FAdam: Adam is a natural gradient optimizer using diagonal empirical Fisher information
2405.12807
0
0
🌿
Abstract
This paper establishes a mathematical foundation for the Adam optimizer, elucidating its connection to natural gradient descent through Riemannian and information geometry. We rigorously analyze the diagonal empirical Fisher information matrix (FIM) in Adam, clarifying all detailed approximations and advocating for the use of log probability functions as loss, which should be based on discrete distributions, due to the limitations of empirical FIM. Our analysis uncovers flaws in the original Adam algorithm, leading to proposed corrections such as enhanced momentum calculations, adjusted bias corrections, adaptive epsilon, and gradient clipping. We refine the weight decay term based on our theoretical framework. Our modified algorithm, Fisher Adam (FAdam), demonstrates superior performance across diverse domains including LLM, ASR, and VQ-VAE, achieving state-of-the-art results in ASR.
Create account to get full access
Overview
- This paper provides a mathematical analysis of the Adam optimizer, a popular algorithm used for training various machine learning models.
- The researchers investigate the connection between Adam and natural gradient descent, a technique that leverages information geometry and Riemannian manifolds.
- They uncover flaws in the original Adam algorithm and propose a modified version, called Fisher Adam (FAdam), which demonstrates superior performance across diverse domains such as large language models, automatic speech recognition, and vector quantized variational autoencoders.
Plain English Explanation
The paper delves into the mathematical foundations of the Adam optimizer, a widely used algorithm for training machine learning models. The researchers explore the relationship between Adam and a technique called natural gradient descent, which utilizes concepts from information geometry and Riemannian manifolds.
By analyzing the diagonal empirical Fisher information matrix used in Adam, the researchers uncover flaws in the original algorithm and propose several corrections. These include enhancing the momentum calculations, adjusting the bias corrections, and incorporating gradient clipping. They also refine the weight decay term based on their theoretical framework.
The resulting modified algorithm, called Fisher Adam (FAdam), demonstrates superior performance across a range of applications, including large language models, automatic speech recognition, and vector quantized variational autoencoders. The researchers show that FAdam can achieve state-of-the-art results in automatic speech recognition tasks.
Technical Explanation
The paper establishes a mathematical foundation for the Adam optimizer by analyzing its connection to natural gradient descent through Riemannian and information geometry. The researchers rigorously examine the diagonal empirical Fisher information matrix (FIM) used in Adam, clarifying all the detailed approximations and advocating for the use of log probability functions as the loss, which should be based on discrete distributions due to the limitations of the empirical FIM.
The analysis unveils flaws in the original Adam algorithm, leading to proposed corrections. These include enhanced momentum calculations, adjusted bias corrections, and the incorporation of gradient clipping. The researchers also refine the weight decay term based on their theoretical framework.
The modified algorithm, Fisher Adam (FAdam), is evaluated across diverse domains, including large language models, automatic speech recognition, and vector quantized variational autoencoders. The results demonstrate that FAdam can achieve state-of-the-art performance in automatic speech recognition tasks.
Critical Analysis
The paper provides a rigorous mathematical analysis of the Adam optimizer, shedding light on its connection to natural gradient descent. The researchers' proposed modifications, such as enhanced momentum calculations and adjusted bias corrections, aim to address the flaws they identified in the original Adam algorithm.
However, the paper raises questions about the practical implications and limitations of their approach. For instance, the researchers advocate for the use of log probability functions as the loss, which may not always be feasible or appropriate for certain applications. Additionally, the requirement of using discrete distributions for the loss function could limit the flexibility and applicability of the proposed FAdam algorithm.
Further research may be needed to explore the trade-offs between the theoretical advantages of FAdam and its practical implementation across a wider range of machine learning tasks. The impact of diagonal Fisher information matrix estimators on the algorithm's performance and the potential for conjugate gradient-like adaptations could also be investigated.
Conclusion
This paper provides a deep dive into the mathematical foundations of the Adam optimizer, elucidating its connection to natural gradient descent. The researchers' analysis uncovers flaws in the original algorithm and proposes the Fisher Adam (FAdam) variant, which demonstrates superior performance in various machine learning domains, including automatic speech recognition.
