Communication-Efficient Adaptive Batch Size Strategies for Distributed Local Gradient Methods
2406.13936
0
0
Abstract
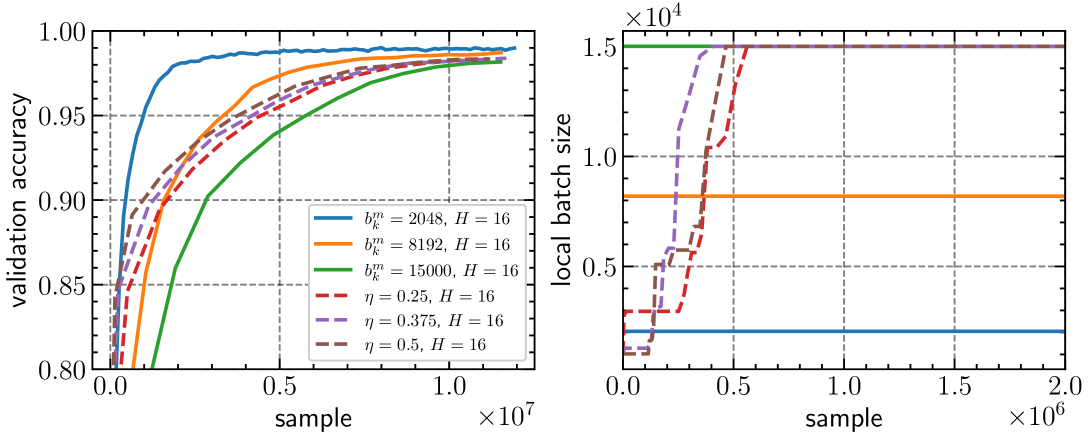
Modern deep neural networks often require distributed training with many workers due to their large size. As worker numbers increase, communication overheads become the main bottleneck in data-parallel minibatch stochastic gradient methods with per-iteration gradient synchronization. Local gradient methods like Local SGD reduce communication by only syncing after several local steps. Despite understanding their convergence in i.i.d. and heterogeneous settings and knowing the importance of batch sizes for efficiency and generalization, optimal local batch sizes are difficult to determine. We introduce adaptive batch size strategies for local gradient methods that increase batch sizes adaptively to reduce minibatch gradient variance. We provide convergence guarantees under homogeneous data conditions and support our claims with image classification experiments, demonstrating the effectiveness of our strategies in training and generalization.
Create account to get full access
Overview
- This paper proposes new communication-efficient adaptive batch size strategies for distributed local gradient methods in machine learning.
- The strategies aim to improve the convergence rate and reduce communication costs by dynamically adjusting the batch size during the optimization process.
- The paper builds on prior research on adaptive gradient methods and local methods with adaptivity via scaling.
Plain English Explanation
Machine learning models are often trained on massive datasets that are distributed across multiple computers. To make this training process more efficient, researchers have developed distributed optimization algorithms that split the work across the computers. One key challenge is minimizing the amount of communication required between the computers, as this communication can be slow and costly.
This paper introduces new strategies to dynamically adjust the batch size - the number of training examples processed at once - during the optimization process. By adaptively changing the batch size, the algorithms can achieve faster convergence to the optimal model while also reducing the overall communication required.
The core idea is to use information about the gradients (the direction the model needs to change to improve performance) to decide how large the batch size should be. When the gradients are small, the algorithm can use a larger batch size to make more progress per communication round. When the gradients are large, a smaller batch size is used to get more accurate updates. This adaptive batch size approach builds on prior work on adaptive gradient methods and local methods with adaptivity via scaling.
By dynamically adjusting the batch size, the algorithms can achieve improved convergence rates and significantly reduce the amount of communication required, making distributed machine learning more efficient.
Technical Explanation
The paper introduces two new communication-efficient adaptive batch size strategies for distributed local gradient methods:
-
Adaptive Batch Size via Gradient Scaling (ABS-GS): This strategy uses information about the scaling of the gradients to adaptively change the batch size. When the gradients are large, a smaller batch size is used to get more accurate updates. When the gradients are small, a larger batch size can be used to make more progress per communication round.
-
Adaptive Batch Size via Gradient Norm (ABS-GN): This strategy directly uses the norm (magnitude) of the gradients to determine the batch size. A larger gradient norm indicates that a smaller batch size is needed, while a smaller gradient norm allows for a larger batch size.
The paper provides theoretical analysis to show that these adaptive batch size strategies can achieve improved convergence rates compared to using a fixed batch size. The strategies build on prior work on limits and potentials of local SGD in distributed heterogeneous learning, communication-efficient distributed learning via sparse adaptive gradients, and communication-efficient gradient descent with ACCENT methods.
