Fine-tuning Large Language Models for Automated Diagnostic Screening Summaries
2403.20145
0
0
Abstract
Improving mental health support in developing countries is a pressing need. One potential solution is the development of scalable, automated systems to conduct diagnostic screenings, which could help alleviate the burden on mental health professionals. In this work, we evaluate several state-of-the-art Large Language Models (LLMs), with and without fine-tuning, on our custom dataset for generating concise summaries from mental state examinations. We rigorously evaluate four different models for summary generation using established ROUGE metrics and input from human evaluators. The results highlight that our top-performing fine-tuned model outperforms existing models, achieving ROUGE-1 and ROUGE-L values of 0.810 and 0.764, respectively. Furthermore, we assessed the fine-tuned model's generalizability on a publicly available D4 dataset, and the outcomes were promising, indicating its potential applicability beyond our custom dataset.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
Related Works
This paper focuses on abstractive summarization, which involves using new words and phrases to create a summary, even if they weren't present in the original text. Large language models (LLMs) like GPT, BART, and T5 have shown promise for abstractive summarization, but their application in the medical and psychological domains requires further exploration to address inaccuracies without domain-specific knowledge.
The paper discusses the evolution of abstractive summarization techniques, including sequence-to-sequence models, attention mechanisms, and transformer-based encoder-decoder architectures. It also mentions the use of pointing mechanisms for word copying from the source document.
Regarding dialogue summarization, the paper notes that while models like BART and GPT-3 demonstrate exceptional performance on general-purpose tasks, they often require additional domain-specific conversation/dialogue data to understand dialogues better. The lack of publicly available appropriate datasets for medical dialogues, particularly in the psychological domain, creates a challenge for generating accurate abstractive summaries.
The paper highlights recent advancements in automatic medical dialogue summarization, including the use of LSTM and transformer models to generate single-sentence summaries from doctor-patient conversations, as well as the application of hierarchical encoder-tagger models to identify and extract meaningful utterances. However, the paper suggests that conversations in the psychological domain present unique challenges due to their longer length and more detailed patient responses, requiring specialized approaches beyond those employed in typical dialogue processing.
Methodology
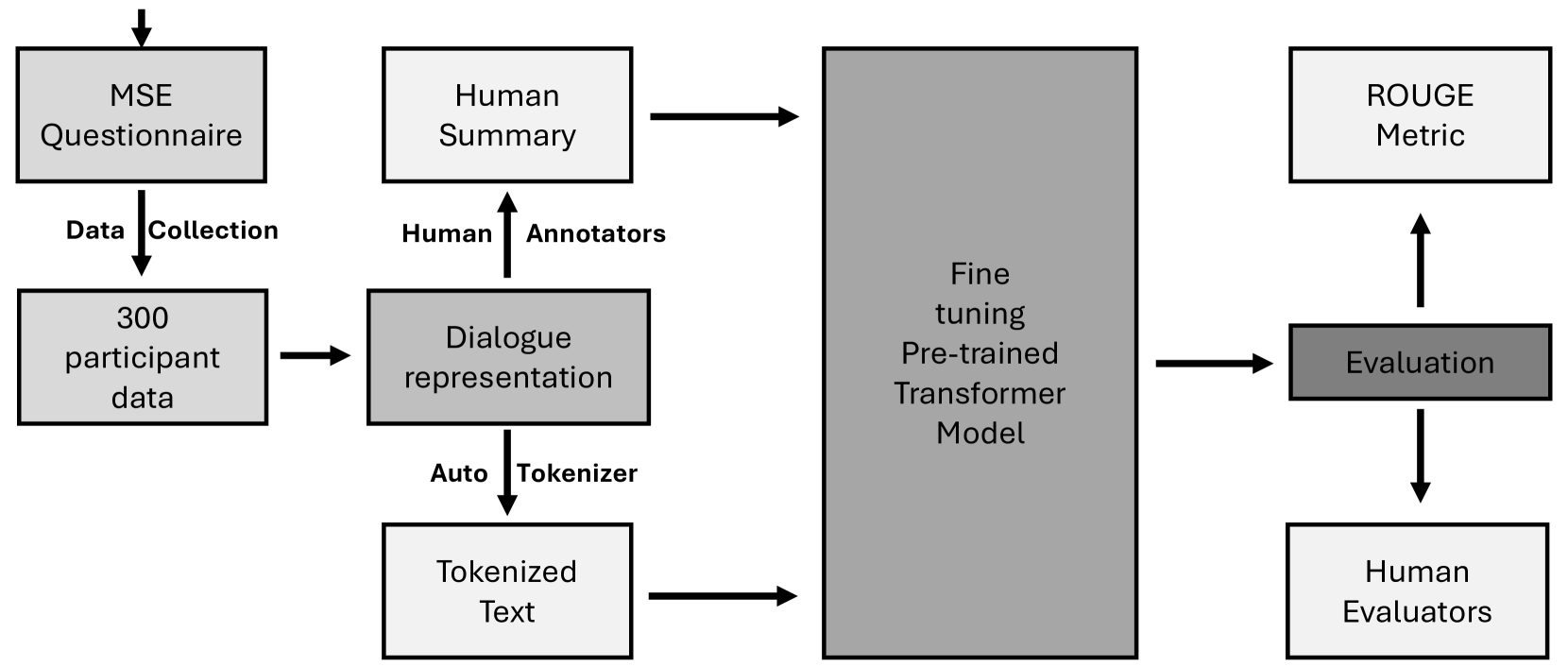
Figure 1 provides a high-level overview of the methodology. The detailed description of the methodology sub-components is as follows:
The researchers identified the lack of a standardized Mental State Examination (MSE) questionnaire and reviewed existing options. They created a preliminary 18-question version tailored for students, covering key components like socialness, mood, attention, memory, frustration tolerance, and social support. The researchers then sought input from clinical psychiatrists to refine the questionnaire, resulting in a finalized 12-question version.
