Adapting Short-Term Transformers for Action Detection in Untrimmed Videos

0
Sign in to get full access
Overview
- This paper proposes a novel method for adapting short-term transformer models to improve action detection in untrimmed videos.
- The authors address the challenge of effectively capturing long-range temporal dependencies in action detection tasks, which is crucial for understanding complex actions.
- The proposed approach combines the strengths of short-term transformers and various temporal modeling techniques to enhance the performance of action detection in unconstrained, real-world videos.
Plain English Explanation
The paper focuses on improving the ability of transformer-based models to detect actions in unedited, real-world video recordings. Transformer models have shown great success in various computer vision tasks, but they can struggle to capture the long-term temporal relationships that are crucial for accurately recognizing complex actions in the context of a full video.
The researchers developed a new method that combines the power of short-term transformer models with additional techniques for modeling temporal information. This allows the model to better understand the sequence of events and interactions happening over the course of a video, leading to more accurate detection of the actions taking place.
By adapting transformer architectures to work more effectively with the unique challenges of video data, the authors aim to push the boundaries of what is possible in the field of action recognition. This could have valuable applications in areas like video surveillance, sports analysis, and human-computer interaction, where the ability to understand and track actions is crucial.
Technical Explanation
The paper presents a novel approach to adapt short-term transformer models for the task of action detection in untrimmed videos. Transformers have demonstrated impressive performance in various computer vision tasks, but their ability to capture long-range temporal dependencies, which is essential for understanding complex actions in videos, is limited.
To address this, the authors propose a multi-stage architecture that combines the strengths of short-term transformers with additional temporal modeling techniques. The first stage uses a short-term transformer to extract local-level feature representations from the video, capturing the short-term dynamics of individual actions. This is followed by a temporal modeling stage that leverages techniques like TAM-VT and ActNetFormer to model longer-range temporal dependencies and capture the broader context of the action sequences.
The authors also incorporate a set of auxiliary losses, such as action classification and temporal localization, to further guide the model towards learning robust representations for action detection. This multi-task learning approach helps the model better understand the temporal structure of the video and improve its overall performance.
The paper validates the effectiveness of the proposed method through extensive experiments on widely used action detection benchmarks, such as THUMOS14 and ActivityNet. The results demonstrate significant improvements over state-of-the-art action detection models, highlighting the benefits of adapting short-term transformer architectures to the unique challenges of video data.
Critical Analysis
The authors have presented a well-designed and comprehensive approach to addressing the limitations of short-term transformers in the context of action detection in untrimmed videos. The incorporation of various temporal modeling techniques, such as TAM-VT and ActNetFormer, is a promising direction to enhance the ability of transformer models to capture long-range temporal dependencies.
However, the paper does not provide a detailed analysis of the computational complexity and inference time of the proposed approach, which could be an important consideration for real-world applications. Additionally, the authors could have explored the generalization capabilities of the model by evaluating its performance on a more diverse set of action detection datasets, including those with different types of videos and action categories.
Furthermore, the paper would have benefited from a more in-depth discussion of the potential limitations and future research directions. For example, the authors could have explored how the model might handle cases where the temporal structure of the video is more ambiguous or where multiple actions are occurring simultaneously.
Conclusion
This paper presents a novel approach to adapting short-term transformer models for the task of action detection in untrimmed videos. By combining the strengths of transformers with additional temporal modeling techniques, the proposed method demonstrates significant improvements in action detection performance on benchmark datasets.
The authors' work highlights the importance of addressing the unique challenges of video data in the context of transformer-based models, which have shown great promise in various computer vision tasks. The insights and techniques developed in this paper could have far-reaching implications for the field of video understanding, with potential applications in areas such as video surveillance, sports analysis, and moment retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adapting Short-Term Transformers for Action Detection in Untrimmed Videos
Min Yang, Huan Gao, Ping Guo, Limin Wang
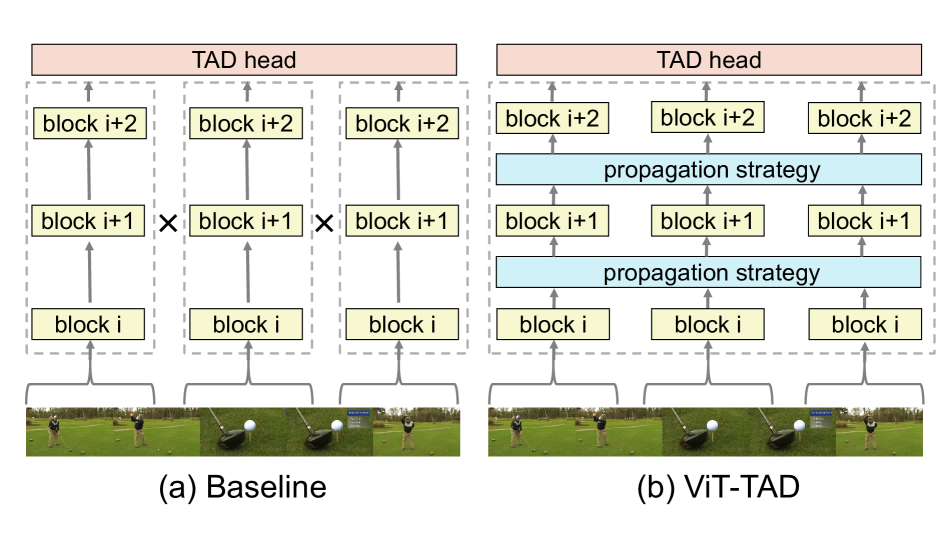
Vision Transformer (ViT) has shown high potential in video recognition, owing to its flexible design, adaptable self-attention mechanisms, and the efficacy of masked pre-training. Yet, it remains unclear how to adapt these pre-trained short-term ViTs for temporal action detection (TAD) in untrimmed videos. The existing works treat them as off-the-shelf feature extractors for each short-trimmed snippet without capturing the fine-grained relation among different snippets in a broader temporal context. To mitigate this issue, this paper focuses on designing a new mechanism for adapting these pre-trained ViT models as a unified long-form video transformer to fully unleash its modeling power in capturing inter-snippet relation, while still keeping low computation overhead and memory consumption for efficient TAD. To this end, we design effective cross-snippet propagation modules to gradually exchange short-term video information among different snippets from two levels. For inner-backbone information propagation, we introduce a cross-snippet propagation strategy to enable multi-snippet temporal feature interaction inside the backbone.For post-backbone information propagation, we propose temporal transformer layers for further clip-level modeling. With the plain ViT-B pre-trained with VideoMAE, our end-to-end temporal action detector (ViT-TAD) yields a very competitive performance to previous temporal action detectors, riching up to 69.5 average mAP on THUMOS14, 37.40 average mAP on ActivityNet-1.3 and 17.20 average mAP on FineAction.
Read more4/16/2024

