Adaptive Discrete Disparity Volume for Self-supervised Monocular Depth Estimation

0

Sign in to get full access
Overview
- This paper proposes an "Adaptive Discrete Disparity Volume" method for monocular depth estimation, which aims to improve the accuracy and flexibility of self-supervised depth prediction.
- The key idea is to adaptively discretize the disparity space based on the input image, rather than using a fixed discretization.
- The method is evaluated on standard monocular depth estimation benchmarks and shows improved performance compared to previous self-supervised approaches.
Plain English Explanation
The paper describes a new technique for estimating depth information from a single image, without using any additional depth sensors. This is known as monocular depth estimation, and it's a challenging problem because there are many possible depth values that could correspond to a given 2D image.
The researchers' main insight is that instead of using a fixed set of depth values to consider, they can adaptively choose the depth values based on the specific image. This "adaptive discretization" allows the model to focus on the most relevant depth ranges for each scene, rather than wasting capacity on irrelevant depth values.
To do this, the model first generates a rough initial depth estimate. It then uses this to define a set of depth values that are most likely to be accurate for that particular scene. The final depth prediction is then computed using this adaptive disparity volume.
The key advantage is that the model can allocate its capacity more effectively, leading to more accurate depth estimates compared to previous self-supervised approaches that used a fixed disparity volume.
Technical Explanation
The paper proposes an "Adaptive Discrete Disparity Volume" (ADDV) module for self-supervised monocular depth estimation. The core idea is to adaptively discretize the disparity space based on the input image, rather than using a fixed discretization.
The ADDV module first generates a coarse initial depth estimate using a standard depth prediction network. It then uses this coarse depth to define an adaptive disparity volume, focusing the network's capacity on the most relevant disparity ranges for that particular scene.
Specifically, the ADDV module computes a set of adaptive disparity bins by clustering the initial depth estimates. It then uses these adaptive bins to construct a disparity volume, which is used as input to the final depth prediction network.
The authors evaluate their approach on standard monocular depth estimation benchmarks, including KITTI and NYUv2. They show that the ADDV module leads to improved depth prediction accuracy compared to previous self-supervised methods that used a fixed disparity volume.
Critical Analysis
The key strength of this work is the adaptive discretization of the disparity space, which allows the model to focus its capacity on the most relevant depth ranges for each input image. This is an insightful contribution that addresses a limitation of previous self-supervised depth estimation approaches.
However, the paper does not provide a thorough analysis of the computational complexity or inference time of the ADDV module. It's unclear how this additional processing step impacts the overall efficiency of the depth estimation pipeline.
Additionally, the paper only evaluates the method on standard benchmark datasets. It would be valuable to see how the ADDV module performs in real-world scenarios, where the distribution of depth values may differ significantly from the benchmarks.
Finally, the paper does not discuss potential failure cases or limitations of the adaptive discretization approach. For example, it's unclear how the method would handle scenes with multiple depth layers or very sparse depth information.
Conclusion
This paper presents a novel approach to self-supervised monocular depth estimation, using an "Adaptive Discrete Disparity Volume" to improve the accuracy and flexibility of depth prediction. The key innovation is the adaptive discretization of the disparity space, which allows the model to focus its capacity on the most relevant depth ranges for each input image.
The results show that this ADDV module leads to improved depth estimation performance compared to previous self-supervised methods. This is an important contribution to the field of monocular depth estimation, which has many applications in areas like autonomous navigation, augmented reality, and computational photography.
While the paper does not address all potential limitations of the approach, it represents a significant step forward in developing more effective self-supervised depth estimation systems. Further research could explore the computational efficiency of the ADDV module, as well as its performance in more diverse real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Discrete Disparity Volume for Self-supervised Monocular Depth Estimation
Jianwei Ren
In self-supervised monocular depth estimation tasks, discrete disparity prediction has been proven to attain higher quality depth maps than common continuous methods. However, current discretization strategies often divide depth ranges of scenes into bins in a handcrafted and rigid manner, limiting model performance. In this paper, we propose a learnable module, Adaptive Discrete Disparity Volume (ADDV), which is capable of dynamically sensing depth distributions in different RGB images and generating adaptive bins for them. Without any extra supervision, this module can be integrated into existing CNN architectures, allowing networks to produce representative values for bins and a probability volume over them. Furthermore, we introduce novel training strategies - uniformizing and sharpening - through a loss term and temperature parameter, respectively, to provide regularizations under self-supervised conditions, preventing model degradation or collapse. Empirical results demonstrate that ADDV effectively processes global information, generating appropriate bins for various scenes and producing higher quality depth maps compared to handcrafted methods.
Read more4/5/2024