The researchers conducted a data collection study at their institute, obtaining ethical approval and recruiting student participants. Participants completed the MSE questionnaire, with their responses transformed into simulated doctor-patient conversations. This process generated 300 conversations with 7200 total utterances.
To facilitate training supervised deep-learning models for summarizing the conversations, the researchers developed a structured summary template that underwent review and revision. They then evaluated several pre-trained transformer-based models, including BART, T5, and models fine-tuned on conversational and medical text data, for their suitability in summarizing the collected MSE conversations.
Experiments
The paper adopted the ROUGE metric as the primary evaluation criterion for automated summarization. The ROUGE metric compares the automated summary generated from the trained model with the reference summary. While ROUGE is well-suited for assessing syntactical textual similarities, it fails to capture semantic similarities between summaries. To address this limitation, the authors conducted qualitative analysis using ratings from clinical and non-clinical annotators to assess the semantic similarities between reference and model-generated summaries.
The analysis showed that the fine-tuned BART-large-CNN model achieved the highest ROUGE values, outperforming other models. However, the model-generated summaries slightly lacked in completeness and relevance compared to human-generated summaries. The model-generated summaries also contained more missing information, and a higher degree of contradiction was observed, although the model did not exhibit hallucination.
The inter-rater agreement analysis showed moderate agreement and strong correlation among clinical annotators, while non-clinical annotators demonstrated good reliability in their assessments.
Generalization
The researchers used the publicly available D4 dataset to assess the generalizability of their best fine-tuned BART-large CNN model. They had three independent non-clinical reviewers rate the summaries generated by the model for ten randomly selected conversations from the D4 dataset. The evaluation parameters included completeness, relevance to the medical context, fluency, clarity, missingness, hallucination, contradiction, and repetitions.
The D4 dataset was in Chinese, so the researchers used Google Translate to translate the conversations to English. They extracted ten doctor-patient conversations, assigned dummy participant identifiers, and shared the translated English conversations and the corresponding fine-tuned BART-large-CNN model-generated summaries with the reviewers.
The review found that the best fine-tuned model's summary scored well in relevance, fluency, clarity, and repetition. However, the generated summary was slightly lacking in terms of missing information, hallucination, and contradiction. Tables in the appendix present example dialogues from the D4 dataset and the corresponding summaries generated by the fine-tuned BART-large-CNN model.
