Revisiting Knowledge Distillation for Autoregressive Language Models
2402.11890
0
0
💬
Abstract
Knowledge distillation (KD) is a common approach to compress a teacher model to reduce its inference cost and memory footprint, by training a smaller student model. However, in the context of autoregressive language models (LMs), we empirically find that larger teacher LMs might dramatically result in a poorer student. In response to this problem, we conduct a series of analyses and reveal that different tokens have different teaching modes, neglecting which will lead to performance degradation. Motivated by this, we propose a simple yet effective adaptive teaching approach (ATKD) to improve the KD. The core of ATKD is to reduce rote learning and make teaching more diverse and flexible. Extensive experiments on 8 LM tasks show that, with the help of ATKD, various baseline KD methods can achieve consistent and significant performance gains (up to +3.04% average score) across all model types and sizes. More encouragingly, ATKD can improve the student model generalization effectively.
Create account to get full access
Overview
- Knowledge distillation (KD) is a technique used to compress a large "teacher" machine learning model into a smaller "student" model.
- This is often done to reduce the inference cost and memory footprint of the model, making it more practical to deploy.
- However, the authors found that when applying KD to autoregressive language models (LMs), larger teacher models can actually lead to poorer student model performance.
- To address this issue, the authors propose an "Adaptive Teaching" approach (ATKD) to improve the KD process and boost student model performance.
Plain English Explanation
The paper explores a common technique called knowledge distillation (KD) that is used to make large machine learning models smaller and more efficient. The idea is to train a smaller "student" model to mimic the behavior of a larger "teacher" model, allowing the student to benefit from the teacher's capabilities while being more lightweight and practical to deploy.
However, the authors found that when applying KD to autoregressive language models, using a larger teacher model doesn't always lead to better student model performance. This is counterintuitive, as you might expect the student to learn more from a more capable teacher.
To understand this issue, the authors conducted a series of analyses and discovered that different tokens (the individual words or characters in the language model) have different "teaching modes" - some are better learned through direct imitation, while others benefit more from a more flexible and diverse teaching approach. By neglecting these differences, the standard KD process can actually degrade student model performance.
Motivated by these insights, the authors propose an "Adaptive Teaching" (ATKD) approach that aims to make the KD process more dynamic and tailored to the specific learning needs of different tokens. This helps the student model learn more effectively from the teacher, leading to consistent and significant performance improvements across a range of language modeling tasks and model sizes.
Importantly, the authors also found that ATKD can help the student model generalize better, meaning it performs well not just on the data it was trained on, but also on new, unseen data. This is a valuable property for practical applications of language models.
Technical Explanation
The core of the proposed ATKD approach is the recognition that different tokens in an autoregressive language model have different "teaching modes". Some tokens are better learned through direct imitation of the teacher's output, while others benefit more from a more flexible and diverse teaching approach that avoids rote learning.
By analyzing the behavior of teacher and student models, the authors found that neglecting these differences in teaching modes can lead to significant performance degradation in the student model, even when using a larger and more capable teacher. This is in contrast to the typical assumption that a more powerful teacher should always result in a better student.
To address this issue, ATKD dynamically adjusts the KD process to match the learning needs of different tokens. For tokens that benefit more from direct imitation, ATKD maintains a strong distillation signal. For tokens that require more diverse teaching, ATKD reduces the distillation signal and encourages the student to learn more independently.
Through extensive experiments on 8 different language modeling tasks, the authors demonstrate that ATKD can consistently and significantly improve the performance of various baseline KD methods, with gains of up to 3.04% in average score across all model types and sizes. Importantly, ATKD also enhances the student model's generalization ability, allowing it to perform well on new, unseen data.
Critical Analysis
The paper provides a thoughtful and well-designed study on improving the knowledge distillation process for autoregressive language models. The key insight - that different tokens require different teaching modes - is a novel and valuable contribution to the field.
However, the paper does not explore the potential limitations or downsides of the ATKD approach. For example, it's unclear how the adaptive teaching mechanism would scale to extremely large language models, or how sensitive the approach is to the specific hyperparameters and architecture choices.
Additionally, while the authors demonstrate significant performance gains, they do not provide a detailed analysis of the computational or memory efficiency of the ATKD-based student models compared to the baseline KD methods. This information would be valuable for assessing the practical benefits of the proposed technique.
Finally, the paper would be strengthened by a more in-depth discussion of the potential implications and applications of the ATKD approach, beyond just its performance on language modeling tasks. For example, how might this technique apply to other domains that utilize autoregressive models, such as automatic scoring of science education or speech recognition?
Overall, the paper presents a valuable contribution to the field of knowledge distillation for language models, but could be further strengthened by addressing these potential areas for improvement.
Conclusion
The paper introduces an "Adaptive Teaching" (ATKD) approach to improve the knowledge distillation process for autoregressive language models. The key insight is that different tokens require different teaching modes, and neglecting this can lead to a poorer performing student model, even when using a larger and more capable teacher.
