Adaptive boosting with dynamic weight adjustment

0
➖
Sign in to get full access
Overview
- Adaptive Boosting with Dynamic Weight Adjustment is an enhancement of the traditional Adaptive Boosting (AdaBoost) technique.
- It improves the efficiency and accuracy of AdaBoost by dynamically updating the weights of instances based on prediction error.
- The weights are updated in proportion to the error, rather than uniformly as in traditional AdaBoost.
- This allows the model to handle more complex data relations, imbalances, and noise better, leading to more accurate and balanced predictions.
Plain English Explanation
Adaptive Boosting with Dynamic Weight Adjustment is like a smarter version of a popular machine learning technique called AdaBoost. AdaBoost is a powerful way to combine multiple "weak" models (like simple decision trees) into a single "strong" model that makes highly accurate predictions.
The key innovation of Adaptive Boosting with Dynamic Weight Adjustment is how it updates the weights of the training data. In traditional AdaBoost, the weights are updated uniformly, regardless of how well the model is performing on each data point. But in the enhanced version, the weights are updated dynamically, based on the prediction error. This means the model pays more attention to the data points it's struggling with, allowing it to handle more complex relationships, imbalances, and noise in the data.
Technical Explanation
The Adaptive Boosting with Dynamic Weight Adjustment technique builds on the traditional AdaBoost algorithm by modifying how the instance weights are updated.
In AdaBoost, the weights are updated uniformly, with more weight given to instances that were misclassified in the previous iteration. Adaptive Boosting with Dynamic Weight Adjustment, however, updates the weights in proportion to the prediction error. This means instances with higher error get a larger weight increase, allowing the model to focus more on difficult-to-classify examples.
The researchers found this dynamic weight adjustment improved the model's ability to handle complex data relationships, imbalances, and noise, leading to more accurate and balanced predictions compared to standard AdaBoost.
Critical Analysis
The paper provides a thorough evaluation of the Adaptive Boosting with Dynamic Weight Adjustment technique, including comparisons to traditional AdaBoost on several benchmark datasets. The results demonstrate the effectiveness of the dynamic weight updating approach, particularly for complex or imbalanced classification problems.
However, the paper does not extensively explore the limitations or potential downsides of the method. For example, it's unclear how the dynamic weight adjustment performs when dealing with extreme outliers or noisy data, or how sensitive the technique is to hyperparameter tuning. Further research could investigate the robustness of the method and its applicability to a wider range of machine learning tasks.
Overall, the Adaptive Boosting with Dynamic Weight Adjustment technique appears to be a promising enhancement to the AdaBoost algorithm, providing a more flexible and effective approach to boosting. The research presented in the paper lays a solid foundation for further exploration and development of this method.
Conclusion
The Adaptive Boosting with Dynamic Weight Adjustment technique is an innovative enhancement to the popular AdaBoost ensemble learning algorithm. By dynamically updating the weights of instances based on prediction error, rather than uniformly, the method can better handle complex data relationships, imbalances, and noise - leading to more accurate and balanced predictions, especially in challenging classification tasks.
While the paper provides a thorough evaluation of the technique, further research could explore its limitations and robustness. Nevertheless, this work represents an important step forward in improving the flexibility and effectiveness of boosting algorithms, with potentially significant implications for a wide range of real-world machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Adaptive boosting with dynamic weight adjustment
Vamsi Sai Ranga Sri Harsha Mangina
Adaptive Boosting with Dynamic Weight Adjustment is an enhancement of the traditional Adaptive boosting commonly known as AdaBoost, a powerful ensemble learning technique. Adaptive Boosting with Dynamic Weight Adjustment technique improves the efficiency and accuracy by dynamically updating the weights of the instances based on prediction error where the weights are updated in proportion to the error rather than updating weights uniformly as we do in traditional Adaboost. Adaptive Boosting with Dynamic Weight Adjustment performs better than Adaptive Boosting as it can handle more complex data relations, allowing our model to handle imbalances and noise better, leading to more accurate and balanced predictions. The proposed model provides a more flexible and effective approach for boosting, particularly in challenging classification tasks.
