Learning to Compress Prompt in Natural Language Formats
2402.18700
0
0
Abstract
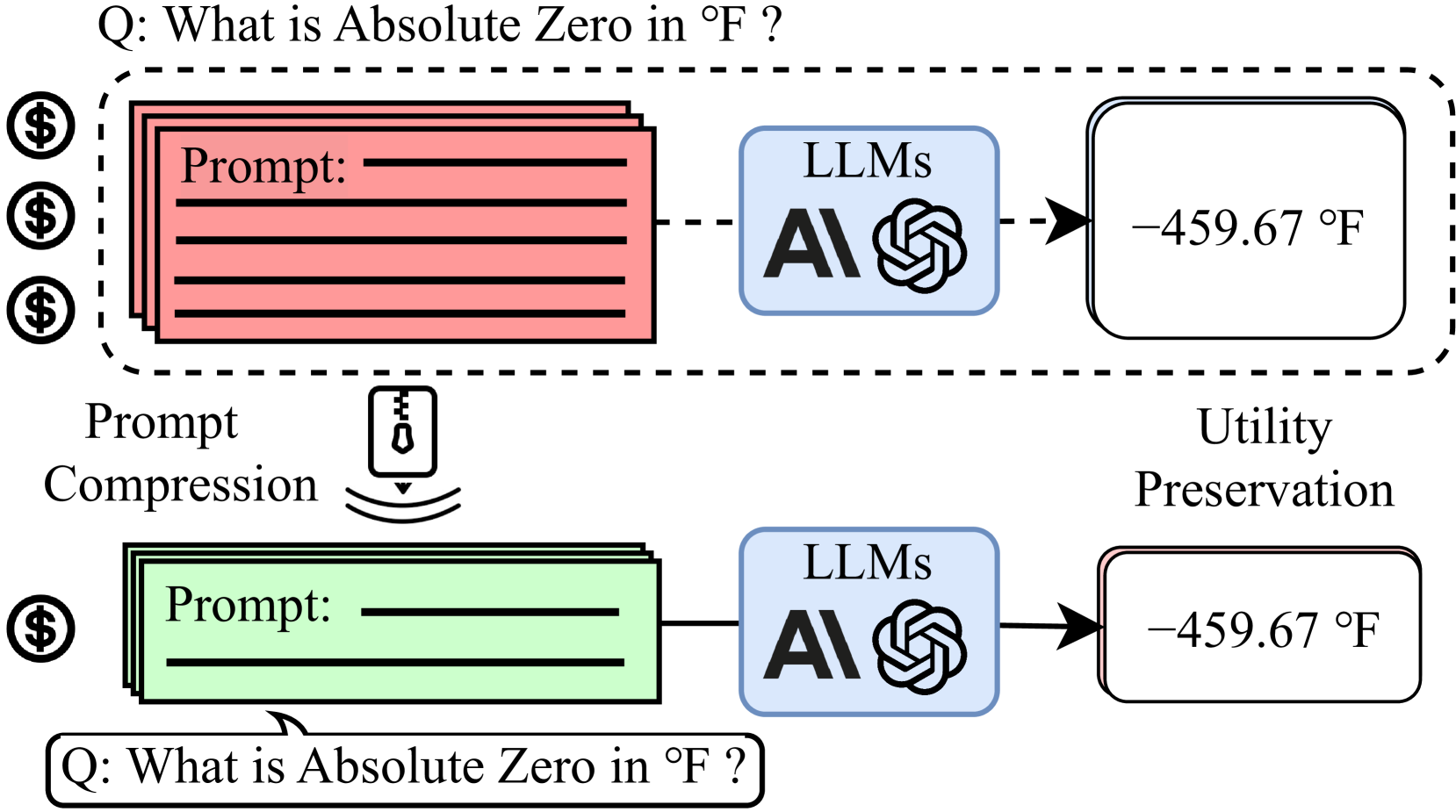
Large language models (LLMs) are great at processing multiple natural language processing tasks, but their abilities are constrained by inferior performance with long context, slow inference speed, and the high cost of computing the results. Deploying LLMs with precise and informative context helps users process large-scale datasets more effectively and cost-efficiently. Existing works rely on compressing long prompt contexts into soft prompts. However, soft prompt compression encounters limitations in transferability across different LLMs, especially API-based LLMs. To this end, this work aims to compress lengthy prompts in the form of natural language with LLM transferability. This poses two challenges: (i) Natural Language (NL) prompts are incompatible with back-propagation, and (ii) NL prompts lack flexibility in imposing length constraints. In this work, we propose a Natural Language Prompt Encapsulation (Nano-Capsulator) framework compressing original prompts into NL formatted Capsule Prompt while maintaining the prompt utility and transferability. Specifically, to tackle the first challenge, the Nano-Capsulator is optimized by a reward function that interacts with the proposed semantics preserving loss. To address the second question, the Nano-Capsulator is optimized by a reward function featuring length constraints. Experimental results demonstrate that the Capsule Prompt can reduce 81.4% of the original length, decrease inference latency up to 4.5x, and save 80.1% of budget overheads while providing transferability across diverse LLMs and different datasets.
