AdaFisher: Adaptive Second Order Optimization via Fisher Information
2405.16397
0
0

Abstract
First-order optimization methods are currently the mainstream in training deep neural networks (DNNs). Optimizers like Adam incorporate limited curvature information by employing the diagonal matrix preconditioning of the stochastic gradient during the training. Despite their widespread, second-order optimization algorithms exhibit superior convergence properties compared to their first-order counterparts e.g. Adam and SGD. However, their practicality in training DNNs are still limited due to increased per-iteration computations and suboptimal accuracy compared to the first order methods. We present AdaFisher--an adaptive second-order optimizer that leverages a block-diagonal approximation to the Fisher information matrix for adaptive gradient preconditioning. AdaFisher aims to bridge the gap between enhanced convergence capabilities and computational efficiency in second-order optimization framework for training DNNs. Despite the slow pace of second-order optimizers, we showcase that AdaFisher can be reliably adopted for image classification, language modelling and stand out for its stability and robustness in hyperparameter tuning. We demonstrate that AdaFisher outperforms the SOTA optimizers in terms of both accuracy and convergence speed. Code available from href{https://github.com/AtlasAnalyticsLab/AdaFisher}{https://github.com/AtlasAnalyticsLab/AdaFisher}
Create account to get full access
Overview
- This paper introduces a new optimization algorithm called FADAM, which is a natural gradient optimizer that builds on the popular Adam algorithm.
- The researchers claim that FADAM outperforms Adam and other state-of-the-art optimizers on a range of machine learning tasks.
- The paper also provides theoretical insights into the behavior of adaptive optimizers like Adam and FADAM.
Plain English Explanation
The paper introduces a new optimization algorithm called FADAM, which is an improvement on the widely used Adam algorithm. Optimizers are a crucial component of machine learning models, as they help find the best set of model parameters during the training process.
The key idea behind FADAM is that it uses the concept of natural gradient to update the model parameters. This means that FADAM takes into account the underlying geometry of the optimization problem, which can lead to faster convergence and better performance compared to simpler gradient-based methods like Adam.
The researchers show that FADAM outperforms Adam and other state-of-the-art optimizers on a variety of machine learning tasks, including image classification and natural language processing. They also provide theoretical analysis to explain why FADAM is effective, drawing insights from the field of signal processing and the properties of the Fisher information matrix.
Overall, this paper presents a promising new optimization algorithm that could have a significant impact on the development of more efficient and effective machine learning models.
Technical Explanation
The paper introduces a new optimization algorithm called FADAM, which is a natural gradient variant of the popular Adam optimizer. The key idea behind FADAM is to use the Fisher information matrix to capture the underlying geometry of the optimization problem, rather than relying on just the gradients as in standard Adam.
The researchers derive the FADAM update rule and show that it can be efficiently computed by maintaining running estimates of the gradient and the Fisher information matrix. They also provide theoretical analysis to explain the behavior of FADAM, drawing connections to the signal processing literature and the properties of the Fisher information matrix.
Through extensive experiments on a range of machine learning tasks, the authors demonstrate that FADAM outperforms Adam and other state-of-the-art optimizers in terms of convergence speed and final performance. They attribute this to FADAM's ability to effectively adapt to the curvature of the optimization landscape, which leads to more efficient updates and better exploration of the parameter space.
Critical Analysis
The paper presents a well-designed and thorough study of the FADAM optimizer, with a strong theoretical foundation and extensive empirical evaluation. However, there are a few potential limitations and areas for further research:
-
The paper focuses on comparing FADAM to other first-order optimizers like Adam, but it would be interesting to see how it performs against more advanced second-order methods, such as KFAC or SVRG.
-
The analysis of the Fisher information matrix in the paper is based on the assumption of a diagonal structure, which may not always hold in practice. It would be valuable to explore the performance of FADAM with more general Fisher information matrix estimates.
-
The paper does not address the computational and memory overhead of maintaining the Fisher information matrix, which could be a concern for large-scale or real-time applications. Further research is needed to understand the trade-offs between the benefits of FADAM and its computational requirements.
