Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
2404.04997
0
0
Abstract
The rapid advancement of Large Language Models (LLMs) has inaugurated a transformative epoch in natural language processing, fostering unprecedented proficiency in text generation, comprehension, and contextual scrutiny. Nevertheless, effectively handling extensive contexts, crucial for myriad applications, poses a formidable obstacle owing to the intrinsic constraints of the models' context window sizes and the computational burdens entailed by their operations. This investigation presents an innovative framework that strategically tailors LLMs for streamlined context processing by harnessing the synergies among natural language summarization, soft prompt compression, and augmented utility preservation mechanisms. Our methodology, dubbed SoftPromptComp, amalgamates natural language prompts extracted from summarization methodologies with dynamically generated soft prompts to forge a concise yet semantically robust depiction of protracted contexts. This depiction undergoes further refinement via a weighting mechanism optimizing information retention and utility for subsequent tasks. We substantiate that our framework markedly diminishes computational overhead and enhances LLMs' efficacy across various benchmarks, while upholding or even augmenting the caliber of the produced content. By amalgamating soft prompt compression with sophisticated summarization, SoftPromptComp confronts the dual challenges of managing lengthy contexts and ensuring model scalability. Our findings point towards a propitious trajectory for augmenting LLMs' applicability and efficiency, rendering them more versatile and pragmatic for real-world applications. This research enriches the ongoing discourse on optimizing language models, providing insights into the potency of soft prompts and summarization techniques as pivotal instruments for the forthcoming generation of NLP solutions.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a method for adapting large language models (LLMs) to process context more efficiently through "soft prompt compression".
- The authors explore ways to reduce the amount of context information required by LLMs while maintaining performance on downstream tasks.
- Key ideas include using reinforcement learning to learn compressed prompts and transferring this knowledge to new tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive abilities in a wide range of natural language tasks. However, these models can be computationally expensive, as they require processing large amounts of context information to generate relevant outputs.
The researchers in this paper explore ways to make LLMs more efficient by compressing the context information they need to process. They developed a technique called "soft prompt compression" that uses reinforcement learning to learn a compressed version of the input prompt. This compressed prompt can then be used to condition the LLM, allowing it to generate relevant outputs while processing less overall context.
The key insight is that not all parts of the input context are equally important for a given task. By learning to focus on the most relevant information, the model can produce high-quality results with a much smaller amount of context. This can lead to significant efficiency gains, making LLMs more practical for real-world applications with limited computational resources.
The researchers demonstrated the effectiveness of their approach on a range of language tasks, showing that the compressed prompts could maintain performance while reducing the amount of context information required. This work represents an important step towards making large language models more practical and accessible for a wider range of applications.
Technical Explanation
The paper proposes a method for adapting large language models (LLMs) to process context more efficiently through "soft prompt compression". The key idea is to use reinforcement learning to learn a compressed version of the input prompt that can be used to condition the LLM, allowing it to generate relevant outputs while processing less overall context.
The authors first train a prompt compression model using reinforcement learning. This model takes the original input prompt and learns to produce a compressed version that retains the most relevant information for the target task. The compressed prompt is then used to condition the LLM, which generates the final output.
To train the prompt compression model, the authors use a reward function that encourages the model to produce compressed prompts that maintain high performance on the target task while minimizing the amount of context information required. This is achieved through a combination of task-specific rewards (e.g., perplexity on a language modeling task) and compression-specific rewards (e.g., the length of the compressed prompt).
The authors demonstrate the effectiveness of their approach on a range of language tasks, including language modeling, question answering, and text generation. Their results show that the compressed prompts can maintain performance while significantly reducing the amount of context information required, leading to substantial efficiency gains.
One key aspect of the proposed approach is the ability to transfer the learned prompt compression model to new tasks. The authors show that the compressed prompts learned on one task can be effectively applied to other tasks, further improving efficiency and reducing the need for task-specific prompt engineering.
Critical Analysis
The paper presents a compelling approach for adapting large language models to process context more efficiently through soft prompt compression. The authors have clearly demonstrated the effectiveness of their method on a range of language tasks, showing that it can maintain model performance while significantly reducing the amount of context information required.
One potential limitation of the approach is that the prompt compression model needs to be trained for each task separately, which could be computationally expensive. The authors do address this by showing that the compressed prompts can be effectively transferred to new tasks, but there may still be some overhead in fine-tuning the prompt compression model for each new application.
Additionally, the paper does not explore the potential limitations or edge cases of the soft prompt compression approach. It would be interesting to see how the method performs on more complex or noisy input data, or how it scales to extremely long input contexts.
Despite these minor concerns, the research presented in this paper represents an important step forward in making large language models more efficient and practical for real-world applications. The ability to reduce context processing requirements while maintaining performance is a significant development that could have far-reaching implications for the field of natural language processing.
Conclusion
This paper introduces a novel approach for adapting large language models to process context more efficiently through "soft prompt compression". By using reinforcement learning to learn compressed versions of input prompts, the researchers were able to significantly reduce the amount of context information required by the LLM while maintaining high performance on a range of language tasks.
The key innovation of this work is the ability to learn compressed prompts that capture the most relevant information for a given task, allowing the LLM to generate relevant outputs without needing to process the full input context. This technique has the potential to make large language models more practical and accessible for a wider range of real-world applications, where computational resources are often limited.