By dynamically adjusting the distillation signal to match the learning needs of different tokens, ATKD is able to consistently and significantly boost the performance of various baseline KD methods, with gains of up to 3.04% on average. Importantly, the authors also show that ATKD can improve the student model's generalization abilities, allowing it to perform well on new, unseen data.
These findings have important implications for the practical deployment of large language models, as they suggest that carefully designed knowledge distillation techniques can help create smaller, more efficient models without sacrificing performance. The ATKD approach represents a valuable contribution to this area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024

MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
0
0
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge of white-box LLMs into small models is still under-explored, which becomes more important with the prosperity of open-source LLMs. In this work, we propose a KD approach that distills LLMs into smaller language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. The student models are named MiniLLM. Extensive experiments in the instruction-following setting show that MiniLLM generates more precise responses with higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance than the baselines. Our method is scalable for different model families with 120M to 13B parameters. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/minillm.
4/11/2024
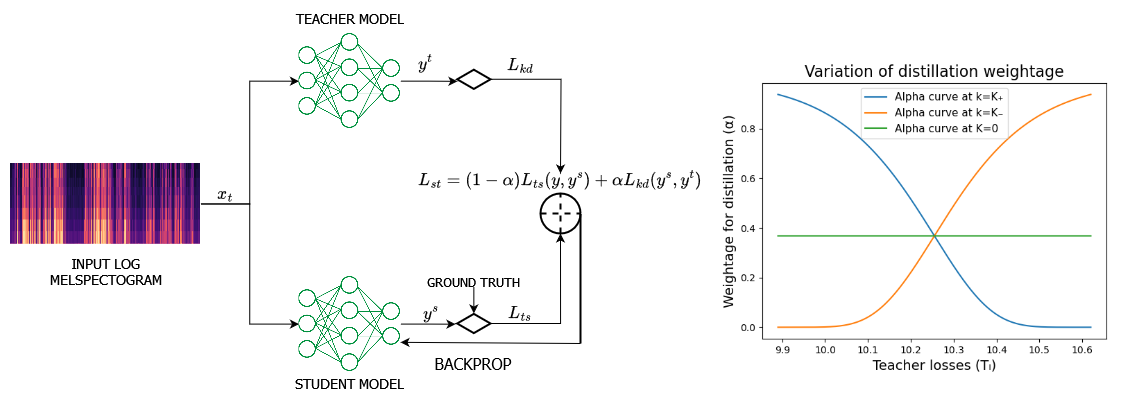
AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting
Shreyan Ganguly, Roshan Nayak, Rakshith Rao, Ujan Deb, Prathosh AP
0
0
Knowledge distillation, a widely used model compression technique, works on the basis of transferring knowledge from a cumbersome teacher model to a lightweight student model. The technique involves jointly optimizing the task specific and knowledge distillation losses with a weight assigned to them. Despite these weights playing a crucial role in the performance of the distillation process, current methods provide equal weight to both losses, leading to suboptimal performance. In this paper, we propose Adaptive Knowledge Distillation, a novel technique inspired by curriculum learning to adaptively weigh the losses at instance level. This technique goes by the notion that sample difficulty increases with teacher loss. Our method follows a plug-and-play paradigm that can be applied on top of any task-specific and distillation objectives. Experiments show that our method performs better than conventional knowledge distillation method and existing instance-level loss functions.
5/15/2024

ReffAKD: Resource-efficient Autoencoder-based Knowledge Distillation
Divyang Doshi, Jung-Eun Kim
0
0
In this research, we propose an innovative method to boost Knowledge Distillation efficiency without the need for resource-heavy teacher models. Knowledge Distillation trains a smaller ``student'' model with guidance from a larger ``teacher'' model, which is computationally costly. However, the main benefit comes from the soft labels provided by the teacher, helping the student grasp nuanced class similarities. In our work, we propose an efficient method for generating these soft labels, thereby eliminating the need for a large teacher model. We employ a compact autoencoder to extract essential features and calculate similarity scores between different classes. Afterward, we apply the softmax function to these similarity scores to obtain a soft probability vector. This vector serves as valuable guidance during the training of the student model. Our extensive experiments on various datasets, including CIFAR-100, Tiny Imagenet, and Fashion MNIST, demonstrate the superior resource efficiency of our approach compared to traditional knowledge distillation methods that rely on large teacher models. Importantly, our approach consistently achieves similar or even superior performance in terms of model accuracy. We also perform a comparative study with various techniques recently developed for knowledge distillation showing our approach achieves competitive performance with using significantly less resources. We also show that our approach can be easily added to any logit based knowledge distillation method. This research contributes to making knowledge distillation more accessible and cost-effective for practical applications, making it a promising avenue for improving the efficiency of model training. The code for this work is available at, https://github.com/JEKimLab/ReffAKD.
4/16/2024