Adaptive Energy Regularization for Autonomous Gait Transition and Energy-Efficient Quadruped Locomotion
2403.20001
0
0
Abstract
In reinforcement learning for legged robot locomotion, crafting effective reward strategies is crucial. Pre-defined gait patterns and complex reward systems are widely used to stabilize policy training. Drawing from the natural locomotion behaviors of humans and animals, which adapt their gaits to minimize energy consumption, we propose a simplified, energy-centric reward strategy to foster the development of energy-efficient locomotion across various speeds in quadruped robots. By implementing an adaptive energy reward function and adjusting the weights based on velocity, we demonstrate that our approach enables ANYmal-C and Unitree Go1 robots to autonomously select appropriate gaits, such as four-beat walking at lower speeds and trotting at higher speeds, resulting in improved energy efficiency and stable velocity tracking compared to previous methods using complex reward designs and prior gait knowledge. The effectiveness of our policy is validated through simulations in the IsaacGym simulation environment and on real robots, demonstrating its potential to facilitate stable and adaptive locomotion.
Create account to get full access
Introduction
The text discusses how humans and animals exhibit different locomotion behaviors, such as walking at low speeds and running at higher speeds, to optimize their energy efficiency. Prior research has shown that quadrupeds exhibit different optimal gaits, such as four-beat walking at low speeds, trotting at intermediate speeds, and trotting/galloping at high speeds. Using gait information as guidance for locomotion policies is a popular approach in reinforcement learning-based methods. However, creating a versatile and robust locomotion policy that can adapt to different speeds and generalize across platforms is challenging, particularly in terms of reward design. Previous works have used various reward terms, such as gait reference, feet-air time, and contact force penalties, to induce specific behaviors and stabilize the training process. While these additional reward components aim to promote certain behavioral traits, they are also aligned with the broader objective of reducing energy costs. This observation leads to the question of whether a more straightforward, energy-centric reward term could be used to replace the specifically designed terms used in prior policy training.
This paper investigates a streamlined reward formulation for energy-efficient locomotion in quadruped robots. Prior work has shown that energy-efficient gaits correlate with speed and that energy minimization at pre-selected speeds leads to the emergence of specific gaits. This study aims to verify if a simplified approach focusing solely on energy minimization can yield stable and effective velocity-tracking across a range of speeds, without the need for multiple velocity-specific energy-optimal policies.
The paper examines the influence of energy regularization weights on policy performance, finding that both excessively low and high weights can lead to unnatural movements or immobility. To address this, the researchers design a non-negative energy reward function and an adaptive reward form by interpolating the maximum energy weights at selected speeds. This adaptive reward structure is employed within the IsaacGym framework to train robust policies for the ANYmal-C and Unitree Go1 quadruped robots.
The trained policies autonomously adopt different energy-efficient gaits, such as four-beat walking at lower speeds and trotting at higher speeds, without preset gait knowledge. These policies outperform baseline approaches in terms of energy efficiency and significantly improve velocity tracking and energy consumption performance compared to a policy trained with fixed-weight energy rewards.
The paper concludes by deploying the trained single policy on a real Unitree Go1 robot, verifying its stable moving and transition locomotion skills in the real world. The main contributions of this paper include the introduction of a streamlined reward formula integrating velocity-tracking and adaptive energy minimization, the demonstration of autonomous gait adoption at varying speeds, and the evaluation and real-world application of the derived policies.
Related Works
This text summarizes recent research on using reinforcement learning (RL) to generate locomotion skills for legged robots. Early RL approaches achieved walking policies on flat ground, but tended to converge to a single trotting gait that may not be optimal for all terrains and speeds.
To overcome this limitation, researchers have explored methods to promote behavioral diversity, such as using hierarchical frameworks with predefined gait primitives or directly incorporating gait-related inputs into the RL model. However, these approaches still require manual specification of gaits or rely on training multiple velocity-specific policies.
The text also discusses the importance of energy efficiency in legged locomotion, with the cost of transport being a key metric. Prior work has used conceptual legged models and optimal control to study energy-efficient gaits at different speeds. The current work aims to generate a single RL policy that can transition between energy-optimal gaits across a range of velocities, rather than relying on complex reward engineering.
The provided figures show example gait patterns and robot simulations demonstrating different gaits at varying speeds.
Locomotion Reward Design
This paper proposes a general form of an energy-regularized locomotion reward function for training legged robot control policies using reinforcement learning. The reward function consists of three components:
-
Motion rewards: These encourage the robot to accurately track linear and angular velocity reference commands.
-
Energy rewards: These discourage energy consumption by the robot's motors. The energy reward is expressed as an exponential function of the absolute product of joint torques and velocities.
-
Adaptive energy reward weight: The weight of the energy reward is made adaptive to the reference velocity, as the authors found that fixed energy reward weights only work well within a narrow range of velocities. They collect velocity-weight sample pairs and linearly interpolate between them to get the adaptive energy reward weight.
-
Normalization index: Due to the adaptive energy reward weight, the overall reward scale varies across different velocities. To stabilize training, the authors also record the final achieved reward for each velocity-weight sample and linearly interpolate to get a normalization index curve.
The paper claims this reward function design allows training energy-efficient locomotion policies across a wide range of reference velocities.
V Locomotion Skill Training Details
The paper describes the reward design and training settings used for reinforcement learning (RL) in quadruped robot locomotion. The energy reward alone is not sufficient for RL training, so it is used together with basic locomotion rewards.
