Adapting Multilingual LLMs to Low-Resource Languages with Knowledge Graphs via Adapters
2407.01406
0
0

Abstract
This paper explores the integration of graph knowledge from linguistic ontologies into multilingual Large Language Models (LLMs) using adapters to improve performance for low-resource languages (LRLs) in sentiment analysis (SA) and named entity recognition (NER). Building upon successful parameter-efficient fine-tuning techniques, such as K-ADAPTER and MAD-X, we propose a similar approach for incorporating knowledge from multilingual graphs, connecting concepts in various languages with each other through linguistic relationships, into multilingual LLMs for LRLs. Specifically, we focus on eight LRLs -- Maltese, Bulgarian, Indonesian, Nepali, Javanese, Uyghur, Tibetan, and Sinhala -- and employ language-specific adapters fine-tuned on data extracted from the language-specific section of ConceptNet, aiming to enable knowledge transfer across the languages covered by the knowledge graph. We compare various fine-tuning objectives, including standard Masked Language Modeling (MLM), MLM with full-word masking, and MLM with targeted masking, to analyse their effectiveness in learning and integrating the extracted graph data. Through empirical evaluation on language-specific tasks, we assess how structured graph knowledge affects the performance of multilingual LLMs for LRLs in SA and NER, providing insights into the potential benefits of adapting language models for low-resource scenarios.
Create account to get full access
Overview
• This paper explores a method for adapting large language models (LLMs) to low-resource languages using knowledge graphs and adapter modules.
• The researchers aim to address the challenge of deploying multilingual LLMs in real-world scenarios, where many languages have limited training data available.
• The proposed approach leverages existing knowledge graphs to infuse language-specific knowledge into the LLM, enabling it to perform well on tasks in low-resource languages.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have shown impressive abilities in understanding and generating human-like text. However, these models are typically trained on data from high-resource languages, such as English, which limits their performance on low-resource languages with limited available data.
To address this issue, the researchers in this paper present a novel method for adapting multilingual LLMs to work better with low-resource languages. The key idea is to use knowledge graphs - structured databases of information about the world - to inject language-specific knowledge into the LLM.
The process works like this: First, the researchers take a pre-trained multilingual LLM and add "adapter" modules - small neural network layers that can be trained to adapt the model to a specific language or task. Then, they use knowledge graphs relevant to the low-resource language to guide the training of these adapters, helping the model learn important facts and relationships about that language and culture.
By combining the power of a multilingual LLM with targeted, knowledge-infused adaptation, the researchers are able to improve the model's performance on tasks in low-resource languages, such as question answering or text generation. This could have important applications in making AI systems more accessible and useful for a wider range of global users.
Technical Explanation
The key technical contribution of this paper is a method for adapting large multilingual language models (LLMs) to perform well on tasks in low-resource languages. The researchers leverage knowledge graphs - structured databases of information about entities, concepts, and their relationships - to infuse language-specific knowledge into the LLM through the use of adapter modules.
Specifically, the researchers start with a pre-trained multilingual LLM, such as mBERT or XLM-R. They then add small adapter modules - extra neural network layers that can be trained to specialize the LLM for a particular language or task.
To adapt the LLM to a low-resource language, the researchers use a relevant knowledge graph, such as Wikidata, to extract language-specific information. This knowledge is then used to guide the training of the adapter modules, helping the model learn important facts, entities, and relationships about the target language and culture.
The researchers evaluate their approach on several low-resource language tasks, including named entity recognition, question answering, and text generation. They find that the knowledge-infused adapters lead to substantial performance improvements compared to simply fine-tuning the base LLM or using other adapter-based approaches like MAD-X and LoRA.
Critical Analysis
The researchers provide a thoughtful and thorough evaluation of their proposed approach, exploring its effectiveness across a range of low-resource language tasks and model configurations. However, a few potential limitations are worth considering:
First, the reliance on existing knowledge graphs may constrain the approach to the information and biases present in those resources. Additional work may be needed to ensure the knowledge being infused is comprehensive and unbiased.