Overall, the paper makes a significant contribution to the literature on adaptive optimization algorithms and provides a promising new tool for improving the training of machine learning models. However, as with any research, there are opportunities for further investigation and refinement of the proposed approach.
Conclusion
This paper introduces a new optimization algorithm called FADAM, which is a natural gradient variant of the popular Adam optimizer. The key idea behind FADAM is to use the Fisher information matrix to capture the underlying geometry of the optimization problem, leading to more efficient updates and better performance compared to standard Adam.
Through both theoretical analysis and extensive empirical evaluation, the researchers demonstrate that FADAM outperforms Adam and other state-of-the-art optimizers on a range of machine learning tasks. This work provides valuable insights into the behavior of adaptive optimizers and suggests that incorporating natural gradient information can be a promising direction for improving the training of machine learning models.
The paper's contributions have the potential to impact a wide range of applications that rely on efficient and effective optimization algorithms, from computer vision and natural language processing to reinforcement learning and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
FAdam: Adam is a natural gradient optimizer using diagonal empirical Fisher information
Dongseong Hwang
0
0
This paper establishes a mathematical foundation for the Adam optimizer, elucidating its connection to natural gradient descent through Riemannian and information geometry. We rigorously analyze the diagonal empirical Fisher information matrix (FIM) in Adam, clarifying all detailed approximations and advocating for the use of log probability functions as loss, which should be based on discrete distributions, due to the limitations of empirical FIM. Our analysis uncovers flaws in the original Adam algorithm, leading to proposed corrections such as enhanced momentum calculations, adjusted bias corrections, adaptive epsilon, and gradient clipping. We refine the weight decay term based on our theoretical framework. Our modified algorithm, Fisher Adam (FAdam), demonstrates superior performance across diverse domains including LLM, ASR, and VQ-VAE, achieving state-of-the-art results in ASR.
6/4/2024

Can We Remove the Square-Root in Adaptive Gradient Methods? A Second-Order Perspective
Wu Lin, Felix Dangel, Runa Eschenhagen, Juhan Bae, Richard E. Turner, Alireza Makhzani
0
0
Adaptive gradient optimizers like Adam(W) are the default training algorithms for many deep learning architectures, such as transformers. Their diagonal preconditioner is based on the gradient outer product which is incorporated into the parameter update via a square root. While these methods are often motivated as approximate second-order methods, the square root represents a fundamental difference. In this work, we investigate how the behavior of adaptive methods changes when we remove the root, i.e. strengthen their second-order motivation. Surprisingly, we find that such square-root-free adaptive methods close the generalization gap to SGD on convolutional architectures, while maintaining their root-based counterpart's performance on transformers. The second-order perspective also has practical benefits for developing non-diagonal adaptive methods through the concept of preconditioner invariance. In contrast to root-based methods like Shampoo, root-free counterparts work well and fast with half-precision since they do not require numerically unstable matrix root decompositions and inversions. This is useful to bridge the computation gap between diagonal and non-diagonal methods. Our findings provide new insights into the development of adaptive methods and raise important questions regarding the currently overlooked role of adaptivity for their success. (experiment code: https://github.com/yorkerlin/remove-the-square-root optimizer code: https://github.com/f-dangel/sirfshampoo)
6/18/2024
🗣️
Studying K-FAC Heuristics by Viewing Adam through a Second-Order Lens
Ross M. Clarke, Jos'e Miguel Hern'andez-Lobato
0
0
Research into optimisation for deep learning is characterised by a tension between the computational efficiency of first-order, gradient-based methods (such as SGD and Adam) and the theoretical efficiency of second-order, curvature-based methods (such as quasi-Newton methods and K-FAC). Noting that second-order methods often only function effectively with the addition of stabilising heuristics (such as Levenberg-Marquardt damping), we ask how much these (as opposed to the second-order curvature model) contribute to second-order algorithms' performance. We thus study AdamQLR: an optimiser combining damping and learning rate selection techniques from K-FAC (Martens & Grosse, 2015) with the update directions proposed by Adam, inspired by considering Adam through a second-order lens. We evaluate AdamQLR on a range of regression and classification tasks at various scales and hyperparameter tuning methodologies, concluding K-FAC's adaptive heuristics are of variable standalone general effectiveness, and finding an untuned AdamQLR setting can achieve comparable performance vs runtime to tuned benchmarks.