0
Progressive Depth Decoupling and Modulating for Flexible Depth Completion
Zhiwen Yang, Jiehua Zhang, Liang Li, Chenggang Yan, Yaoqi Sun, Haibing Yin
Image-guided depth completion aims at generating a dense depth map from sparse LiDAR data and RGB image. Recent methods have shown promising performance by reformulating it as a classification problem with two sub-tasks: depth discretization and probability prediction. They divide the depth range into several discrete depth values as depth categories, serving as priors for scene depth distributions. However, previous depth discretization methods are easy to be impacted by depth distribution variations across different scenes, resulting in suboptimal scene depth distribution priors. To address the above problem, we propose a progressive depth decoupling and modulating network, which incrementally decouples the depth range into bins and adaptively generates multi-scale dense depth maps in multiple stages. Specifically, we first design a Bins Initializing Module (BIM) to construct the seed bins by exploring the depth distribution information within a sparse depth map, adapting variations of depth distribution. Then, we devise an incremental depth decoupling branch to progressively refine the depth distribution information from global to local. Meanwhile, an adaptive depth modulating branch is developed to progressively improve the probability representation from coarse-grained to fine-grained. And the bi-directional information interactions are proposed to strengthen the information interaction between those two branches (sub-tasks) for promoting information complementation in each branch. Further, we introduce a multi-scale supervision mechanism to learn the depth distribution information in latent features and enhance the adaptation capability across different scenes. Experimental results on public datasets demonstrate that our method outperforms the state-of-the-art methods. The code will be open-sourced at [this https URL](https://github.com/Cisse-away/PDDM).
Read more5/16/2024
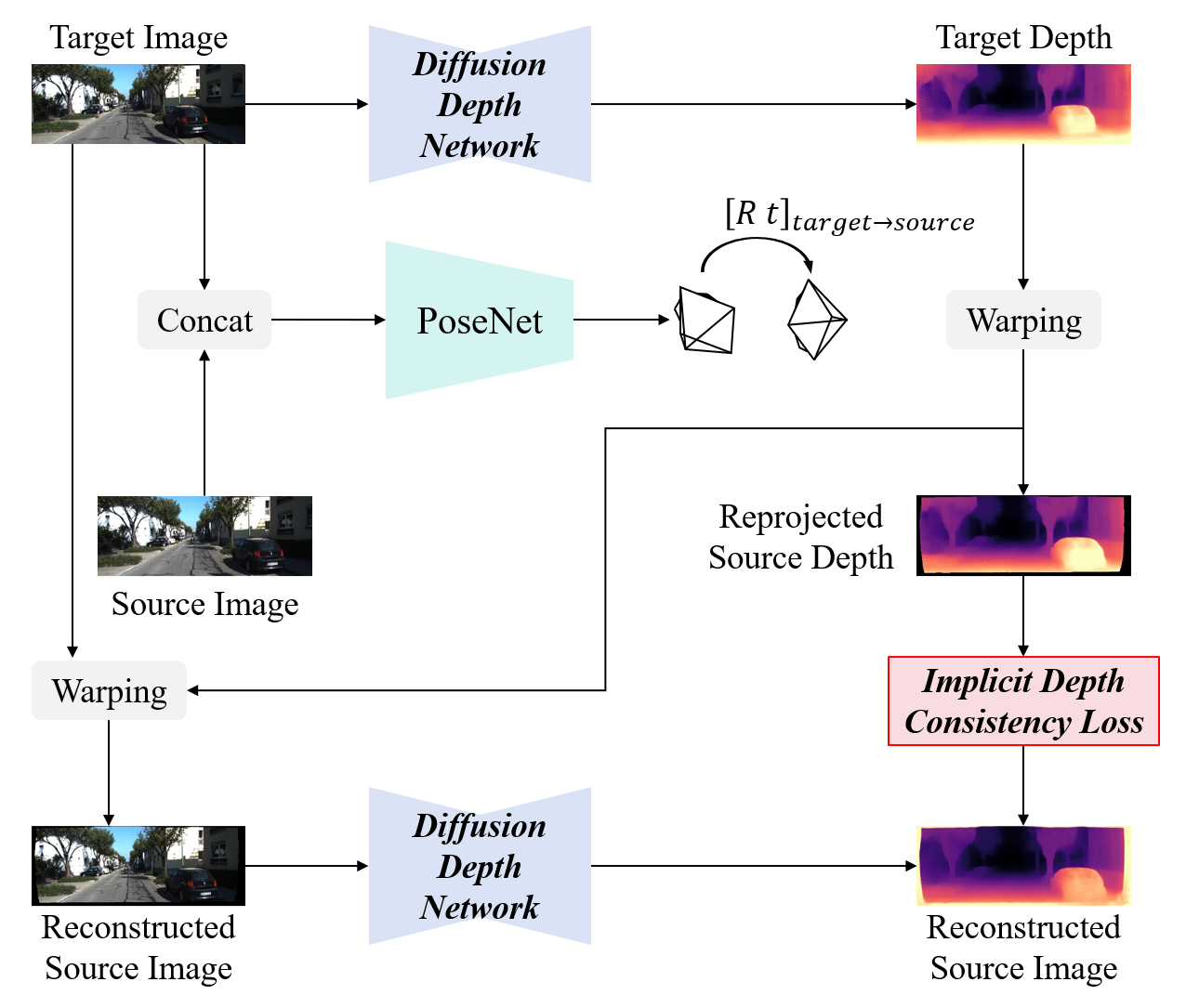
0
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Read more6/17/2024

0
EDADepth: Enhanced Data Augmentation for Monocular Depth Estimation
Nischal Khanal, Shivanand Venkanna Sheshappanavar
Due to their text-to-image synthesis feature, diffusion models have recently seen a rise in visual perception tasks, such as depth estimation. The lack of good-quality datasets makes the extraction of a fine-grain semantic context challenging for the diffusion models. The semantic context with fewer details further worsens the process of creating effective text embeddings that will be used as input for diffusion models. In this paper, we propose a novel EDADepth, an enhanced data augmentation method to estimate monocular depth without using additional training data. We use Swin2SR, a super-resolution model, to enhance the quality of input images. We employ the BEiT pre-trained semantic segmentation model for better extraction of text embeddings. We introduce BLIP-2 tokenizer to generate tokens from these text embeddings. The novelty of our approach is the introduction of Swin2SR, the BEiT model, and the BLIP-2 tokenizer in the diffusion-based pipeline for the monocular depth estimation. Our model achieves state-of-the-art results (SOTA) on the {delta}3 metric on NYUv2 and KITTI datasets. It also achieves results comparable to those of the SOTA models in the RMSE and REL metrics. Finally, we also show improvements in the visualization of the estimated depth compared to the SOTA diffusion-based monocular depth estimation models. Code: https://github.com/edadepthmde/EDADepth_ICMLA.
Read more9/11/2024