Improve Knowledge Distillation via Label Revision and Data Selection
2404.03693
0
0
Abstract
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Create account to get full access
Overview
- This paper proposes a new approach to improve the performance of knowledge distillation, a technique used to transfer knowledge from a larger, more complex model to a smaller, more efficient one.
- The key ideas are to revise the labels used to train the student model and to selectively choose the most informative training data.
- These techniques are shown to outperform standard knowledge distillation on several image classification tasks.
Plain English Explanation
Knowledge distillation is a useful technique for making AI models more efficient and practical to deploy. The basic idea is to take a large, powerful model that has been trained on a lot of data, and use it to teach a smaller, simpler model. This allows the smaller model to benefit from the knowledge of the larger one, without needing to go through the full training process.
However, the standard knowledge distillation approach has some limitations. This paper presents two new ideas to address those issues.
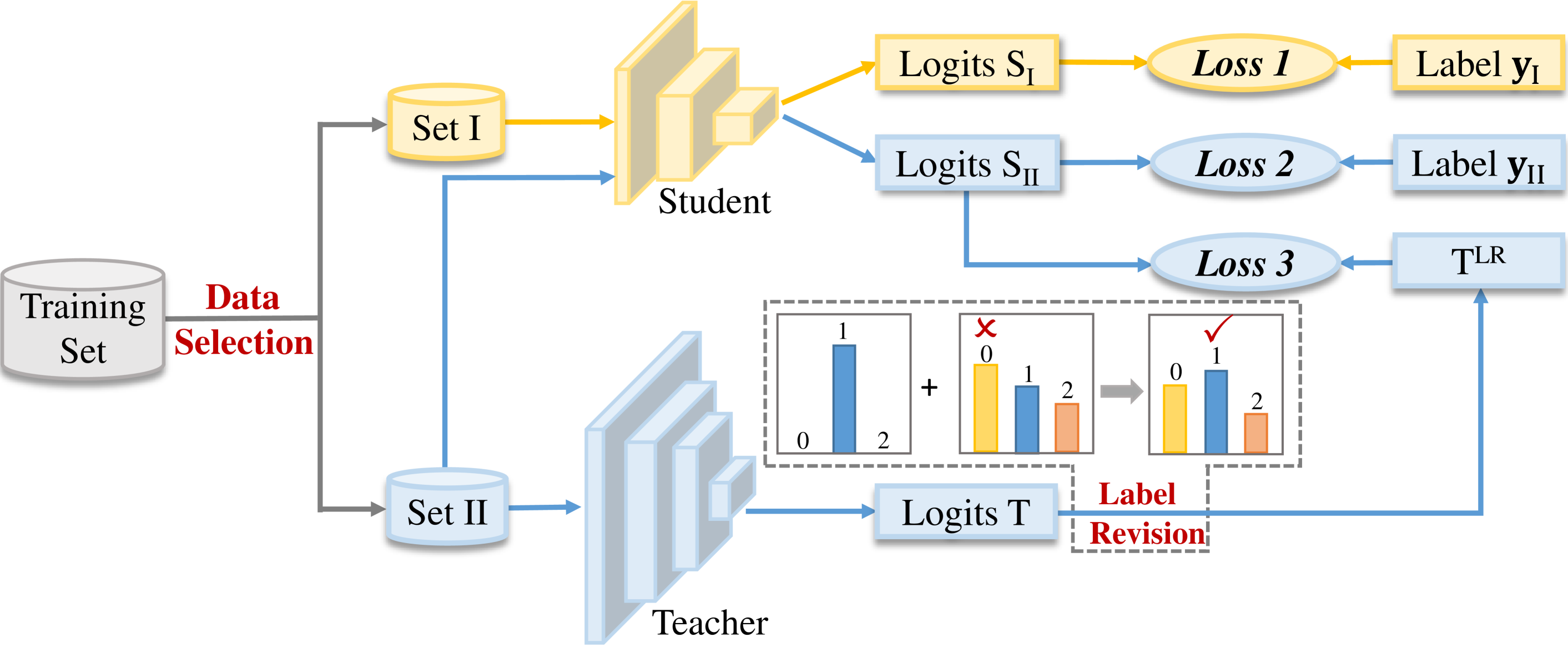
First, the authors propose "label revision" - instead of just using the original labels from the training data, they refine those labels based on the guidance of the larger teacher model. This helps the student model learn more accurate representations.
Second, they introduce "data selection" - rather than using the full training dataset, they selectively choose the most informative examples for the student model to learn from. This focuses the training process on the most relevant information.
By combining these label revision and data selection techniques, the authors are able to improve knowledge distillation on image classification tasks. This makes the student models more accurate and efficient, which is important for deploying AI in real-world applications like object detection or image super-resolution.
Technical Explanation
The core of this paper is a new knowledge distillation framework that incorporates two key components: label revision and data selection.
Label Revision: The authors observe that the original ground truth labels from the dataset may not always align well with the learned representations of the teacher model. To address this, they propose revising the labels using the teacher's predictions. This is done by linearly combining the original labels with the teacher's soft outputs, weighted by a learned parameter.