Create account to get full access
Overview
• The paper explores a novel approach to compressing prompts in natural language formats, which could have implications for efficient language model fine-tuning and prompt engineering.
• The proposed method learns to compress prompts while preserving their semantic meaning, enabling more concise and flexible representations.
• Key experiments evaluate the effectiveness of the compression technique across a range of language tasks and model architectures.
Plain English Explanation
The paper looks at a new way to make text-based instructions, or "prompts," more concise without losing their meaning. Prompts are used to fine-tune or customize large language models like GPT-3 for specific tasks. However, storing and managing all the different prompts required can be challenging.
The researchers developed a technique that can automatically compress prompts down to a more compact form, while still preserving the core ideas and semantics. This compressed prompt can then be used to control the language model, potentially saving storage space and making prompt engineering more efficient.
The key insight is that not all parts of a prompt are equally important - some words and phrases contribute more to the overall meaning than others. By intelligently identifying and retaining the most essential elements, the compressed prompt can capture the essence of the original while taking up less space.
The researchers tested this compression approach across various language tasks and model architectures, demonstrating its versatility and effectiveness. This suggests the technique could be a valuable tool for developers working on prompt-based applications, such as chatbots, text generation, and knowledge distillation.
Technical Explanation
The paper proposes a framework for learning to compress natural language prompts while preserving their semantic meaning. The core idea is to train a neural network-based "prompt compressor" that can take an input prompt and output a more concise representation, without losing the essential information required to control the target language model.
The compressor model consists of an encoder that maps the input prompt to a latent code, and a decoder that reconstructs the original prompt from this compressed representation. The authors employ a contrastive loss function to ensure the compressed code retains the key semantic and syntactic information.
Experiments are conducted on a range of language tasks, including text classification, question answering, and few-shot learning. The compressed prompts are evaluated both in terms of their size reduction and the downstream task performance when used to fine-tune large language models like GPT-3.
The results demonstrate that the proposed compression approach can achieve significant size reductions (up to 75%) while maintaining comparable or even improved task performance compared to the original prompts. This suggests the technique allows for more efficient storage and management of prompts, with broader implications for prompt engineering and language model fine-tuning.
Critical Analysis
The paper presents a well-designed and thorough investigation into prompt compression, addressing an important challenge in the field of large language model customization. The core technical approach is sound, drawing on established neural network architectures and optimization techniques.
One potential limitation is the reliance on task-specific training data for the prompt compressor model. While the authors show the approach generalizes across different tasks, the compression may not be as effective if applied to prompts that are very different from the training data. Further research could explore more universal compression techniques or unsupervised approaches.
Additionally, the paper does not delve into potential privacy or security concerns that could arise from the ability to compress and store prompts more efficiently. As these models become more widely deployed, it will be important to consider the implications of compact prompt representations, such as the risk of prompt injection attacks or the leakage of sensitive information.
Overall, the work represents a valuable contribution to the field of prompt engineering and language model customization. The compression technique offers a promising avenue for improving the scalability and flexibility of prompt-based applications, warranting further investigation and refinement.