0
Long-Term Pre-training for Temporal Action Detection with Transformers
Jihwan Kim, Miso Lee, Jae-Pil Heo
Temporal action detection (TAD) is challenging, yet fundamental for real-world video applications. Recently, DETR-based models for TAD have been prevailing thanks to their unique benefits. However, transformers demand a huge dataset, and unfortunately data scarcity in TAD causes a severe degeneration. In this paper, we identify two crucial problems from data scarcity: attention collapse and imbalanced performance. To this end, we propose a new pre-training strategy, Long-Term Pre-training (LTP), tailored for transformers. LTP has two main components: 1) class-wise synthesis, 2) long-term pretext tasks. Firstly, we synthesize long-form video features by merging video snippets of a target class and non-target classes. They are analogous to untrimmed data used in TAD, despite being created from trimmed data. In addition, we devise two types of long-term pretext tasks to learn long-term dependency. They impose long-term conditions such as finding second-to-fourth or short-duration actions. Our extensive experiments show state-of-the-art performances in DETR-based methods on ActivityNet-v1.3 and THUMOS14 by a large margin. Moreover, we demonstrate that LTP significantly relieves the data scarcity issues in TAD.
Read more9/10/2024

0
Harnessing Temporal Causality for Advanced Temporal Action Detection
Shuming Liu, Lin Sui, Chen-Lin Zhang, Fangzhou Mu, Chen Zhao, Bernard Ghanem
As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling for TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, we propose leveraging the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. We introduce CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. Notably, with CausalTAD, we ranked 1st in the Action Recognition, Action Detection, and Audio-Based Interaction Detection tracks at the EPIC-Kitchens Challenge 2024, as well as 1st in the Moment Queries track at the Ego4D Challenge 2024. Our code is available at https://github.com/sming256/OpenTAD/.
Read more7/29/2024

0
Introducing Gating and Context into Temporal Action Detection
Aglind Reka, Diana Laura Borza, Dominick Reilly, Michal Balazia, Francois Bremond
Temporal Action Detection (TAD), the task of localizing and classifying actions in untrimmed video, remains challenging due to action overlaps and variable action durations. Recent findings suggest that TAD performance is dependent on the structural design of transformers rather than on the self-attention mechanism. Building on this insight, we propose a refined feature extraction process through lightweight, yet effective operations. First, we employ a local branch that employs parallel convolutions with varying window sizes to capture both fine-grained and coarse-grained temporal features. This branch incorporates a gating mechanism to select the most relevant features. Second, we introduce a context branch that uses boundary frames as key-value pairs to analyze their relationship with the central frame through cross-attention. The proposed method captures temporal dependencies and improves contextual understanding. Evaluations of the gating mechanism and context branch on challenging datasets (THUMOS14 and EPIC-KITCHEN 100) show a consistent improvement over the baseline and existing methods.
Read more9/9/2024