Introducing Gating and Context into Temporal Action Detection

0

Sign in to get full access
Overview
- The paper introduces a novel approach called Gating and Context (GaC) for temporal action detection in videos.
- GaC incorporates gating mechanisms and contextual information to improve the performance of temporal action detection models.
- The paper presents experiments evaluating the GaC approach on several benchmark datasets, demonstrating its effectiveness compared to existing methods.
Plain English Explanation
The paper introduces a new way to detect and locate actions within a video. Detecting actions in videos is an important task, with applications in areas like video analysis and surveillance.
The key idea in this paper is to use "gating" and "context" to improve action detection. Gating allows the model to selectively focus on the most relevant information for detecting each action, rather than using all the information equally. And incorporating context provides the model with additional cues about what's happening around each action, which can help with localization.
The researchers tested their GaC approach on standard benchmark datasets for action detection, and found that it outperformed previous state-of-the-art methods. This suggests the gating and contextual mechanisms they introduced are effective at improving the accuracy and speed of detecting actions in videos.
Technical Explanation
The paper proposes a new architecture called Gating and Context (GaC) for temporal action detection. The key components are:
-
Gating Mechanism: This allows the model to selectively focus on the most relevant features for detecting each action, rather than treating all features equally.
-
Cross-Attention: This captures contextual information by modeling relationships between the action of interest and its surrounding video content.
The researchers evaluate GaC on several standard benchmarks for temporal action detection, including ActivityNet and THUMOS14. They find that GaC outperforms prior state-of-the-art methods in terms of both detection accuracy and inference speed.
The improvements are attributed to the gating and cross-attention mechanisms, which allow the model to better identify and localize the relevant actions within the video.
Critical Analysis
The paper provides a thorough empirical evaluation of the GaC approach, comparing it against multiple baselines on standard benchmarks. This lends strong support to the claims about its effectiveness.
However, the paper does not delve deeply into the limitations or potential drawbacks of the GaC approach. For example, it's unclear how the method would scale to very long videos or how robust it would be to video editing/manipulation.
Additionally, the paper focuses solely on improving temporal action detection, but does not explore how the gating and context mechanisms could be applied to other video understanding tasks, such as action recognition or video summarization. Investigating these broader applications could be a fruitful area for future research.
Overall, the paper makes a compelling case for the GaC approach, but there remain opportunities to further assess its strengths, weaknesses, and generalizability.
Conclusion
This paper introduces a novel Gating and Context (GaC) architecture that significantly improves the state-of-the-art in temporal action detection. By incorporating gating mechanisms to selectively focus on relevant features and cross-attention to model contextual information, GaC achieves superior performance on benchmark datasets compared to previous methods.
The technical innovations and empirical results presented in this work demonstrate the value of incorporating contextual cues and adaptive feature extraction for video understanding tasks. This could have broader implications for a range of applications, from video surveillance to sports analytics.
While the paper focuses on temporal action detection, the underlying principles of GaC may be applicable to other video-related tasks as well. Exploring these extensions could be an interesting direction for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Introducing Gating and Context into Temporal Action Detection
Aglind Reka, Diana Laura Borza, Dominick Reilly, Michal Balazia, Francois Bremond
Temporal Action Detection (TAD), the task of localizing and classifying actions in untrimmed video, remains challenging due to action overlaps and variable action durations. Recent findings suggest that TAD performance is dependent on the structural design of transformers rather than on the self-attention mechanism. Building on this insight, we propose a refined feature extraction process through lightweight, yet effective operations. First, we employ a local branch that employs parallel convolutions with varying window sizes to capture both fine-grained and coarse-grained temporal features. This branch incorporates a gating mechanism to select the most relevant features. Second, we introduce a context branch that uses boundary frames as key-value pairs to analyze their relationship with the central frame through cross-attention. The proposed method captures temporal dependencies and improves contextual understanding. Evaluations of the gating mechanism and context branch on challenging datasets (THUMOS14 and EPIC-KITCHEN 100) show a consistent improvement over the baseline and existing methods.
Read more9/9/2024

0
Harnessing Temporal Causality for Advanced Temporal Action Detection
Shuming Liu, Lin Sui, Chen-Lin Zhang, Fangzhou Mu, Chen Zhao, Bernard Ghanem
As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling for TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, we propose leveraging the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. We introduce CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. Notably, with CausalTAD, we ranked 1st in the Action Recognition, Action Detection, and Audio-Based Interaction Detection tracks at the EPIC-Kitchens Challenge 2024, as well as 1st in the Moment Queries track at the Ego4D Challenge 2024. Our code is available at https://github.com/sming256/OpenTAD/.
Read more7/29/2024