Comparison with the previous work
The paper represents the first attempt to summarize psychological conversation data, which differs from traditional text summarization but shares similarities with dialogue summarization. The model trained on the authors' dataset achieved a ROUGE-L score of 0.764, outperforming the previous work by Yao et al. (2022) which had a score of 0.26. The fine-tuned model also produced fluent and comprehensive summaries when applied to the dataset used by Yao et al. (2022).
The paper presents a comparative report with existing research in doctor-patient conversation analysis. The results show that the fine-tuned model outperforms the existing work by Yao et al. (2022), Krishna et al. (2021), Michalopoulos et al. (2022), and Zhang et al. (2021) in terms of the ROUGE metric. However, it is important to note that the previous studies used different datasets and had their own specific objectives beyond solely summarizing entire conversations. The current work primarily aims to generate summaries of psychological conversations, which presents its own challenges, such as dealing with lengthy conversation data and resulting in longer utterances.
Conclusion
The paper investigates using pre-trained transformer models to generate summaries of psychological patient conversations. This task faces several challenges, including limited publicly available data, significant domain shift from typical pre-training text, and unstructured lengthy dialogues.
The paper demonstrates that fine-tuning transformer models on a specific dataset can generate fluent and adequate summaries, even with limited training data. The resulting models outperform pre-trained models and surpass the quality of previously published work on this task.
The paper evaluates transformer models for handling psychological conversations, compares pre-trained and fine-tuned models, and conducts extensive and intensive evaluations.
Ethical Consideration
The study used anonymized numerical identifiers to store sensitive personal information about the participants, such as name, age, and email address, to ensure their privacy. The study was approved by the ethics committee of the host institute.
The pre-trained model demonstrated effectiveness on the dataset, and the models used were able to learn from a small number of conversations in fewer epochs. This suggests that utilizing pre-trained models tailored to specific tasks may yield better results than developing models from scratch, which can require large datasets and more training time.
The researchers initially hypothesized that the BART-large-xsum-samsum model trained on dialogue summarization data would perform better than other summarization models. However, they found that the BART-large-CNN model outperformed in terms of all ROUGE metrics, indicating that their hypothesis was incorrect. Further exploration is warranted.
This work presented the best fine-tuned summarization models for generating accurate and concise summaries from mental health conversations to assist overburdened psychiatrists. The primary intention is not to replace doctors but to serve as an assistant, offering concise summaries of patients' mental health. This approach holds promise for implementation in low-income countries with a shortage of mental health professionals, but further research is necessary to address privacy concerns and ensure the accuracy of the data utilized.
Limitations
This work achieved a better ROUGE score by comparing the generated and human reference summaries. However, the work has several limitations:
-
The study did not incorporate the physical behavior and appearance of the participants during the MSE (multimodal summarization evaluation). This could be addressed by activating the front camera or webcam of participants' phones while recording their responses.
-
There were instances where the participants' utterances were unclear to the reviewers. In real-world scenarios, a doctor would typically ask the patient to repeat or explain further. This poses a challenge in the study. The issue could potentially be mitigated by testing the user's response for fluency and completeness after each utterance and prompting the user to elaborate if the model detects an issue.
Appendix A Appendix
The paper summarizes the technical details and performance of the BART-large-CNN, T5 large, and BART-large-xsum-samsum models used for generating summaries of psychological conversations. Key points:
-
The models were trained using the following hyperparameters: max token length of 1024 tokens, 500 warmup steps, 0.01 weight decay, evaluation strategy of steps every 500 steps, save steps of 1 million, and gradient accumulation of 16 steps. Training was done on an NVIDIA A100-PCIE-40GB GPU, with an average training time of 45 minutes.
-
ROUGE evaluation metrics showed the models achieved strong performance, with the BART-large-CNN model performing the best across ROUGE-1, ROUGE-2, ROUGE-L, and ROUGE-L-SUM scores.
-
Human evaluation by both clinical and non-clinical annotators was also conducted, assessing criteria like completeness, relevance, fluency, clarity, missingness, hallucination, contradiction, and repetition. The results showed the generated summaries were of high quality.
-
Inter-rater reliability between the annotators was measured using Cohen's Kappa and Pearson's correlation, indicating strong agreement.
