Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
2406.09782
0
0
Abstract
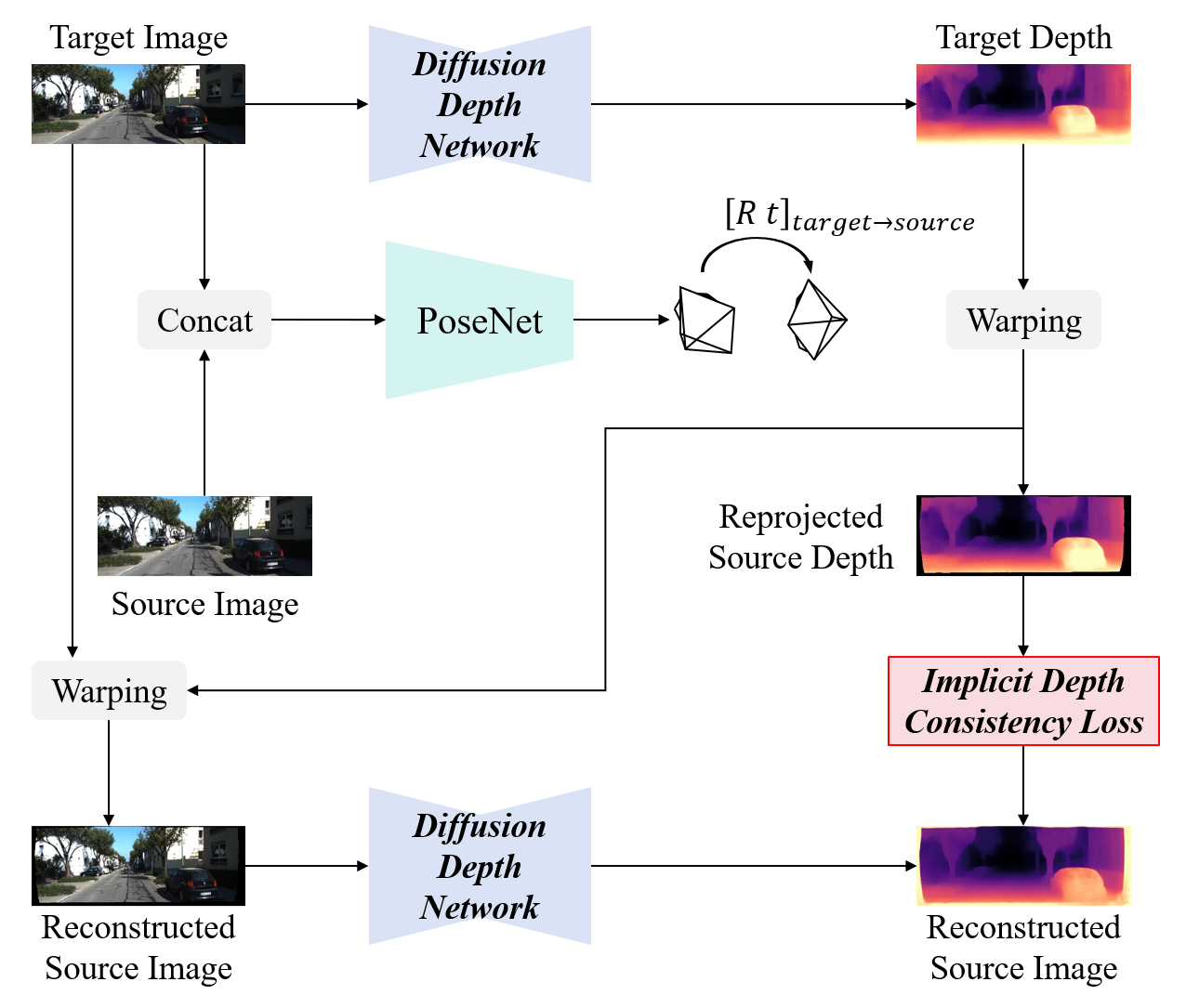
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Create account to get full access
Overview
- This paper presents an unsupervised monocular depth estimation method that leverages a hierarchical feature-guided diffusion process.
- The proposed approach aims to overcome limitations of existing self-supervised depth estimation techniques by effectively utilizing multi-scale features and a diffusion-based framework.
- The method outperforms state-of-the-art unsupervised monocular depth estimation models on several benchmark datasets.
Plain English Explanation
This research paper describes a new way to estimate depth information from a single image, without requiring any labeled training data. The key idea is to use a "diffusion" process that gradually refines the depth estimation by incorporating features at multiple scales.
Typically, depth estimation from a single image is a challenging task because there are many possible depth maps that could explain the 2D image. Existing self-supervised methods try to learn depth from cues like camera motion or object boundaries, but they are limited in their ability to capture all the necessary depth information.
The proposed approach overcomes these limitations by using a hierarchical diffusion process. It starts with a coarse initial depth map and then gradually refines it by incorporating more and more detailed image features at different scales. This allows the model to capture both the large-scale structure and fine-grained details needed for accurate depth estimation.
The end result is a depth prediction that outperforms other state-of-the-art unsupervised depth estimation techniques on standard benchmark datasets. This advance could lead to more robust depth perception in applications like autonomous navigation or 3D reconstruction from single camera inputs.
Technical Explanation
The paper proposes an unsupervised monocular depth estimation method based on a hierarchical feature-guided diffusion process. The key components are:
-
Hierarchical Feature Extraction: The model uses a pre-trained convolutional neural network to extract multi-scale visual features from the input image. These features capture both coarse structural information and fine-grained details.
