Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization
2309.07430
0
0
💬
Abstract
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP), their effectiveness on a diverse range of clinical summarization tasks remains unproven. In this study, we apply adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Quantitative assessments with syntactic, semantic, and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with ten physicians evaluates summary completeness, correctness, and conciseness; in a majority of cases, summaries from our best adapted LLMs are either equivalent (45%) or superior (36%) compared to summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This study explores the use of large language models (LLMs) for clinical text summarization tasks, such as summarizing radiology reports, patient questions, progress notes, and doctor-patient dialogues.
- The researchers applied adaptation methods to eight different LLMs and evaluated their performance using syntactic, semantic, and conceptual natural language processing (NLP) metrics.
- They also conducted a clinical reader study with ten physicians to assess the completeness, correctness, and conciseness of the summaries generated by the adapted LLMs and medical experts.
- The study provides evidence that LLMs can outperform medical experts in certain clinical text summarization tasks, suggesting that integrating LLMs into clinical workflows could help alleviate the burden of documentation and allow clinicians to focus more on patient care.
Plain English Explanation
Clinicians often have to review and summarize large amounts of text data, such as electronic health records, which can be time-consuming and take away from their ability to focus on patient care. Large language models (LLMs) have shown promise in natural language processing (NLP), but their effectiveness on a diverse range of clinical summarization tasks has not been well-established.
In this study, the researchers took eight different LLMs and adapted them to four specific clinical summarization tasks: summarizing radiology reports, patient questions, progress notes, and doctor-patient dialogues. They used various NLP metrics to evaluate the performance of these adapted models, looking at factors like syntax, semantics, and conceptual understanding.
The researchers also had ten physicians review and assess the summaries generated by the adapted LLMs and medical experts. In many cases, the summaries from the best-adapted LLMs were either equivalent or even better than the summaries produced by the medical experts in terms of completeness, correctness, and conciseness.
The study also identified some challenges and potential issues with both the LLMs and the medical experts, such as the LLMs sometimes generating fabricated information that could lead to medical harm. Overall, the research suggests that integrating LLMs into clinical workflows could help reduce the burden of documentation on clinicians, allowing them to focus more on providing quality patient care.
Technical Explanation
The researchers in this study applied adaptation methods to eight different large language models (LLMs) to assess their effectiveness on a diverse range of clinical text summarization tasks. They evaluated the models on four specific tasks: summarizing radiology reports, patient questions, progress notes, and doctor-patient dialogues.
The adaptation methods involved fine-tuning the LLMs on task-specific datasets to improve their performance on the clinical summarization tasks. The researchers then used a variety of NLP metrics, including syntactic, semantic, and conceptual measures, to quantitatively assess the quality of the summaries generated by the adapted LLMs.
In addition to the quantitative evaluation, the researchers conducted a clinical reader study with ten physicians. The physicians were asked to evaluate the summaries generated by the adapted LLMs and medical experts in terms of completeness, correctness, and conciseness. The results of this reader study showed that in a majority of cases, the summaries from the best-adapted LLMs were either equivalent (45%) or superior (36%) to the summaries produced by medical experts.
The study also included a safety analysis that highlighted challenges faced by both the LLMs and the medical experts. The researchers connected certain errors in the summaries to potential medical harm and categorized the types of fabricated information generated by the LLMs.
Critical Analysis
The researchers in this study provide evidence that LLMs can outperform medical experts in certain clinical text summarization tasks. This is a significant finding, as it suggests that integrating LLMs into clinical workflows could potentially alleviate the burden of documentation on clinicians and allow them to focus more on patient care.
However, the study also highlights some important limitations and challenges that need to be addressed. The safety analysis, for example, revealed that both the LLMs and the medical experts can generate summaries that contain errors or fabricated information that could lead to potential medical harm. This underscores the need for robust safety mechanisms and careful oversight when deploying LLMs in clinical settings.
Additionally, the study focused on a limited set of clinical summarization tasks, and the effectiveness of the adapted LLMs may vary across a broader range of clinical tasks and scenarios. Further research is needed to evaluate the performance of LLMs on a wider variety of clinical applications, as well as to explore ways to improve the reliability and robustness of these models.
It's also worth noting that the clinical reader study was conducted with a relatively small sample size of ten physicians. While the results are promising, a larger-scale evaluation with a more diverse set of clinicians would help to strengthen the conclusions and provide a more comprehensive understanding of the strengths and limitations of using LLMs for clinical text summarization.
Conclusion
This study provides important evidence that large language models (LLMs) can outperform medical experts in certain clinical text summarization tasks, such as summarizing radiology reports, patient questions, progress notes, and doctor-patient dialogues. The researchers applied adaptation methods to eight different LLMs and found that in many cases, the summaries generated by the best-adapted models were either equivalent or superior to those produced by medical experts.