Overall, the paper demonstrates the effectiveness of large language models like BART and T5 for summarizing psychological conversations, with the BART-large-CNN model performing the best.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization
Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, Eduardo Pontes Reis, Anna Seehofnerova, Nidhi Rohatgi, Poonam Hosamani, William Collins, Neera Ahuja, Curtis P. Langlotz, Jason Hom, Sergios Gatidis, John Pauly, Akshay S. Chaudhari
0
0
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP), their effectiveness on a diverse range of clinical summarization tasks remains unproven. In this study, we apply adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Quantitative assessments with syntactic, semantic, and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with ten physicians evaluates summary completeness, correctness, and conciseness; in a majority of cases, summaries from our best adapted LLMs are either equivalent (45%) or superior (36%) compared to summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care.
4/15/2024
Towards a Robust Retrieval-Based Summarization System
Shengjie Liu, Jing Wu, Jingyuan Bao, Wenyi Wang, Naira Hovakimyan, Christopher G Healey
0
0
This paper describes an investigation of the robustness of large language models (LLMs) for retrieval augmented generation (RAG)-based summarization tasks. While LLMs provide summarization capabilities, their performance in complex, real-world scenarios remains under-explored. Our first contribution is LogicSumm, an innovative evaluation framework incorporating realistic scenarios to assess LLM robustness during RAG-based summarization. Based on limitations identified by LogiSumm, we then developed SummRAG, a comprehensive system to create training dialogues and fine-tune a model to enhance robustness within LogicSumm's scenarios. SummRAG is an example of our goal of defining structured methods to test the capabilities of an LLM, rather than addressing issues in a one-off fashion. Experimental results confirm the power of SummRAG, showcasing improved logical coherence and summarization quality. Data, corresponding model weights, and Python code are available online.
4/1/2024
Bespoke Large Language Models for Digital Triage Assistance in Mental Health Care
Niall Taylor, Andrey Kormilitzin, Isabelle Lorge, Alejo Nevado-Holgado, Dan W Joyce
0
0
Contemporary large language models (LLMs) may have utility for processing unstructured, narrative free-text clinical data contained in electronic health records (EHRs) -- a particularly important use-case for mental health where a majority of routinely-collected patient data lacks structured, machine-readable content. A significant problem for the the United Kingdom's National Health Service (NHS) are the long waiting lists for specialist mental healthcare. According to NHS data, in each month of 2023, there were between 370,000 and 470,000 individual new referrals into secondary mental healthcare services. Referrals must be triaged by clinicians, using clinical information contained in the patient's EHR to arrive at a decision about the most appropriate mental healthcare team to assess and potentially treat these patients. The ability to efficiently recommend a relevant team by ingesting potentially voluminous clinical notes could help services both reduce referral waiting times and with the right technology, improve the evidence available to justify triage decisions. We present and evaluate three different approaches for LLM-based, end-to-end ingestion of variable-length clinical EHR data to assist clinicians when triaging referrals. Our model is able to deliver triage recommendations consistent with existing clinical practices and it's architecture was implemented on a single GPU, making it practical for implementation in resource-limited NHS environments where private implementations of LLM technology will be necessary to ensure confidential clinical data is appropriately controlled and governed.
4/1/2024
💬
Evaluating Text Summaries Generated by Large Language Models Using OpenAI's GPT
Hassan Shakil, Atqiya Munawara Mahi, Phuoc Nguyen, Zeydy Ortiz, Mamoun T. Mardini
0
0
This research examines the effectiveness of OpenAI's GPT models as independent evaluators of text summaries generated by six transformer-based models from Hugging Face: DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS. We evaluated these summaries based on essential properties of high-quality summary - conciseness, relevance, coherence, and readability - using traditional metrics such as ROUGE and Latent Semantic Analysis (LSA). Uniquely, we also employed GPT not as a summarizer but as an evaluator, allowing it to independently assess summary quality without predefined metrics. Our analysis revealed significant correlations between GPT evaluations and traditional metrics, particularly in assessing relevance and coherence. The results demonstrate GPT's potential as a robust tool for evaluating text summaries, offering insights that complement established metrics and providing a basis for comparative analysis of transformer-based models in natural language processing tasks.
5/8/2024