-
Diffusion-based Depth Estimation: The depth estimation is formulated as a diffusion process that gradually refines an initial depth map by incorporating the hierarchical features. This allows the model to capture both global depth structure and local depth details.
-
Unsupervised Training: The model is trained in an unsupervised manner, without requiring any ground truth depth labels. Instead, it leverages self-supervision signals such as camera ego-motion and reprojection consistency to learn depth estimation.
The proposed method is evaluated on several popular monocular depth estimation benchmarks, including KITTI, NYUv2, and TUM. The results demonstrate that it outperforms previous state-of-the-art unsupervised depth estimation techniques.
Critical Analysis
The paper presents a compelling approach to unsupervised monocular depth estimation, but there are a few potential limitations and areas for further research:
-
Reliance on Pre-trained Features: The method relies on a pre-trained feature extraction network, which may limit its flexibility and adaptability to different data domains. Exploring end-to-end feature learning could further improve performance.
-
Computational Complexity: The hierarchical diffusion process may be computationally intensive, especially for real-time applications. Investigating ways to streamline the inference process could make the method more practical.
-
Generalization Challenges: While the method performs well on the evaluated benchmarks, its generalization to diverse real-world scenarios with varying illumination, occlusions, and scene complexity remains to be thoroughly investigated.
-
Lack of Explainability: As with many deep learning techniques, the inner workings of the proposed model are not easily interpretable. Developing more transparent and explainable depth estimation methods could be valuable for certain applications.
Despite these potential limitations, the paper presents an innovative approach that effectively leverages hierarchical visual features and a diffusion-based framework to advance the state-of-the-art in unsupervised monocular depth estimation. Further research in this direction could lead to more robust and versatile depth perception capabilities.
Conclusion
This paper introduces a novel unsupervised monocular depth estimation method based on a hierarchical feature-guided diffusion process. By effectively incorporating multi-scale visual features and formulating depth estimation as a diffusion-based refinement, the proposed approach outperforms existing state-of-the-art unsupervised techniques on several benchmark datasets.
The key innovation is the ability to capture both global depth structure and local depth details through the hierarchical diffusion framework, without requiring any labeled training data. This advance could have significant implications for applications such as autonomous navigation, 3D reconstruction, and scene understanding, where accurate depth perception from single images is crucial.
While the method has some potential limitations, the paper demonstrates the promising potential of diffusion-based techniques for unsupervised depth estimation. Continued research in this direction could lead to more robust and generalizable depth perception capabilities, further expanding the possibilities for computer vision and related fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, Konrad Schindler
0
0
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
4/4/2024
📈
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Hoang Chuong Nguyen, Tianyu Wang, Jose M. Alvarez, Miaomiao Liu
0
0
This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
4/24/2024

DCPI-Depth: Explicitly Infusing Dense Correspondence Prior to Unsupervised Monocular Depth Estimation
Mengtan Zhang, Yi Feng, Qijun Chen, Rui Fan
0
0
There has been a recent surge of interest in learning to perceive depth from monocular videos in an unsupervised fashion. A key challenge in this field is achieving robust and accurate depth estimation in challenging scenarios, particularly in regions with weak textures or where dynamic objects are present. This study makes three major contributions by delving deeply into dense correspondence priors to provide existing frameworks with explicit geometric constraints. The first novelty is a contextual-geometric depth consistency loss, which employs depth maps triangulated from dense correspondences based on estimated ego-motion to guide the learning of depth perception from contextual information, since explicitly triangulated depth maps capture accurate relative distances among pixels. The second novelty arises from the observation that there exists an explicit, deducible relationship between optical flow divergence and depth gradient. A differential property correlation loss is, therefore, designed to refine depth estimation with a specific emphasis on local variations. The third novelty is a bidirectional stream co-adjustment strategy that enhances the interaction between rigid and optical flows, encouraging the former towards more accurate correspondence and making the latter more adaptable across various scenarios under the static scene hypotheses. DCPI-Depth, a framework that incorporates all these innovative components and couples two bidirectional and collaborative streams, achieves state-of-the-art performance and generalizability across multiple public datasets, outperforming all existing prior arts. Specifically, it demonstrates accurate depth estimation in texture-less and dynamic regions, and shows more reasonable smoothness.
5/28/2024

Self-Supervised Monocular Depth Estimation in the Dark: Towards Data Distribution Compensation
Haolin Yang, Chaoqiang Zhao, Lu Sheng, Yang Tang
0
0
Nighttime self-supervised monocular depth estimation has received increasing attention in recent years. However, using night images for self-supervision is unreliable because the photometric consistency assumption is usually violated in the videos taken under complex lighting conditions. Even with domain adaptation or photometric loss repair, performance is still limited by the poor supervision of night images on trainable networks. In this paper, we propose a self-supervised nighttime monocular depth estimation method that does not use any night images during training. Our framework utilizes day images as a stable source for self-supervision and applies physical priors (e.g., wave optics, reflection model and read-shot noise model) to compensate for some key day-night differences. With day-to-night data distribution compensation, our framework can be trained in an efficient one-stage self-supervised manner. Though no nighttime images are considered during training, qualitative and quantitative results demonstrate that our method achieves SoTA depth estimating results on the challenging nuScenes-Night and RobotCar-Night compared with existing methods.
4/23/2024