The study's insights into the role of information geometry and Riemannian manifolds in optimization algorithms could have broader implications for the field of machine learning. The modifications introduced in FAdam, such as enhanced momentum calculations and adjusted bias corrections, may inspire further advancements in optimizer design and contribute to the ongoing efforts to improve the efficiency and reliability of model training.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AdaFisher: Adaptive Second Order Optimization via Fisher Information
Damien Martins Gomes, Yanlei Zhang, Eugene Belilovsky, Guy Wolf, Mahdi S. Hosseini
0
0
First-order optimization methods are currently the mainstream in training deep neural networks (DNNs). Optimizers like Adam incorporate limited curvature information by employing the diagonal matrix preconditioning of the stochastic gradient during the training. Despite their widespread, second-order optimization algorithms exhibit superior convergence properties compared to their first-order counterparts e.g. Adam and SGD. However, their practicality in training DNNs are still limited due to increased per-iteration computations and suboptimal accuracy compared to the first order methods. We present AdaFisher--an adaptive second-order optimizer that leverages a block-diagonal approximation to the Fisher information matrix for adaptive gradient preconditioning. AdaFisher aims to bridge the gap between enhanced convergence capabilities and computational efficiency in second-order optimization framework for training DNNs. Despite the slow pace of second-order optimizers, we showcase that AdaFisher can be reliably adopted for image classification, language modelling and stand out for its stability and robustness in hyperparameter tuning. We demonstrate that AdaFisher outperforms the SOTA optimizers in terms of both accuracy and convergence speed. Code available from href{https://github.com/AtlasAnalyticsLab/AdaFisher}{https://github.com/AtlasAnalyticsLab/AdaFisher}
5/28/2024
An Improved Empirical Fisher Approximation for Natural Gradient Descent
Xiaodong Wu, Wenyi Yu, Chao Zhang, Philip Woodland
0
0
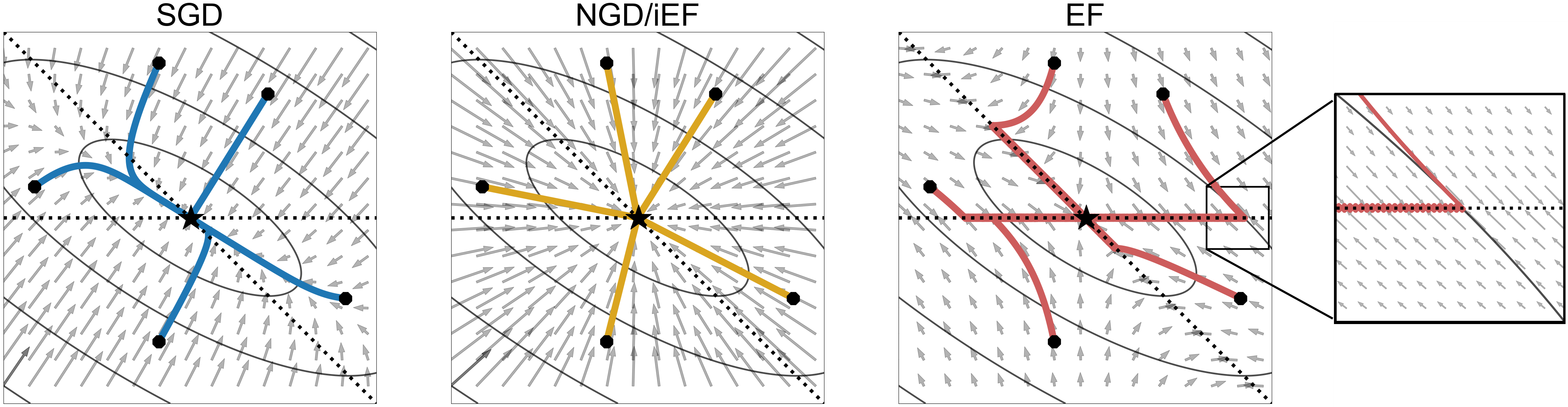
Approximate Natural Gradient Descent (NGD) methods are an important family of optimisers for deep learning models, which use approximate Fisher information matrices to pre-condition gradients during training. The empirical Fisher (EF) method approximates the Fisher information matrix empirically by reusing the per-sample gradients collected during back-propagation. Despite its ease of implementation, the EF approximation has its theoretical and practical limitations. This paper first investigates the inversely-scaled projection issue of EF, which is shown to be a major cause of the poor empirical approximation quality. An improved empirical Fisher (iEF) method, motivated as a generalised NGD method from a loss reduction perspective, is proposed to address this issue, meanwhile retaining the practical convenience of EF. The exact iEF and EF methods are experimentally evaluated using practical deep learning setups, including widely-used setups for parameter-efficient fine-tuning of pre-trained models (T5-base with LoRA and Prompt-Tuning on GLUE tasks, and ViT with LoRA for CIFAR100). Optimisation experiments show that applying exact iEF as an optimiser provides strong convergence and generalisation. It achieves the best test performance and the lowest training loss for majority of the tasks, even when compared with well-tuned AdamW/Adafactor baselines. Additionally, under a novel empirical evaluation framework, the proposed iEF method shows consistently better approximation quality to the exact Natural Gradient updates than both EF and the more expensive sampled Fisher (SF). Further investigation also shows that the superior approximation quality of iEF is robust to damping across tasks and training stages. Improving existing approximate NGD optimisers with iEF is expected to lead to better convergence ability and stronger robustness to choice of damping.