6/17/2024
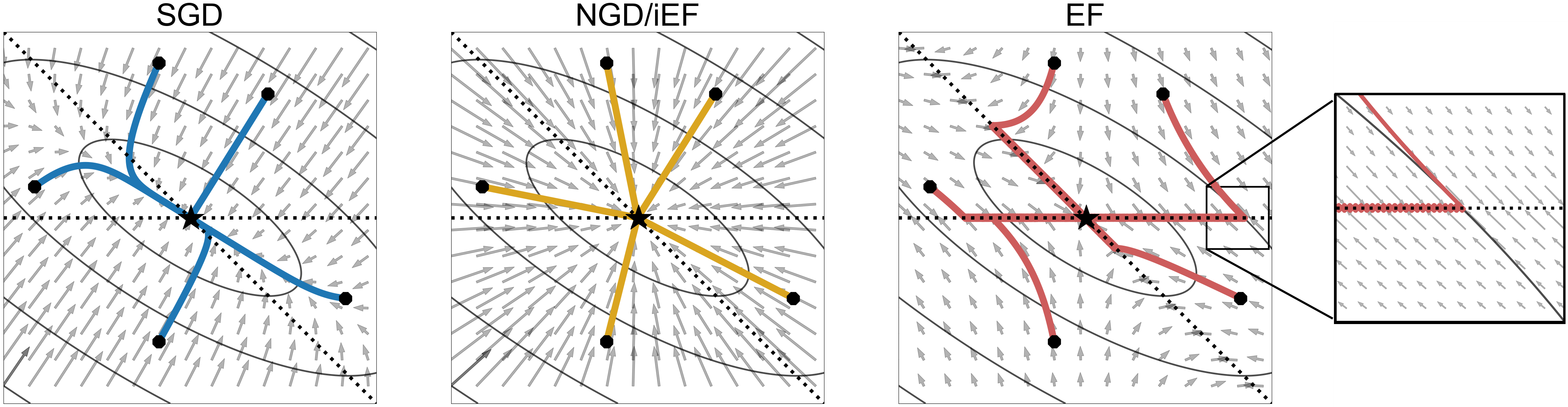
An Improved Empirical Fisher Approximation for Natural Gradient Descent
Xiaodong Wu, Wenyi Yu, Chao Zhang, Philip Woodland
0
0
Approximate Natural Gradient Descent (NGD) methods are an important family of optimisers for deep learning models, which use approximate Fisher information matrices to pre-condition gradients during training. The empirical Fisher (EF) method approximates the Fisher information matrix empirically by reusing the per-sample gradients collected during back-propagation. Despite its ease of implementation, the EF approximation has its theoretical and practical limitations. This paper first investigates the inversely-scaled projection issue of EF, which is shown to be a major cause of the poor empirical approximation quality. An improved empirical Fisher (iEF) method, motivated as a generalised NGD method from a loss reduction perspective, is proposed to address this issue, meanwhile retaining the practical convenience of EF. The exact iEF and EF methods are experimentally evaluated using practical deep learning setups, including widely-used setups for parameter-efficient fine-tuning of pre-trained models (T5-base with LoRA and Prompt-Tuning on GLUE tasks, and ViT with LoRA for CIFAR100). Optimisation experiments show that applying exact iEF as an optimiser provides strong convergence and generalisation. It achieves the best test performance and the lowest training loss for majority of the tasks, even when compared with well-tuned AdamW/Adafactor baselines. Additionally, under a novel empirical evaluation framework, the proposed iEF method shows consistently better approximation quality to the exact Natural Gradient updates than both EF and the more expensive sampled Fisher (SF). Further investigation also shows that the superior approximation quality of iEF is robust to damping across tasks and training stages. Improving existing approximate NGD optimisers with iEF is expected to lead to better convergence ability and stronger robustness to choice of damping.
6/11/2024