The paper also includes extensive experimental evaluations on both synthetic and real-world datasets, demonstrating the effectiveness of the proposed strategies in terms of convergence rate and communication efficiency.
Critical Analysis
The paper presents a well-designed and thorough study of the proposed adaptive batch size strategies. The theoretical analysis provides a strong foundation for understanding the convergence properties of the algorithms, and the experimental results convincingly demonstrate their practical benefits.
One potential limitation is that the analysis and experiments assume a relatively simple distributed learning setting with i.i.d. data distributions across the nodes. In real-world scenarios, the data distributions may be more heterogeneous, which could pose additional challenges. Further research may be needed to understand the performance of these strategies in more complex distributed learning scenarios.
Additionally, the paper does not explore the sensitivity of the algorithms to hyperparameter choices, such as the initial batch size or the scaling factors used in the adaptive strategies. Understanding the robustness of the algorithms to these hyperparameters would be valuable for practical implementation.
Overall, the paper makes a significant contribution to the field of communication-efficient distributed learning by introducing novel and effective adaptive batch size strategies. The research provides a solid foundation for further improvements and adaptations to more diverse distributed learning settings.
Conclusion
This paper presents two new communication-efficient adaptive batch size strategies for distributed local gradient methods in machine learning. By dynamically adjusting the batch size based on gradient information, the proposed algorithms can achieve improved convergence rates while significantly reducing the overall communication required between distributed nodes.
The theoretical analysis and extensive experimental evaluations demonstrate the effectiveness of these strategies, which build on prior work in adaptive gradient methods and local methods with adaptivity. While the paper focuses on a relatively simple distributed learning setting, the core ideas and techniques could be further extended to address more complex scenarios, potentially leading to even greater efficiency gains in large-scale distributed machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
AdAdaGrad: Adaptive Batch Size Schemes for Adaptive Gradient Methods
Tim Tsz-Kit Lau, Han Liu, Mladen Kolar
0
0
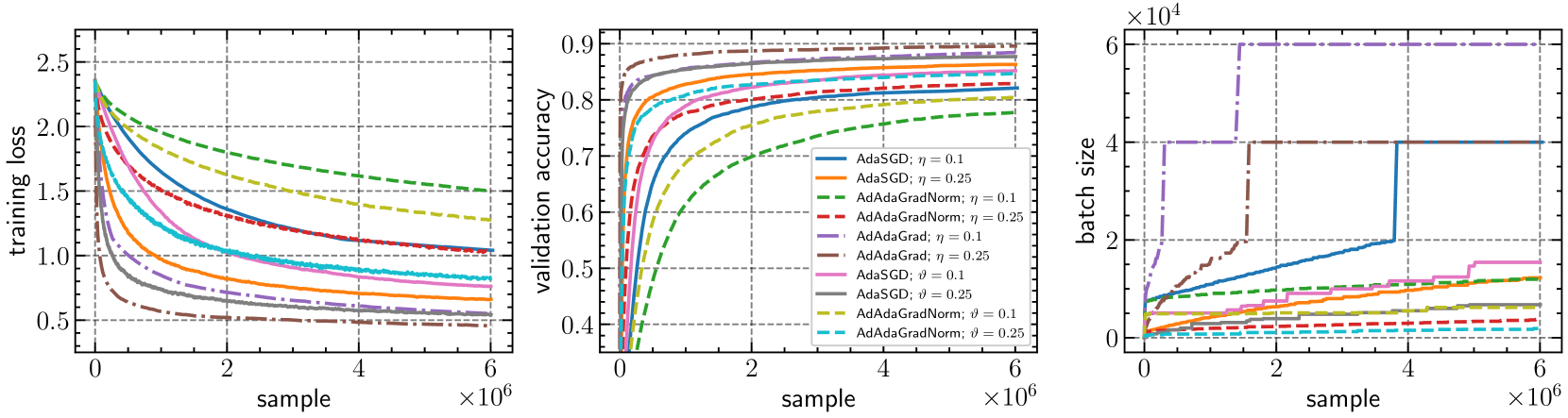
The choice of batch sizes in minibatch stochastic gradient optimizers is critical in large-scale model training for both optimization and generalization performance. Although large-batch training is arguably the dominant training paradigm for large-scale deep learning due to hardware advances, the generalization performance of the model deteriorates compared to small-batch training, leading to the so-called generalization gap phenomenon. To mitigate this, we investigate adaptive batch size strategies derived from adaptive sampling methods, originally developed only for stochastic gradient descent. Given the significant interplay between learning rates and batch sizes, and considering the prevalence of adaptive gradient methods in deep learning, we emphasize the need for adaptive batch size strategies in these contexts. We introduce AdAdaGrad and its scalar variant AdAdaGradNorm, which progressively increase batch sizes during training, while model updates are performed using AdaGrad and AdaGradNorm. We prove that AdAdaGradNorm converges with high probability at a rate of $mathscr{O}(1/K)$ to find a first-order stationary point of smooth nonconvex functions within $K$ iterations. AdAdaGrad also demonstrates similar convergence properties when integrated with a novel coordinate-wise variant of our adaptive batch size strategies. We corroborate our theoretical claims by performing image classification experiments, highlighting the merits of the proposed schemes in terms of both training efficiency and model generalization. Our work unveils the potential of adaptive batch size strategies for adaptive gradient optimizers in large-scale model training.