6/11/2024
SOFIM: Stochastic Optimization Using Regularized Fisher Information Matrix
Mrinmay Sen, A. K. Qin, Gayathri C, Raghu Kishore N, Yen-Wei Chen, Balasubramanian Raman
0
0
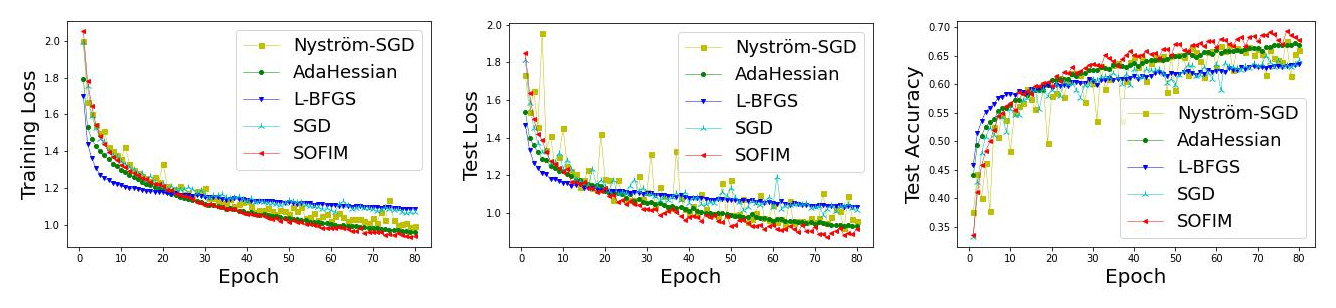
This paper introduces a new stochastic optimization method based on the regularized Fisher information matrix (FIM), named SOFIM, which can efficiently utilize the FIM to approximate the Hessian matrix for finding Newton's gradient update in large-scale stochastic optimization of machine learning models. It can be viewed as a variant of natural gradient descent, where the challenge of storing and calculating the full FIM is addressed through making use of the regularized FIM and directly finding the gradient update direction via Sherman-Morrison matrix inversion. Additionally, like the popular Adam method, SOFIM uses the first moment of the gradient to address the issue of non-stationary objectives across mini-batches due to heterogeneous data. The utilization of the regularized FIM and Sherman-Morrison matrix inversion leads to the improved convergence rate with the same space and time complexities as stochastic gradient descent (SGD) with momentum. The extensive experiments on training deep learning models using several benchmark image classification datasets demonstrate that the proposed SOFIM outperforms SGD with momentum and several state-of-the-art Newton optimization methods in term of the convergence speed for achieving the pre-specified objectives of training and test losses as well as test accuracy.
5/2/2024
🔮
On the Implicit Bias of Adam
Matias D. Cattaneo, Jason M. Klusowski, Boris Shigida
0
0
In previous literature, backward error analysis was used to find ordinary differential equations (ODEs) approximating the gradient descent trajectory. It was found that finite step sizes implicitly regularize solutions because terms appearing in the ODEs penalize the two-norm of the loss gradients. We prove that the existence of similar implicit regularization in RMSProp and Adam depends on their hyperparameters and the training stage, but with a different norm involved: the corresponding ODE terms either penalize the (perturbed) one-norm of the loss gradients or, conversely, impede its reduction (the latter case being typical). We also conduct numerical experiments and discuss how the proven facts can influence generalization.
6/18/2024