AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting
2405.08019
0
0
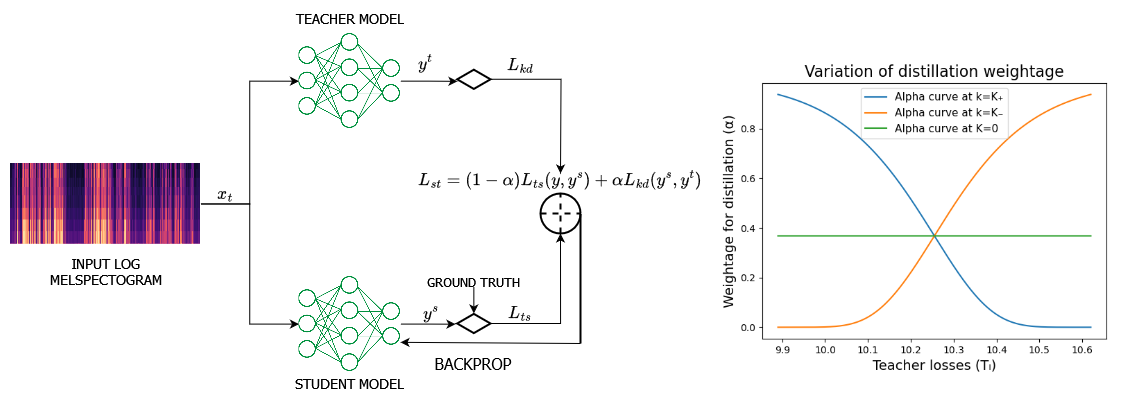
Abstract
Knowledge distillation, a widely used model compression technique, works on the basis of transferring knowledge from a cumbersome teacher model to a lightweight student model. The technique involves jointly optimizing the task specific and knowledge distillation losses with a weight assigned to them. Despite these weights playing a crucial role in the performance of the distillation process, current methods provide equal weight to both losses, leading to suboptimal performance. In this paper, we propose Adaptive Knowledge Distillation, a novel technique inspired by curriculum learning to adaptively weigh the losses at instance level. This technique goes by the notion that sample difficulty increases with teacher loss. Our method follows a plug-and-play paradigm that can be applied on top of any task-specific and distillation objectives. Experiments show that our method performs better than conventional knowledge distillation method and existing instance-level loss functions.
Create account to get full access
Overview
- This paper proposes a novel knowledge distillation method called AdaKD for training smaller Automatic Speech Recognition (ASR) models from larger, more accurate models.
- AdaKD uses an adaptive loss weighting scheme to dynamically balance the distillation loss between different speech recognition tasks during training.
- The authors demonstrate that AdaKD can effectively transfer knowledge from a large teacher model to a smaller student model, while achieving better performance than standard knowledge distillation approaches.
Plain English Explanation
AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting is a research paper that focuses on a technique called knowledge distillation. Knowledge distillation is a way to take a large, powerful machine learning model and transfer its knowledge to a smaller, simpler model. This can be useful when you want to deploy a model on a device with limited computing power, like a smartphone.
The key idea behind AdaKD is to use an "adaptive" approach to balance the different types of knowledge that need to be transferred from the large model to the small model. Different speech recognition tasks, like transcribing clear speech vs. noisy speech, require different types of knowledge. AdaKD dynamically adjusts the importance of each type of knowledge during the training process, allowing the small model to learn the most relevant information from the large model.
By using this adaptive approach, the authors show that the small model trained with AdaKD can achieve better performance than small models trained with standard knowledge distillation techniques. This means you can create highly accurate speech recognition models that are lightweight and efficient, which could be useful for applications like voice assistants or automated captioning.
Technical Explanation
The paper introduces a novel knowledge distillation method called AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting. Knowledge distillation is a technique for training a smaller "student" model to mimic the behavior of a larger "teacher" model, allowing the student to benefit from the teacher's superior performance.