Conclusion
This paper introduces a novel approach for compressing natural language prompts while preserving their semantic meaning. The proposed method leverages a neural network-based compressor model to learn a more concise representation of prompts, enabling more efficient storage and management of prompts used to fine-tune large language models.
Extensive experiments demonstrate the effectiveness of the compression technique, achieving significant size reductions without compromising downstream task performance. This suggests the approach could have important implications for a wide range of prompt-based applications, from chatbots and text generation to knowledge distillation and few-shot learning.
While the current work represents a promising step forward, further research will be needed to address potential limitations and explore the broader implications of efficient prompt compression. Nonetheless, this paper makes a valuable contribution to the ongoing efforts to enhance the flexibility and scalability of large language models through improved prompt engineering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
Cangqing Wang, Yutian Yang, Ruisi Li, Dan Sun, Ruicong Cai, Yuzhu Zhang, Chengqian Fu, Lillian Floyd
0
0
The rapid advancement of Large Language Models (LLMs) has inaugurated a transformative epoch in natural language processing, fostering unprecedented proficiency in text generation, comprehension, and contextual scrutiny. Nevertheless, effectively handling extensive contexts, crucial for myriad applications, poses a formidable obstacle owing to the intrinsic constraints of the models' context window sizes and the computational burdens entailed by their operations. This investigation presents an innovative framework that strategically tailors LLMs for streamlined context processing by harnessing the synergies among natural language summarization, soft prompt compression, and augmented utility preservation mechanisms. Our methodology, dubbed SoftPromptComp, amalgamates natural language prompts extracted from summarization methodologies with dynamically generated soft prompts to forge a concise yet semantically robust depiction of protracted contexts. This depiction undergoes further refinement via a weighting mechanism optimizing information retention and utility for subsequent tasks. We substantiate that our framework markedly diminishes computational overhead and enhances LLMs' efficacy across various benchmarks, while upholding or even augmenting the caliber of the produced content. By amalgamating soft prompt compression with sophisticated summarization, SoftPromptComp confronts the dual challenges of managing lengthy contexts and ensuring model scalability. Our findings point towards a propitious trajectory for augmenting LLMs' applicability and efficiency, rendering them more versatile and pragmatic for real-world applications. This research enriches the ongoing discourse on optimizing language models, providing insights into the potency of soft prompts and summarization techniques as pivotal instruments for the forthcoming generation of NLP solutions.
4/22/2024
🏅
Discrete Prompt Compression with Reinforcement Learning
Hoyoun Jung, Kyung-Joong Kim
0
0
Compressed prompts aid instruction-tuned language models (LMs) in overcoming context window limitations and reducing computational costs. Existing methods, which primarily based on training embeddings, face various challenges associated with interpretability, the fixed number of embedding tokens, reusability across different LMs, and inapplicability when interacting with black-box APIs. This study proposes prompt compression with reinforcement learning (PCRL), which is a discrete prompt compression method that addresses these issues. The proposed PCRL method utilizes a computationally efficient policy network that edits prompts directly. The training approach employed in the proposed PCRLs can be applied flexibly to various types of LMs, including both decoder-only and encoder-decoder architecture and it can be trained without gradient access to the LMs or labeled data. The proposed PCRL achieves an average reduction of 24.6% in terms of the token count across various instruction prompts while maintaining sufficient performance. In addition, we demonstrate that the learned policy can be transferred to larger LMs, and through a comprehensive analysis, we explore the token importance within the prompts. Our code is accessible at https://github.com/nenomigami/PromptCompressor.