Second, the paper does not explore the scalability of the approach as the number of target languages increases. Adapting the LLM for dozens or hundreds of low-resource languages could become computationally expensive and complex to manage.
Finally, the researchers acknowledge that their method may not be as effective for extremely low-resource languages with very limited data and resources available. Further innovations may be needed to truly democratize language model capabilities across the global linguistic landscape.
Conclusion
This paper presents a promising approach for adapting powerful multilingual language models to perform well on tasks in low-resource languages. By leveraging knowledge graphs to infuse targeted linguistic and cultural knowledge into the model, the researchers are able to significantly improve performance on a variety of downstream tasks.
The ability to make LLMs more accessible and useful for a wider range of global users is an important step towards building AI systems that can truly serve the diverse needs of humanity. While the proposed method has some limitations, it represents an important advance in the field of multilingual natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
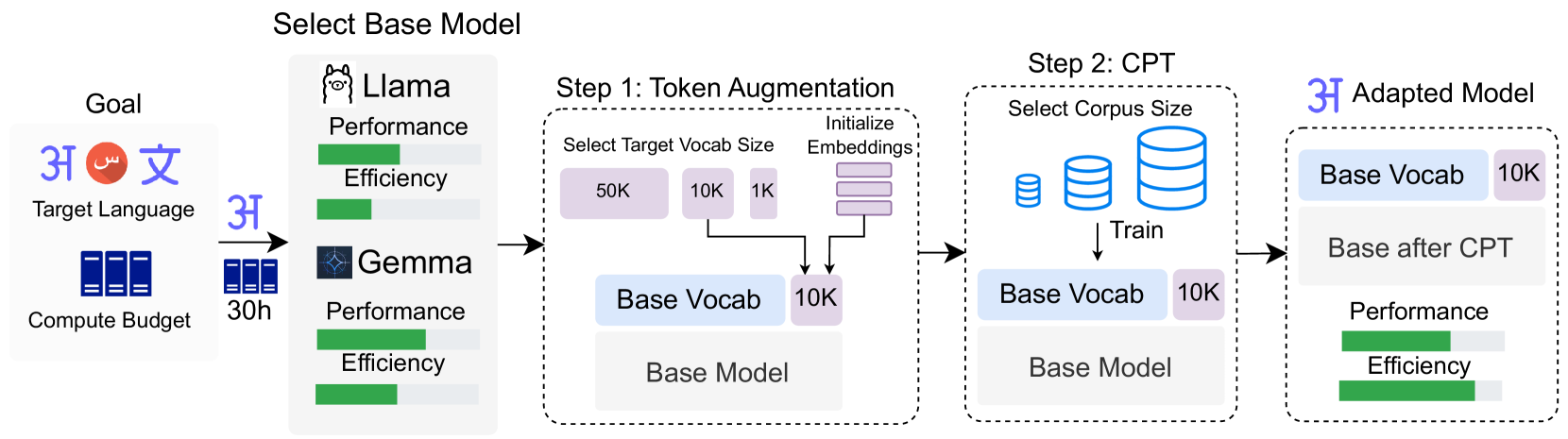
Exploring Design Choices for Building Language-Specific LLMs
Atula Tejaswi, Nilesh Gupta, Eunsol Choi
0
0
Despite rapid progress in large language models (LLMs), their performance on a vast majority of languages remain unsatisfactory. In this paper, we study building language-specific LLMs by adapting monolingual and multilingual LLMs. We conduct systematic experiments on how design choices (base model selection, vocabulary extension, and continued fine-tuning) impact the adapted LLM, both in terms of efficiency (how many tokens are needed to encode the same amount of information) and end task performance. We find that (1) the initial performance before the adaptation is not always indicative of the final performance. (2) Efficiency can easily improved with simple vocabulary extension and continued fine-tuning in most LLMs we study, and (3) The optimal adaptation method is highly language-dependent, and the simplest approach works well across various experimental settings. Adapting English-centric models can yield better results than adapting multilingual models despite their worse initial performance on low-resource languages. Together, our work lays foundations on efficiently building language-specific LLMs by adapting existing LLMs.