AdaKD builds on this idea by using an adaptive loss weighting scheme to dynamically balance the distillation loss between different speech recognition tasks during training. The authors hypothesize that different speech recognition tasks, such as transcribing clear speech vs. noisy speech, require different types of knowledge from the teacher model. AdaKD aims to adaptively allocate more importance to the distillation loss for the tasks that are more critical for the student model's performance.
The authors evaluate AdaKD on several Automatic Speech Recognition (ASR) benchmarks, comparing it to standard knowledge distillation approaches. Their results show that the student models trained with AdaKD can achieve better performance than those trained with standard distillation, demonstrating the effectiveness of the adaptive loss weighting scheme.
Critical Analysis
The paper presents a well-designed study that introduces a novel knowledge distillation approach for ASR models. The key strength of AdaKD is its ability to dynamically adjust the importance of different speech recognition tasks during the distillation process, allowing the student model to better learn the most relevant knowledge from the teacher.
However, the paper does not provide extensive analysis of the limitations or caveats of the AdaKD method. For example, it would be helpful to understand how the adaptive loss weighting scheme performs when the gap in complexity between the teacher and student models is very large, or when the student model is required to perform a diverse set of speech recognition tasks.
Additionally, the paper could benefit from a more in-depth discussion of the potential real-world implications and applications of AdaKD, beyond the academic benchmarks presented. Exploring how the method could be applied to resource-constrained devices or edge computing scenarios would further strengthen the paper's contribution.
Overall, the AdaKD method represents an interesting and promising approach to knowledge distillation for ASR models. Further research to address the limitations and explore additional use cases could solidify the technique's impact on the field of speech recognition.
Conclusion
AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting introduces a novel knowledge distillation method that uses an adaptive loss weighting scheme to effectively transfer knowledge from a large teacher model to a smaller student model for Automatic Speech Recognition (ASR) tasks.
The key innovation of AdaKD is its ability to dynamically adjust the importance of different speech recognition subtasks during the distillation process, allowing the student model to learn the most relevant knowledge from the teacher. This approach has been shown to outperform standard knowledge distillation techniques, resulting in student models that achieve better performance.
The implications of this research are significant, as it offers a way to create highly accurate yet lightweight ASR models that could be deployed on resource-constrained devices, such as smartphones or edge computing systems. This could enable a wide range of practical applications, from voice assistants to automated captioning, while ensuring efficient use of computing resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Revisiting Knowledge Distillation for Autoregressive Language Models
Qihuang Zhong, Liang Ding, Li Shen, Juhua Liu, Bo Du, Dacheng Tao
0
0
Knowledge distillation (KD) is a common approach to compress a teacher model to reduce its inference cost and memory footprint, by training a smaller student model. However, in the context of autoregressive language models (LMs), we empirically find that larger teacher LMs might dramatically result in a poorer student. In response to this problem, we conduct a series of analyses and reveal that different tokens have different teaching modes, neglecting which will lead to performance degradation. Motivated by this, we propose a simple yet effective adaptive teaching approach (ATKD) to improve the KD. The core of ATKD is to reduce rote learning and make teaching more diverse and flexible. Extensive experiments on 8 LM tasks show that, with the help of ATKD, various baseline KD methods can achieve consistent and significant performance gains (up to +3.04% average score) across all model types and sizes. More encouragingly, ATKD can improve the student model generalization effectively.
6/18/2024

ReffAKD: Resource-efficient Autoencoder-based Knowledge Distillation
Divyang Doshi, Jung-Eun Kim
0
0
In this research, we propose an innovative method to boost Knowledge Distillation efficiency without the need for resource-heavy teacher models. Knowledge Distillation trains a smaller ``student'' model with guidance from a larger ``teacher'' model, which is computationally costly. However, the main benefit comes from the soft labels provided by the teacher, helping the student grasp nuanced class similarities. In our work, we propose an efficient method for generating these soft labels, thereby eliminating the need for a large teacher model. We employ a compact autoencoder to extract essential features and calculate similarity scores between different classes. Afterward, we apply the softmax function to these similarity scores to obtain a soft probability vector. This vector serves as valuable guidance during the training of the student model. Our extensive experiments on various datasets, including CIFAR-100, Tiny Imagenet, and Fashion MNIST, demonstrate the superior resource efficiency of our approach compared to traditional knowledge distillation methods that rely on large teacher models. Importantly, our approach consistently achieves similar or even superior performance in terms of model accuracy. We also perform a comparative study with various techniques recently developed for knowledge distillation showing our approach achieves competitive performance with using significantly less resources. We also show that our approach can be easily added to any logit based knowledge distillation method. This research contributes to making knowledge distillation more accessible and cost-effective for practical applications, making it a promising avenue for improving the efficiency of model training. The code for this work is available at, https://github.com/JEKimLab/ReffAKD.
