Adaptive Autopilot: Constrained DRL for Diverse Driving Behaviors

0
Sign in to get full access
Overview
- Presents an "Adaptive Autopilot" system that uses constrained deep reinforcement learning (DRL) to handle diverse driving behaviors
- Aims to develop an autopilot that can adapt to a variety of driving styles, from aggressive to cautious
- Evaluates the system in simulation and in real-world driving scenarios
Plain English Explanation
This research paper describes a new autopilot system that can adapt to different driving styles. The goal is to create an autopilot that can handle a wide range of driving behaviors, from aggressive and risky to cautious and conservative.
The researchers used a technique called "constrained deep reinforcement learning" to train the autopilot. This involves setting certain limits or "constraints" on the autopilot's actions to ensure it stays within safe and acceptable boundaries, while still allowing it to learn from experience and adapt to different driving situations.
By training the autopilot this way, the researchers were able to create a system that could navigate successfully in both simulated environments and real-world driving scenarios, regardless of the driver's preferred style. This could be useful for self-driving cars or advanced driver assistance systems that need to accommodate the diverse driving behaviors of different users.
Technical Explanation
The paper presents an "Adaptive Autopilot" system that uses constrained deep reinforcement learning (DRL) to handle a variety of driving behaviors. The goal is to develop an autopilot capable of adapting to diverse driving styles, from aggressive to cautious.
The system is evaluated in simulation as well as in real-world driving scenarios. The constrained DRL approach involves setting limits or "constraints" on the autopilot's actions to ensure safe and acceptable behavior, while still allowing it to learn and adapt from experience.
By training the autopilot with these constraints, the researchers were able to create a system that could successfully navigate a range of driving situations, regardless of the driver's preferred style. This could have applications for self-driving cars or advanced driver assistance systems that need to accommodate diverse user preferences.
Critical Analysis
The paper presents a novel approach to developing adaptive autopilot systems, but it acknowledges some limitations. The simulation and real-world evaluations were conducted in relatively controlled environments, and the system's performance may vary in more complex, real-world driving conditions.
Additionally, the paper does not provide a detailed analysis of the specific constraints used or how they were determined. Further research may be needed to understand the tradeoffs and optimal balance between allowing the autopilot to adapt and maintaining safe, acceptable behavior.