Read more6/4/2024
📈
0
Dynamic Model Switching for Improved Accuracy in Machine Learning
Syed Tahir Abbas Hasani
In the dynamic landscape of machine learning, where datasets vary widely in size and complexity, selecting the most effective model poses a significant challenge. Rather than fixating on a single model, our research propels the field forward with a novel emphasis on dynamic model switching. This paradigm shift allows us to harness the inherent strengths of different models based on the evolving size of the dataset. Consider the scenario where CatBoost demonstrates exceptional efficacy in handling smaller datasets, providing nuanced insights and accurate predictions. However, as datasets grow in size and intricacy, XGBoost, with its scalability and robustness, becomes the preferred choice. Our approach introduces an adaptive ensemble that intuitively transitions between CatBoost and XGBoost. This seamless switching is not arbitrary; instead, it's guided by a user-defined accuracy threshold, ensuring a meticulous balance between model sophistication and data requirements. The user sets a benchmark, say 80% accuracy, prompting the system to dynamically shift to the new model only if it guarantees improved performance. This dynamic model-switching mechanism aligns with the evolving nature of data in real-world scenarios. It offers practitioners a flexible and efficient solution, catering to diverse dataset sizes and optimising predictive accuracy at every juncture. Our research, therefore, stands at the forefront of innovation, redefining how machine learning models adapt and excel in the face of varying dataset dynamics.
Read more5/1/2024
0
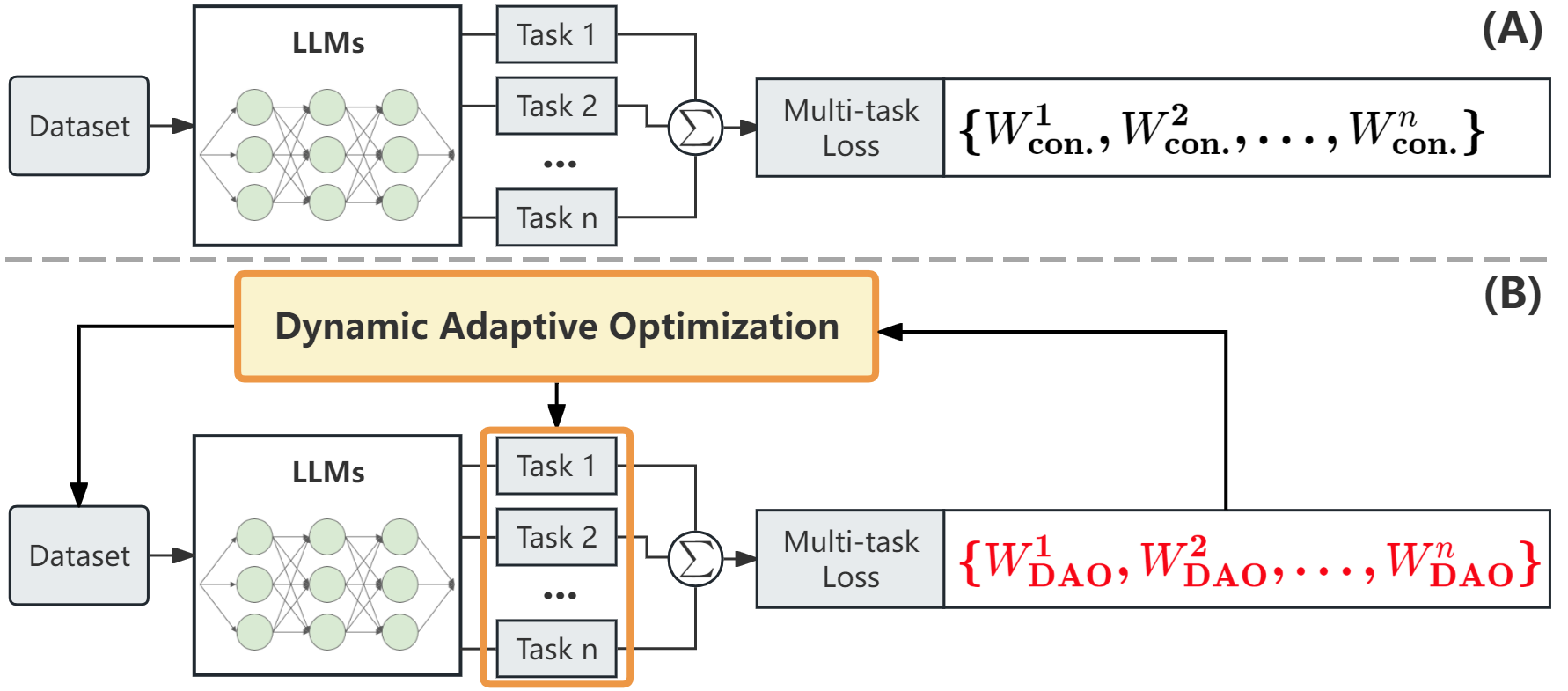
Dynamic Adaptive Optimization for Effective Sentiment Analysis Fine-Tuning on Large Language Models
Hongcheng Ding, Xuanze Zhao, Shamsul Nahar Abdullah, Deshinta Arrova Dewi, Zixiao Jiang