6/4/2024
SelfCP: Compressing Long Prompt to 1/12 Using the Frozen Large Language Model Itself
Jun Gao, Ziqiang Cao, Wenjie Li
0
0
Long prompt leads to huge hardware costs when using transformer-based Large Language Models (LLMs). Unfortunately, many tasks, such as summarization, inevitably introduce long documents, and the wide application of in-context learning easily makes the prompt length explode. This paper proposes a Self-Compressor (SelfCP), which employs the target LLM itself to compress over-limit prompts into dense vectors while keeping the allowed prompts unmodified. Dense vectors are then projected into dense tokens via a learnable connector to make the same LLM unburden to understand. The connector is supervised-tuned under the language modeling objective of the LLM on relatively long texts selected from publicly accessed datasets, involving an instruction dataset to make SelfCP respond to various prompts, while the target LLM keeps frozen during training. We build the lightweight SelfCP upon 2 different backbones with merely 17M learnable parameters originating from the connector and a learnable embedding. Evaluation on both English and Chinese benchmarks demonstrate that SelfCP effectively substitutes 12$times$ over-limit prompts with dense tokens to reduce memory costs and booster inference throughputs, yet improving response quality. The outstanding performance brings an efficient solution for LLMs to tackle long prompts without training LLMs from scratch.
6/19/2024
Automatic Prompt Selection for Large Language Models
Viet-Tung Do, Van-Khanh Hoang, Duy-Hung Nguyen, Shahab Sabahi, Jeff Yang, Hajime Hotta, Minh-Tien Nguyen, Hung Le
0
0
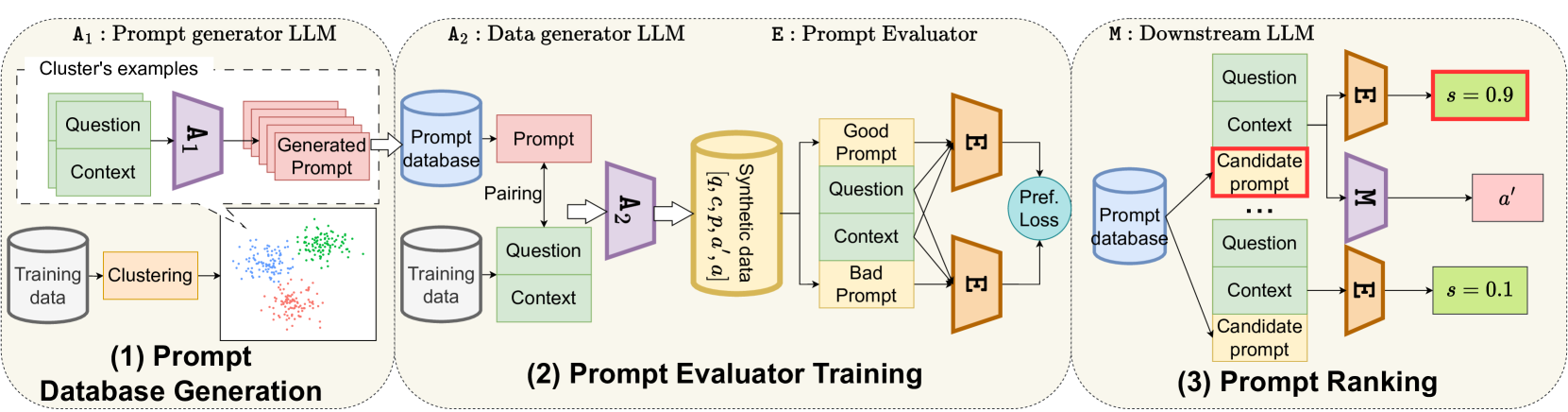
Large Language Models (LLMs) can perform various natural language processing tasks with suitable instruction prompts. However, designing effective prompts manually is challenging and time-consuming. Existing methods for automatic prompt optimization either lack flexibility or efficiency. In this paper, we propose an effective approach to automatically select the optimal prompt for a given input from a finite set of synthetic candidate prompts. Our approach consists of three steps: (1) clustering the training data and generating candidate prompts for each cluster using an LLM-based prompt generator; (2) synthesizing a dataset of input-prompt-output tuples for training a prompt evaluator to rank the prompts based on their relevance to the input; (3) using the prompt evaluator to select the best prompt for a new input at test time. Our approach balances prompt generality-specificity and eliminates the need for resource-intensive training and inference. It demonstrates competitive performance on zero-shot question-answering datasets: GSM8K, MultiArith, and AQuA.
4/4/2024