Nonetheless, the concept of using constrained DRL to create flexible, user-adaptive autopilot systems is an intriguing one that could have important implications for the future of autonomous and semi-autonomous vehicles. Continued research and development in this area may lead to more robust and versatile driving assistance technologies.
Conclusion
The "Adaptive Autopilot" system presented in this paper demonstrates a promising approach to creating autopilot systems that can adapt to diverse driving behaviors. By using constrained deep reinforcement learning, the researchers were able to develop an autopilot capable of navigating a range of simulated and real-world driving scenarios, regardless of the driver's preferred style.
This work could have significant implications for the development of self-driving cars and advanced driver assistance systems, as the ability to accommodate different user preferences and driving styles is a crucial requirement for widespread adoption and acceptance of these technologies. Further research and refinement of the constrained DRL approach may lead to even more robust and versatile autopilot systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Autopilot: Constrained DRL for Diverse Driving Behaviors
Dinesh Cyril Selvaraj, Christian Vitale, Tania Panayiotou, Panayiotis Kolios, Carla Fabiana Chiasserini, Georgios Ellinas
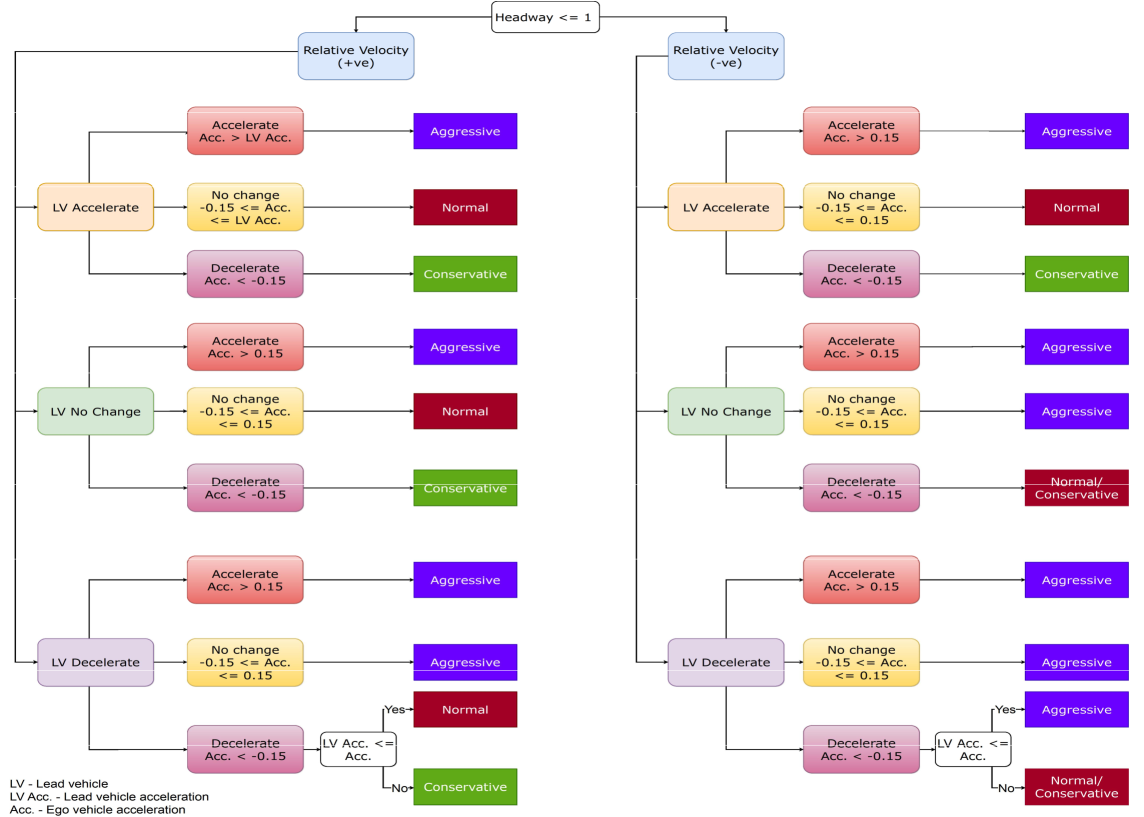
In pursuit of autonomous vehicles, achieving human-like driving behavior is vital. This study introduces adaptive autopilot (AA), a unique framework utilizing constrained-deep reinforcement learning (C-DRL). AA aims to safely emulate human driving to reduce the necessity for driver intervention. Focusing on the car-following scenario, the process involves (i) extracting data from the highD natural driving study and categorizing it into three driving styles using a rule-based classifier; (ii) employing deep neural network (DNN) regressors to predict human-like acceleration across styles; and (iii) using C-DRL, specifically the soft actor-critic Lagrangian technique, to learn human-like safe driving policies. Results indicate effectiveness in each step, with the rule-based classifier distinguishing driving styles, the regressor model accurately predicting acceleration, outperforming traditional car-following models, and C-DRL agents learning optimal policies for humanlike driving across styles.
Read more7/4/2024

0
HAIM-DRL: Enhanced Human-in-the-loop Reinforcement Learning for Safe and Efficient Autonomous Driving
Zilin Huang, Zihao Sheng, Chengyuan Ma, Sikai Chen
Despite significant progress in autonomous vehicles (AVs), the development of driving policies that ensure both the safety of AVs and traffic flow efficiency has not yet been fully explored. In this paper, we propose an enhanced human-in-the-loop reinforcement learning method, termed the Human as AI mentor-based deep reinforcement learning (HAIM-DRL) framework, which facilitates safe and efficient autonomous driving in mixed traffic platoon. Drawing inspiration from the human learning process, we first introduce an innovative learning paradigm that