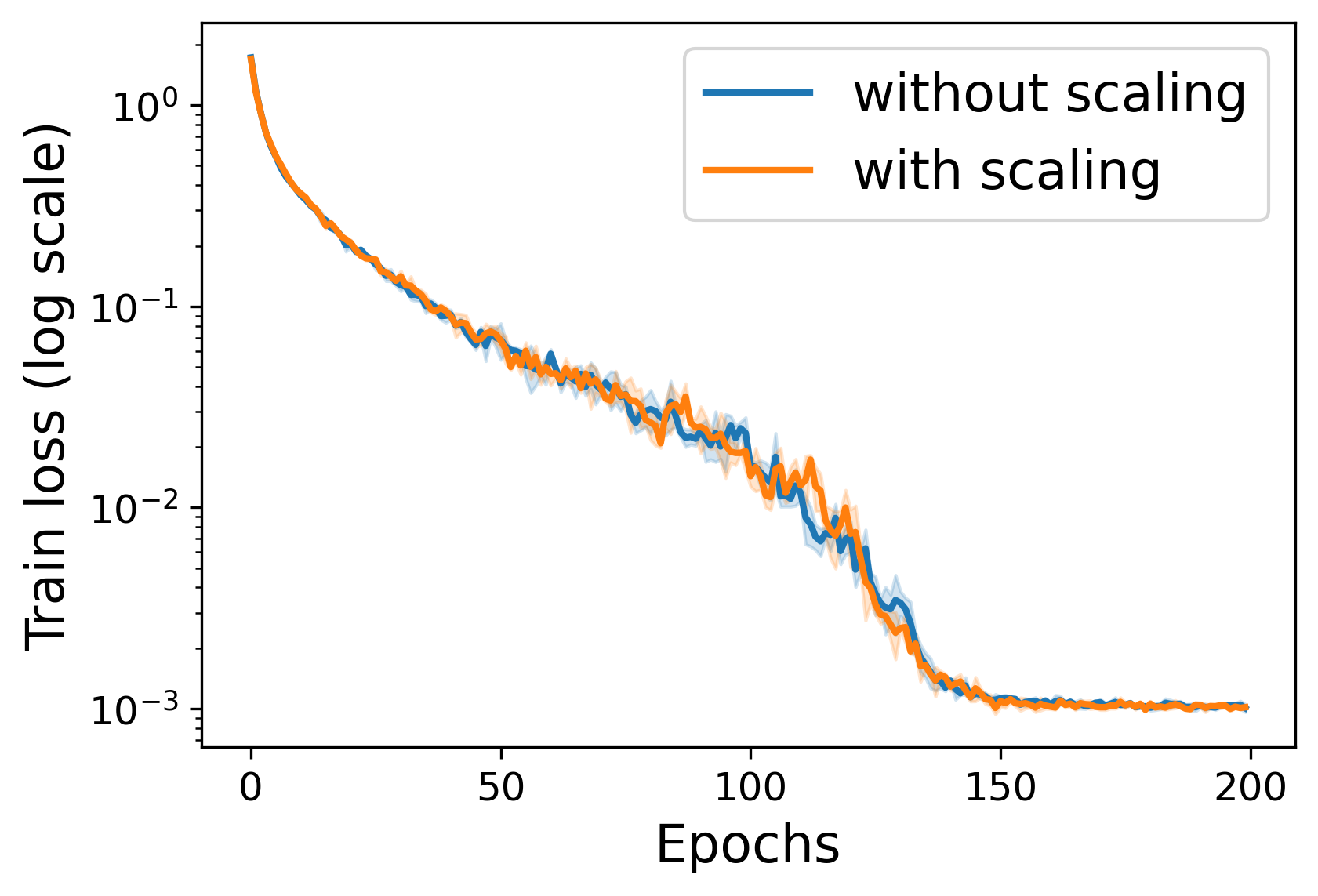
Training neural networks requires optimizing a loss function that may be highly irregular, and in particular neither convex nor smooth. Popular training algorithms are based on stochastic gradient descent with momentum (SGDM), for which classical analysis applies only if the loss is either convex or smooth. We show that a very small modification to SGDM closes this gap: simply scale the update at each time point by an exponentially distributed random scalar. The resulting algorithm achieves optimal convergence guarantees. Intriguingly, this result is not derived by a specific analysis of SGDM: instead, it falls naturally out of a more general framework for converting online convex optimization algorithms to non-convex optimization algorithms.
5/17/2024