0
Leveraging Temporal Contextualization for Video Action Recognition
Minji Kim, Dongyoon Han, Taekyung Kim, Bohyung Han
We propose a novel framework for video understanding, called Temporally Contextualized CLIP (TC-CLIP), which leverages essential temporal information through global interactions in a spatio-temporal domain within a video. To be specific, we introduce Temporal Contextualization (TC), a layer-wise temporal information infusion mechanism for videos, which 1) extracts core information from each frame, 2) connects relevant information across frames for the summarization into context tokens, and 3) leverages the context tokens for feature encoding. Furthermore, the Video-conditional Prompting (VP) module processes context tokens to generate informative prompts in the text modality. Extensive experiments in zero-shot, few-shot, base-to-novel, and fully-supervised action recognition validate the effectiveness of our model. Ablation studies for TC and VP support our design choices. Our project page with the source code is available at https://github.com/naver-ai/tc-clip
Read more7/25/2024
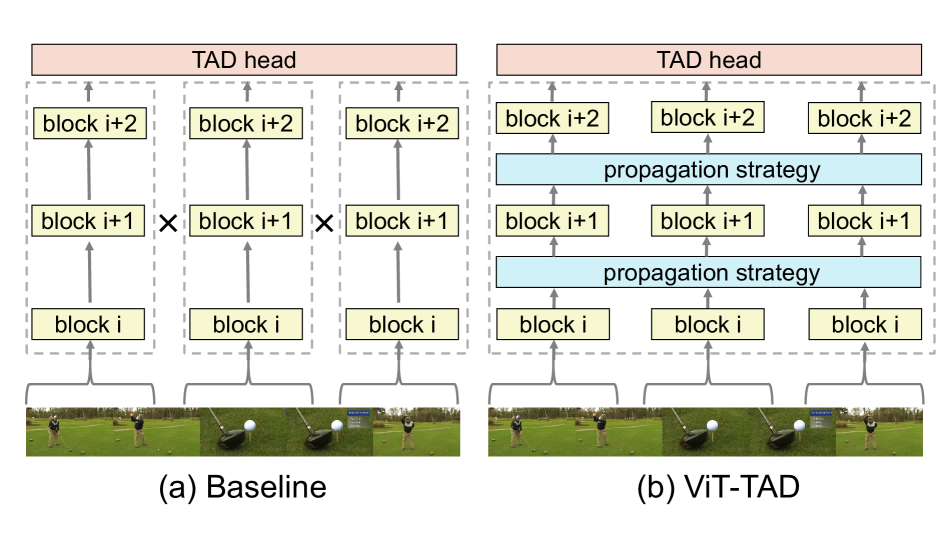
0
Adapting Short-Term Transformers for Action Detection in Untrimmed Videos
Min Yang, Huan Gao, Ping Guo, Limin Wang
Vision Transformer (ViT) has shown high potential in video recognition, owing to its flexible design, adaptable self-attention mechanisms, and the efficacy of masked pre-training. Yet, it remains unclear how to adapt these pre-trained short-term ViTs for temporal action detection (TAD) in untrimmed videos. The existing works treat them as off-the-shelf feature extractors for each short-trimmed snippet without capturing the fine-grained relation among different snippets in a broader temporal context. To mitigate this issue, this paper focuses on designing a new mechanism for adapting these pre-trained ViT models as a unified long-form video transformer to fully unleash its modeling power in capturing inter-snippet relation, while still keeping low computation overhead and memory consumption for efficient TAD. To this end, we design effective cross-snippet propagation modules to gradually exchange short-term video information among different snippets from two levels. For inner-backbone information propagation, we introduce a cross-snippet propagation strategy to enable multi-snippet temporal feature interaction inside the backbone.For post-backbone information propagation, we propose temporal transformer layers for further clip-level modeling. With the plain ViT-B pre-trained with VideoMAE, our end-to-end temporal action detector (ViT-TAD) yields a very competitive performance to previous temporal action detectors, riching up to 69.5 average mAP on THUMOS14, 37.40 average mAP on ActivityNet-1.3 and 17.20 average mAP on FineAction.
Read more4/16/2024