5/29/2024
Local Methods with Adaptivity via Scaling
Savelii Chezhegov, Sergey Skorik, Nikolas Khachaturov, Danil Shalagin, Aram Avetisyan, Aleksandr Beznosikov, Martin Tak'av{c}, Yaroslav Kholodov, Alexander Gasnikov
0
0
The rapid development of machine learning and deep learning has introduced increasingly complex optimization challenges that must be addressed. Indeed, training modern, advanced models has become difficult to implement without leveraging multiple computing nodes in a distributed environment. Distributed optimization is also fundamental to emerging fields such as federated learning. Specifically, there is a need to organize the training process to minimize the time lost due to communication. A widely used and extensively researched technique to mitigate the communication bottleneck involves performing local training before communication. This approach is the focus of our paper. Concurrently, adaptive methods that incorporate scaling, notably led by Adam, have gained significant popularity in recent years. Therefore, this paper aims to merge the local training technique with the adaptive approach to develop efficient distributed learning methods. We consider the classical Local SGD method and enhance it with a scaling feature. A crucial aspect is that the scaling is described generically, allowing us to analyze various approaches, including Adam, RMSProp, and OASIS, in a unified manner. In addition to theoretical analysis, we validate the performance of our methods in practice by training a neural network.
6/14/2024

The Limits and Potentials of Local SGD for Distributed Heterogeneous Learning with Intermittent Communication
Kumar Kshitij Patel, Margalit Glasgow, Ali Zindari, Lingxiao Wang, Sebastian U. Stich, Ziheng Cheng, Nirmit Joshi, Nathan Srebro
0
0
Local SGD is a popular optimization method in distributed learning, often outperforming other algorithms in practice, including mini-batch SGD. Despite this success, theoretically proving the dominance of local SGD in settings with reasonable data heterogeneity has been difficult, creating a significant gap between theory and practice. In this paper, we provide new lower bounds for local SGD under existing first-order data heterogeneity assumptions, showing that these assumptions are insufficient to prove the effectiveness of local update steps. Furthermore, under these same assumptions, we demonstrate the min-max optimality of accelerated mini-batch SGD, which fully resolves our understanding of distributed optimization for several problem classes. Our results emphasize the need for better models of data heterogeneity to understand the effectiveness of local SGD in practice. Towards this end, we consider higher-order smoothness and heterogeneity assumptions, providing new upper bounds that imply the dominance of local SGD over mini-batch SGD when data heterogeneity is low.
5/21/2024
🧠
SASG: Sparse Communication with Adaptive Aggregated Stochastic Gradients for Distributed Learning
Xiaoge Deng, Dongsheng Li, Tao Sun, Xicheng Lu
0
0
Gradient-based optimization methods implemented on distributed computing architectures are increasingly used to tackle large-scale machine learning applications. A key bottleneck in such distributed systems is the high communication overhead for exchanging information, such as stochastic gradients, between workers. The inherent causes of this bottleneck are the frequent communication rounds and the full model gradient transmission in every round. In this study, we present SASG, a communication-efficient distributed algorithm that enjoys the advantages of sparse communication and adaptive aggregated stochastic gradients. By dynamically determining the workers who need to communicate through an adaptive aggregation rule and sparsifying the transmitted information, the SASG algorithm reduces both the overhead of communication rounds and the number of communication bits in the distributed system. For the theoretical analysis, we introduce an important auxiliary variable and define a new Lyapunov function to prove that the communication-efficient algorithm is convergent. The convergence result is identical to the sublinear rate of stochastic gradient descent, and our result also reveals that SASG scales well with the number of distributed workers. Finally, experiments on training deep neural networks demonstrate that the proposed algorithm can significantly reduce communication overhead compared to previous methods.
6/11/2024