6/24/2024
Cross-Lingual Transfer Robustness to Lower-Resource Languages on Adversarial Datasets
Shadi Manafi, Nikhil Krishnaswamy
0
0
Multilingual Language Models (MLLMs) exhibit robust cross-lingual transfer capabilities, or the ability to leverage information acquired in a source language and apply it to a target language. These capabilities find practical applications in well-established Natural Language Processing (NLP) tasks such as Named Entity Recognition (NER). This study aims to investigate the effectiveness of a source language when applied to a target language, particularly in the context of perturbing the input test set. We evaluate on 13 pairs of languages, each including one high-resource language (HRL) and one low-resource language (LRL) with a geographic, genetic, or borrowing relationship. We evaluate two well-known MLLMs--MBERT and XLM-R--on these pairs, in native LRL and cross-lingual transfer settings, in two tasks, under a set of different perturbations. Our findings indicate that NER cross-lingual transfer depends largely on the overlap of entity chunks. If a source and target language have more entities in common, the transfer ability is stronger. Models using cross-lingual transfer also appear to be somewhat more robust to certain perturbations of the input, perhaps indicating an ability to leverage stronger representations derived from the HRL. Our research provides valuable insights into cross-lingual transfer and its implications for NLP applications, and underscores the need to consider linguistic nuances and potential limitations when employing MLLMs across distinct languages.
4/1/2024
💬
MedAdapter: Efficient Test-Time Adaptation of Large Language Models towards Medical Reasoning
Wenqi Shi, Ran Xu, Yuchen Zhuang, Yue Yu, Hang Wu, Carl Yang, May D. Wang
0
0
Despite their improved capabilities in generation and reasoning, adapting large language models (LLMs) to the biomedical domain remains challenging due to their immense size and corporate privacy. In this work, we propose MedAdapter, a unified post-hoc adapter for test-time adaptation of LLMs towards biomedical applications. Instead of fine-tuning the entire LLM, MedAdapter effectively adapts the original model by fine-tuning only a small BERT-sized adapter to rank candidate solutions generated by LLMs. Experiments demonstrate that MedAdapter effectively adapts both white-box and black-box LLMs in biomedical reasoning, achieving average performance improvements of 25.48% and 11.31%, respectively, without requiring extensive computational resources or sharing data with third parties. MedAdapter also yields superior performance when combined with train-time adaptation, highlighting a flexible and complementary solution to existing adaptation methods. Faced with the challenges of balancing model performance, computational resources, and data privacy, MedAdapter provides an efficient, privacy-preserving, cost-effective, and transparent solution for adapting LLMs to the biomedical domain.
5/7/2024

Bridging the Gap: Dynamic Learning Strategies for Improving Multilingual Performance in LLMs
Somnath Kumar, Vaibhav Balloli, Mercy Ranjit, Kabir Ahuja, Tanuja Ganu, Sunayana Sitaram, Kalika Bali, Akshay Nambi
0
0
Large language models (LLMs) are at the forefront of transforming numerous domains globally. However, their inclusivity and effectiveness remain limited for non-Latin scripts and low-resource languages. This paper tackles the imperative challenge of enhancing the multilingual performance of LLMs without extensive training or fine-tuning. Through systematic investigation and evaluation of diverse languages using popular question-answering (QA) datasets, we present novel techniques that unlock the true potential of LLMs in a polyglot landscape. Our approach encompasses three key strategies that yield significant improvements in multilingual proficiency. First, by meticulously optimizing prompts tailored for polyglot LLMs, we unlock their latent capabilities, resulting in substantial performance boosts across languages. Second, we introduce a new hybrid approach that synergizes LLM Retrieval Augmented Generation (RAG) with multilingual embeddings and achieves improved multilingual task performance. Finally, we introduce a novel learning approach that dynamically selects the optimal prompt strategy, LLM model, and embedding model per query at run-time. This dynamic adaptation maximizes the efficacy of LLMs across languages, outperforming best static and random strategies. Additionally, our approach adapts configurations in both offline and online settings, and can seamlessly adapt to new languages and datasets, leading to substantial advancements in multilingual understanding and generation across diverse languages.
5/29/2024