Data Selection: Not all training examples are equally informative for the student model. The authors introduce a data selection mechanism that assigns higher weights to the most valuable instances. This is based on the difference between the teacher's and student's predictions, as well as the diversity of the examples.
The full training process involves alternating between updating the student model parameters and the data selection weights. This allows the student to focus on the most relevant information during each training iteration.
The authors evaluate their approach on several image classification benchmarks, including CIFAR-100, and demonstrate consistent improvements over standard knowledge distillation baselines. They also provide ablation studies to analyze the individual contributions of label revision and data selection.
Critical Analysis
One potential limitation of this work is that the label revision and data selection mechanisms add additional complexity and hyperparameters to the knowledge distillation process. The authors do not provide extensive guidance on how to tune these new components, which could make it challenging to apply the method in practice.
Additionally, the experiments are primarily focused on image classification tasks. It would be valuable to see how the proposed techniques perform on other domains, such as object detection or image super-resolution, where knowledge distillation is also widely used.
Finally, the authors do not discuss potential societal impacts or ethical considerations of their work. As AI models become more widely deployed, it is important to think critically about the implications of techniques like knowledge distillation and how they may affect fairness, privacy, and other important principles.
Conclusion
This paper presents a novel approach to improve the performance of knowledge distillation by revising the training labels and selectively choosing the most informative data examples. The authors demonstrate the effectiveness of their techniques on image classification tasks, outperforming standard knowledge distillation baselines.
These ideas have the potential to make AI models more efficient and practical to deploy in real-world applications, which is an important goal as the use of AI becomes more widespread. However, further research is needed to address the limitations and explore the broader implications of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
0
0
How to conduct teacher training for knowledge distillation is still an open problem. It has been widely observed that a best-performing teacher does not necessarily yield the best-performing student, suggesting a fundamental discrepancy between the current teacher training practice and the ideal teacher training strategy. To fill this gap, we explore the feasibility of training a teacher that is oriented toward student performance with empirical risk minimization (ERM). Our analyses are inspired by the recent findings that the effectiveness of knowledge distillation hinges on the teacher's capability to approximate the true label distribution of training inputs. We theoretically establish that the ERM minimizer can approximate the true label distribution of training data as long as the feature extractor of the learner network is Lipschitz continuous and is robust to feature transformations. In light of our theory, we propose a teacher training method SoTeacher which incorporates Lipschitz regularization and consistency regularization into ERM. Experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs confirm that SoTeacher can improve student accuracy consistently.
5/10/2024

Small Scale Data-Free Knowledge Distillation
He Liu, Yikai Wang, Huaping Liu, Fuchun Sun, Anbang Yao
0
0
Data-free knowledge distillation is able to utilize the knowledge learned by a large teacher network to augment the training of a smaller student network without accessing the original training data, avoiding privacy, security, and proprietary risks in real applications. In this line of research, existing methods typically follow an inversion-and-distillation paradigm in which a generative adversarial network on-the-fly trained with the guidance of the pre-trained teacher network is used to synthesize a large-scale sample set for knowledge distillation. In this paper, we reexamine this common data-free knowledge distillation paradigm, showing that there is considerable room to improve the overall training efficiency through a lens of ``small-scale inverted data for knowledge distillation. In light of three empirical observations indicating the importance of how to balance class distributions in terms of synthetic sample diversity and difficulty during both data inversion and distillation processes, we propose Small Scale Data-free Knowledge Distillation SSD-KD. In formulation, SSD-KD introduces a modulating function to balance synthetic samples and a priority sampling function to select proper samples, facilitated by a dynamic replay buffer and a reinforcement learning strategy. As a result, SSD-KD can perform distillation training conditioned on an extremely small scale of synthetic samples (e.g., 10X less than the original training data scale), making the overall training efficiency one or two orders of magnitude faster than many mainstream methods while retaining superior or competitive model performance, as demonstrated on popular image classification and semantic segmentation benchmarks. The code is available at https://github.com/OSVAI/SSD-KD.
6/13/2024

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024
🐍
Dual Correction Strategy for Ranking Distillation in Top-N Recommender System
Youngjune Lee, Kee-Eung Kim
0
0
Knowledge Distillation (KD), which transfers the knowledge of a well-trained large model (teacher) to a small model (student), has become an important area of research for practical deployment of recommender systems. Recently, Relaxed Ranking Distillation (RRD) has shown that distilling the ranking information in the recommendation list significantly improves the performance. However, the method still has limitations in that 1) it does not fully utilize the prediction errors of the student model, which makes the training not fully efficient, and 2) it only distills the user-side ranking information, which provides an insufficient view under the sparse implicit feedback. This paper presents Dual Correction strategy for Distillation (DCD), which transfers the ranking information from the teacher model to the student model in a more efficient manner. Most importantly, DCD uses the discrepancy between the teacher model and the student model predictions to decide which knowledge to be distilled. By doing so, DCD essentially provides the learning guidance tailored to correcting what the student model has failed to accurately predict. This process is applied for transferring the ranking information from the user-side as well as the item-side to address sparse implicit user feedback. Our experiments show that the proposed method outperforms the state-of-the-art baselines, and ablation studies validate the effectiveness of each component.
5/16/2024