effectively injects human intelligence into AI, termed Human as AI mentor (HAIM). In this paradigm, the human expert serves as a mentor to the AI agent. While allowing the agent to sufficiently explore uncertain environments, the human expert can take control in dangerous situations and demonstrate correct actions to avoid potential accidents. On the other hand, the agent could be guided to minimize traffic flow disturbance, thereby optimizing traffic flow efficiency. In detail, HAIM-DRL leverages data collected from free exploration and partial human demonstrations as its two training sources. Remarkably, we circumvent the intricate process of manually designing reward functions; instead, we directly derive proxy state-action values from partial human demonstrations to guide the agents' policy learning. Additionally, we employ a minimal intervention technique to reduce the human mentor's cognitive load. Comparative results show that HAIM-DRL outperforms traditional methods in driving safety, sampling efficiency, mitigation of traffic flow disturbance, and generalizability to unseen traffic scenarios. The code and demo videos for this paper can be accessed at: https://zilin-huang.github.io/HAIM-DRL-website/
Read more6/18/2024
0
In-context Learning for Automated Driving Scenarios
Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Boyue Wang, Tianyu Shi, Alaa Khamis
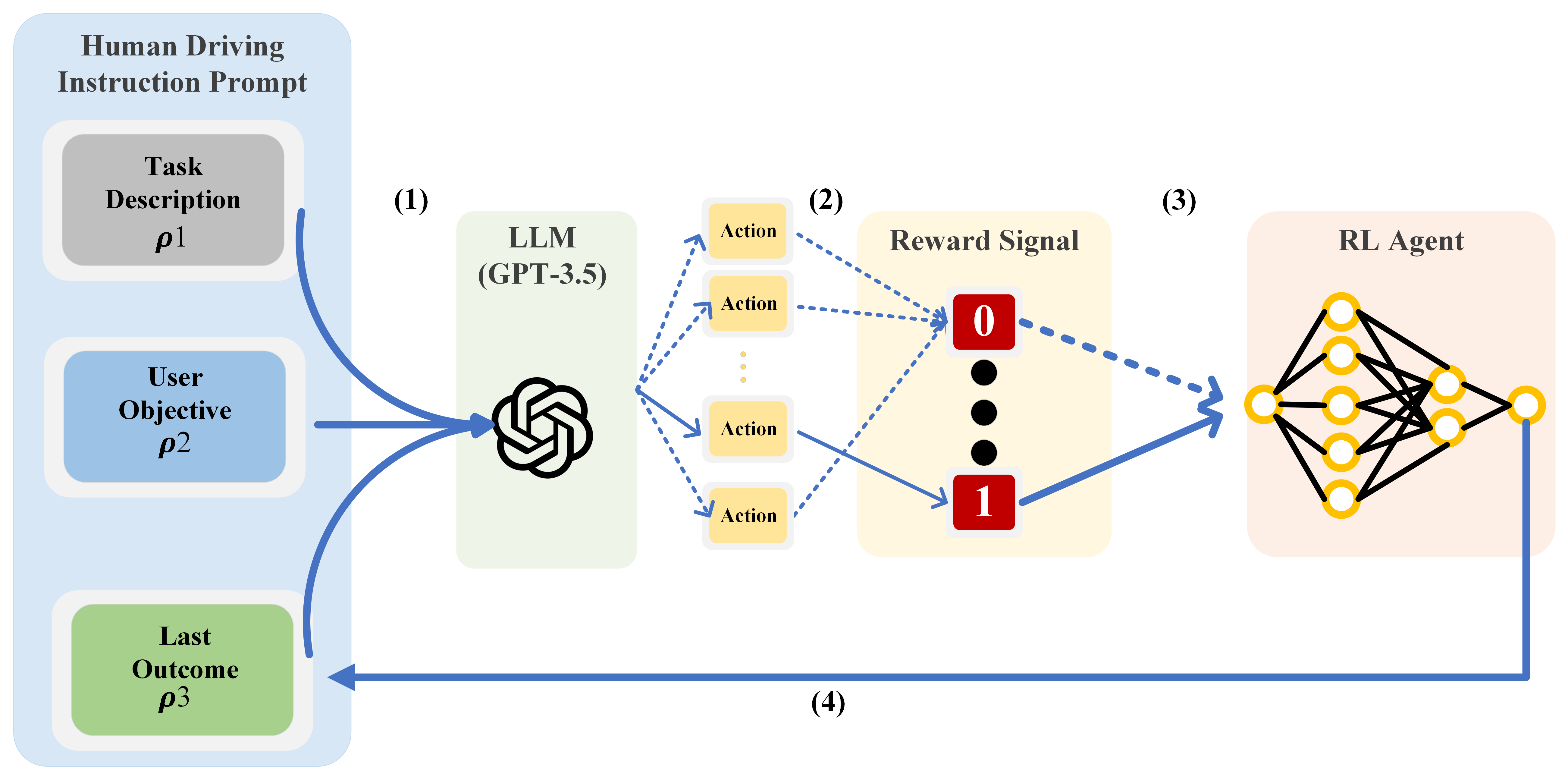
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
Read more5/8/2024
🔍
0
Autonomous Algorithm for Training Autonomous Vehicles with Minimal Human Intervention
Sang-Hyun Lee, Daehyeok Kwon, Seung-Woo Seo
Reinforcement learning (RL) provides a compelling framework for enabling autonomous vehicles to continue to learn and improve diverse driving behaviors on their own. However, training real-world autonomous vehicles with current RL algorithms presents several challenges. One critical challenge, often overlooked in these algorithms, is the need to reset a driving environment between every episode. While resetting an environment after each episode is trivial in simulated settings, it demands significant human intervention in the real world. In this paper, we introduce a novel autonomous algorithm that allows off-the-shelf RL algorithms to train an autonomous vehicle with minimal human intervention. Our algorithm takes into account the learning progress of the autonomous vehicle to determine when to abort episodes before it enters unsafe states and where to reset it for subsequent episodes in order to gather informative transitions. The learning progress is estimated based on the novelty of both current and future states. We also take advantage of rule-based autonomous driving algorithms to safely reset an autonomous vehicle to an initial state. We evaluate our algorithm against baselines on diverse urban driving tasks. The experimental results show that our algorithm is task-agnostic and achieves better driving performance with fewer manual resets than baselines.
Read more5/24/2024