Overall, this research represents an important step forward in the ongoing effort to make large language models more efficient and scalable. By developing methods like soft prompt compression, the authors have demonstrated that it is possible to unlock the impressive capabilities of LLMs while addressing some of the key challenges around computational cost and efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
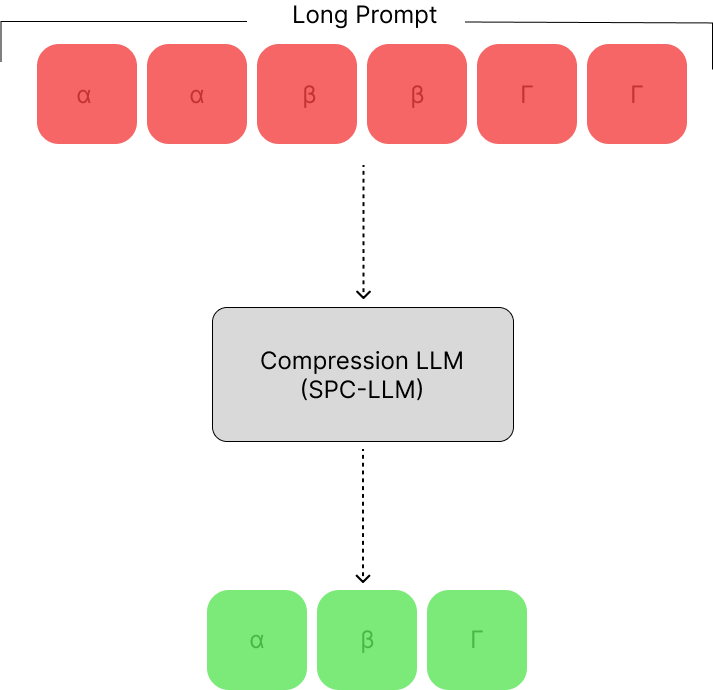
Learning to Compress Prompt in Natural Language Formats
Yu-Neng Chuang, Tianwei Xing, Chia-Yuan Chang, Zirui Liu, Xun Chen, Xia Hu
0
0
Large language models (LLMs) are great at processing multiple natural language processing tasks, but their abilities are constrained by inferior performance with long context, slow inference speed, and the high cost of computing the results. Deploying LLMs with precise and informative context helps users process large-scale datasets more effectively and cost-efficiently. Existing works rely on compressing long prompt contexts into soft prompts. However, soft prompt compression encounters limitations in transferability across different LLMs, especially API-based LLMs. To this end, this work aims to compress lengthy prompts in the form of natural language with LLM transferability. This poses two challenges: (i) Natural Language (NL) prompts are incompatible with back-propagation, and (ii) NL prompts lack flexibility in imposing length constraints. In this work, we propose a Natural Language Prompt Encapsulation (Nano-Capsulator) framework compressing original prompts into NL formatted Capsule Prompt while maintaining the prompt utility and transferability. Specifically, to tackle the first challenge, the Nano-Capsulator is optimized by a reward function that interacts with the proposed semantics preserving loss. To address the second question, the Nano-Capsulator is optimized by a reward function featuring length constraints. Experimental results demonstrate that the Capsule Prompt can reduce 81.4% of the original length, decrease inference latency up to 4.5x, and save 80.1% of budget overheads while providing transferability across diverse LLMs and different datasets.
4/3/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024
📉
CSEPrompts: A Benchmark of Introductory Computer Science Prompts
Nishat Raihan, Dhiman Goswami, Sadiya Sayara Chowdhury Puspo, Christian Newman, Tharindu Ranasinghe, Marcos Zampieri
0
0
Recent advances in AI, machine learning, and NLP have led to the development of a new generation of Large Language Models (LLMs) that are trained on massive amounts of data and often have trillions of parameters. Commercial applications (e.g., ChatGPT) have made this technology available to the general public, thus making it possible to use LLMs to produce high-quality texts for academic and professional purposes. Schools and universities are aware of the increasing use of AI-generated content by students and they have been researching the impact of this new technology and its potential misuse. Educational programs in Computer Science (CS) and related fields are particularly affected because LLMs are also capable of generating programming code in various programming languages. To help understand the potential impact of publicly available LLMs in CS education, we introduce CSEPrompts, a framework with hundreds of programming exercise prompts and multiple-choice questions retrieved from introductory CS and programming courses. We also provide experimental results on CSEPrompts to evaluate the performance of several LLMs with respect to generating Python code and answering basic computer science and programming questions.
4/5/2024
↗️
New!Enhancing Small Medical Learners with Privacy-preserving Contextual Prompting
Xinlu Zhang, Shiyang Li, Xianjun Yang, Chenxin Tian, Yao Qin, Linda Ruth Petzold
0
0
Large language models (LLMs) demonstrate remarkable medical expertise, but data privacy concerns impede their direct use in healthcare environments. Although offering improved data privacy protection, domain-specific small language models (SLMs) often underperform LLMs, emphasizing the need for methods that reduce this performance gap while alleviating privacy concerns. In this paper, we present a simple yet effective method that harnesses LLMs' medical proficiency to boost SLM performance in medical tasks under privacy-restricted scenarios. Specifically, we mitigate patient privacy issues by extracting keywords from medical data and prompting the LLM to generate a medical knowledge-intensive context by simulating clinicians' thought processes. This context serves as additional input for SLMs, augmenting their decision-making capabilities. Our method significantly enhances performance in both few-shot and full training settings across three medical knowledge-intensive tasks, achieving up to a 22.57% increase in absolute accuracy compared to SLM fine-tuning without context, and sets new state-of-the-art results in two medical tasks within privacy-restricted scenarios. Further out-of-domain testing and experiments in two general domain datasets showcase its generalizability and broad applicability. Our code can be found at https://github.com/XZhang97666/PrivacyBoost-SLM.
5/17/2024