4/16/2024

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024
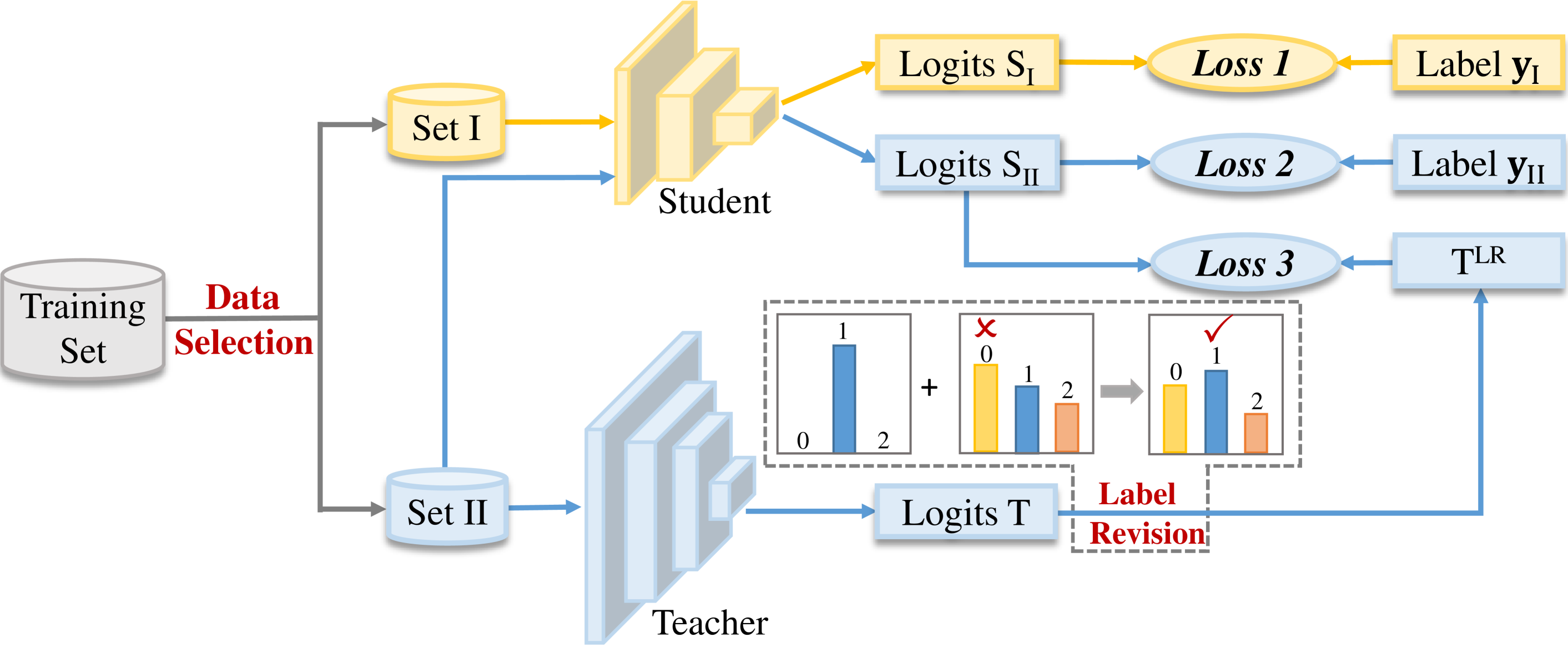
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024