Sentiment analysis plays a crucial role in various domains, such as business intelligence and financial forecasting. Large language models (LLMs) have become a popular paradigm for sentiment analysis, leveraging multi-task learning to address specific tasks concurrently. However, LLMs with fine-tuning for sentiment analysis often underperforms due to the inherent challenges in managing diverse task complexities. Moreover, constant-weight approaches in multi-task learning struggle to adapt to variations in data characteristics, further complicating model effectiveness. To address these issues, we propose a novel multi-task learning framework with a dynamic adaptive optimization (DAO) module. This module is designed as a plug-and-play component that can be seamlessly integrated into existing models, providing an effective and flexible solution for multi-task learning. The key component of the DAO module is dynamic adaptive loss, which dynamically adjusts the weights assigned to different tasks based on their relative importance and data characteristics during training. Sentiment analyses on a standard and customized financial text dataset demonstrate that the proposed framework achieves superior performance. Specifically, this work improves the Mean Squared Error (MSE) and Accuracy (ACC) by 15.58% and 1.24% respectively, compared with previous work.
Read more8/23/2024
0
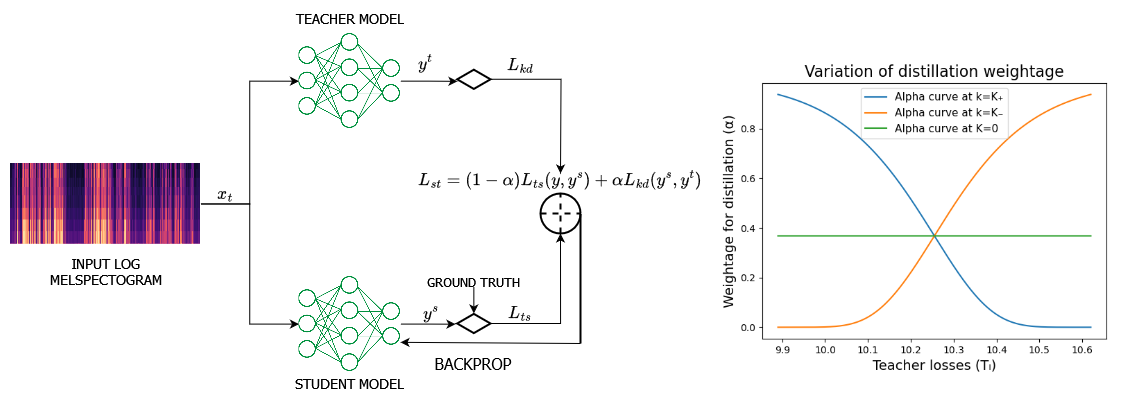
AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting
Shreyan Ganguly, Roshan Nayak, Rakshith Rao, Ujan Deb, Prathosh AP
Knowledge distillation, a widely used model compression technique, works on the basis of transferring knowledge from a cumbersome teacher model to a lightweight student model. The technique involves jointly optimizing the task specific and knowledge distillation losses with a weight assigned to them. Despite these weights playing a crucial role in the performance of the distillation process, current methods provide equal weight to both losses, leading to suboptimal performance. In this paper, we propose Adaptive Knowledge Distillation, a novel technique inspired by curriculum learning to adaptively weigh the losses at instance level. This technique goes by the notion that sample difficulty increases with teacher loss. Our method follows a plug-and-play paradigm that can be applied on top of any task-specific and distillation objectives. Experiments show that our method performs better than conventional knowledge distillation method and existing instance-level loss functions.
Read more5/15/2024