These findings suggest that integrating LLMs into clinical workflows could help alleviate the burden of documentation on clinicians, allowing them to focus more on patient care. However, the study also highlights the need for robust safety mechanisms and further research to address the challenges and limitations of using LLMs in clinical settings, such as the potential for generating fabricated information that could lead to medical harm.
Overall, this research represents an important step forward in exploring the potential of LLMs to support clinicians in their work and improve the efficiency and quality of healthcare delivery. As the field of medical NLP continues to evolve, studies like this will be crucial in guiding the development and deployment of these powerful AI technologies in clinical practice.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
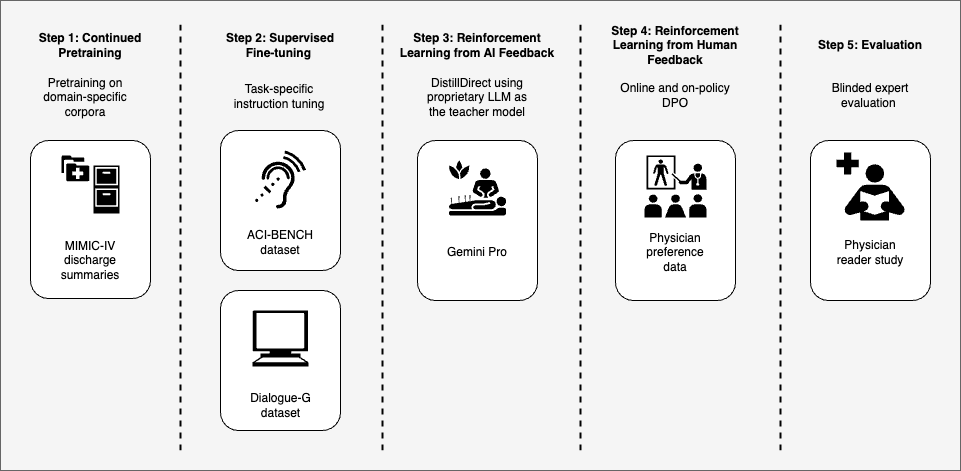
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Jimeng Sun
0
0
Large Language Models (LLMs) have shown promising capabilities in handling clinical text summarization tasks. In this study, we demonstrate that a small open-source LLM can be effectively trained to generate high-quality clinical notes from outpatient patient-doctor dialogues. We achieve this through a comprehensive domain- and task-specific adaptation process for the LLaMA-2 13 billion parameter model. This process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced an enhanced approach, termed DistillDirect, for performing on-policy reinforcement learning with Gemini Pro serving as the teacher model. Our resulting model, LLaMA-Clinic, is capable of generating clinical notes that are comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. Notably, in the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness compared to physician-authored notes (4.1/5). Additionally, we identified caveats in public clinical note datasets, such as ACI-BENCH. We highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format. Overall, our research demonstrates the potential and feasibility of training smaller, open-source LLMs to assist with clinical documentation, capitalizing on healthcare institutions' access to patient records and domain expertise. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research in this field.
5/3/2024
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024
💬
A Comprehensive Survey of Large Language Models and Multimodal Large Language Models in Medicine
Hanguang Xiao, Feizhong Zhou, Xingyue Liu, Tianqi Liu, Zhipeng Li, Xin Liu, Xiaoxuan Huang
0
0
Since the release of ChatGPT and GPT-4, large language models (LLMs) and multimodal large language models (MLLMs) have garnered significant attention due to their powerful and general capabilities in understanding, reasoning, and generation, thereby offering new paradigms for the integration of artificial intelligence with medicine. This survey comprehensively overviews the development background and principles of LLMs and MLLMs, as well as explores their application scenarios, challenges, and future directions in medicine. Specifically, this survey begins by focusing on the paradigm shift, tracing the evolution from traditional models to LLMs and MLLMs, summarizing the model structures to provide detailed foundational knowledge. Subsequently, the survey details the entire process from constructing and evaluating to using LLMs and MLLMs with a clear logic. Following this, to emphasize the significant value of LLMs and MLLMs in healthcare, we survey and summarize 6 promising applications in healthcare. Finally, the survey discusses the challenges faced by medical LLMs and MLLMs and proposes a feasible approach and direction for the subsequent integration of artificial intelligence with medicine. Thus, this survey aims to provide researchers with a valuable and comprehensive reference guide from the perspectives of the background, principles, and clinical applications of LLMs and MLLMs.
5/15/2024
🤯
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
Duygu Altinok
0
0
Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
5/8/2024