For the ANYmal-C robot, the training uses the legged-gym framework and Proximal Policy Optimization (PPO) algorithm. The system takes in various sensor inputs and outputs joint position commands. The training is done on flat ground with randomized friction and mass. Modifications are made to the velocity tracking reward function to improve convergence. The energy reward scaling and its relationship with reference velocity are determined through fixed-velocity policy training.
For the Unitree Go1 robot, the training follows the walk-these-ways framework. In addition to the energy reward, an auxiliary reward based on safety considerations is added. Curriculum learning on the velocity sampling range is found to be essential for successful training. The energy reward scaling is determined similarly to the ANYmal-C case.
The paper provides detailed descriptions of the training settings and reward design for the two quadruped robot platforms, which constitute the key technical contributions.
Experiments
The experiments were designed to show the following after the legged robot was trained using the adaptive energy-regularized reward shown in Equation (2):
-
With the adaptive weighting functions α(v̂x) and Z(v̂x), the legged robot automatically selects suitable behaviors to move with the reference velocity. The trained policy is also deployable to a real quadruped robot.
-
If the weighting functions α(v̂x) and Z(v̂x) are constant, the legged robot may not be able to find an energy-efficient walking policy for all target velocities.
-
The proposed method can generate a more energy-efficient walking policy compared to established baselines.
The paper demonstrates how a trained walking policy for a legged robot can exhibit different locomotion gaits at different reference velocities. At low speeds (0.5 m/s), the policy exhibits a four-beat walking gait, moving one leg at a time. At medium speeds (1.0 m/s), it shows an intermediate gait between walking and trotting. At high speeds (2.0 m/s), the policy exhibits a standard trotting gait.
The paper also shows that the swing ratio of the robot's legs is regularized - the legs only lift high enough to reach the reference velocity, avoiding unnecessary energy expenditure. This contrasts with other methods that tend to lift the legs redundantly high.
Ablation studies are performed to examine the effects of using a fixed energy reward scale versus an adaptive one that varies with velocity. The results show the adaptive approach achieves the lowest energy consumption while maintaining good velocity tracking accuracy.
Finally, the paper compares the trained policy to other methods on a real-world Go1 robot, demonstrating that the policy swings the legs only to the necessary height, making it the most energy-efficient.
Discussions
This paper presents a reinforcement learning approach to develop energy-efficient locomotion strategies for quadruped robots. However, the method has some limitations.
The key limitation is the requirement to pre-run experiments to determine appropriate energy regularization weights. This reliance on empirical observations limits the flexibility of the reinforcement learning system. While the developed policy can be applied across different speeds after training, it cannot be obtained with only one training session for a new quadruped platform. The paper also did not verify the adaptive capability of energy rewards in different environments, which would be crucial for real-world deployment.
Future research could address these limitations by developing methodologies to automatically tune energy regularization weights within a single reinforcement learning training. This would enable the system to dynamically adjust its strategy in response to multi-task reinforcement learning or cross-embodiment settings.
Beyond locomotion, the underlying principle of leveraging energy efficiency could be applied to other robotic tasks, such as manipulation and interaction. Implementing an energy-centric approach across different tasks could help align robotic systems more closely with sustainability principles and environmental consciousness.
Conclusions
The paper presented a new approach to energy-efficient locomotion in quadruped robots. It used a simplified, energy-focused reward strategy within a reinforcement learning framework. The method allowed quadruped robots, such as ANYmal-C and Unitree Go1, to autonomously develop and transition between various gaits at different velocities without relying on predefined gait patterns or complex reward designs. An adaptive energy reward function, adjusted based on velocity, enabled the robots to naturally select the most energy-efficient locomotion strategies. The policy demonstrated energy-efficient behaviors and gait transitions in both simulation (ANYmal-C) and hardware (Go1) experiments. The paper also showed the usefulness of adaptive energy regularization through ablation studies.
Acknowledgements
This research was funded by several organizations, including the Agency of Science, Technology and Research of Singapore through the National Science Scholarship, the FANUC Advanced Research Laboratory, and the InnoHK program of the Hong Kong government's Hong Kong Centre for Logistics Robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Locomotion Generation for a Rat Robot based on Environmental Changes via Reinforcement Learning
Xinhui Shan, Yuhong Huang, Zhenshan Bing, Zitao Zhang, Xiangtong Yao, Kai Huang, Alois Knoll
0
0
This research focuses on developing reinforcement learning approaches for the locomotion generation of small-size quadruped robots. The rat robot NeRmo is employed as the experimental platform. Due to the constrained volume, small-size quadruped robots typically possess fewer and weaker sensors, resulting in difficulty in accurately perceiving and responding to environmental changes. In this context, insufficient and imprecise feedback data from sensors makes it difficult to generate adaptive locomotion based on reinforcement learning. To overcome these challenges, this paper proposes a novel reinforcement learning approach that focuses on extracting effective perceptual information to enhance the environmental adaptability of small-size quadruped robots. According to the frequency of a robot's gait stride, key information of sensor data is analyzed utilizing sinusoidal functions derived from Fourier transform results. Additionally, a multifunctional reward mechanism is proposed to generate adaptive locomotion in different tasks. Extensive simulations are conducted to assess the effectiveness of the proposed reinforcement learning approach in generating rat robot locomotion in various environments. The experiment results illustrate the capability of the proposed approach to maintain stable locomotion of a rat robot across different terrains, including ramps, stairs, and spiral stairs.
4/16/2024
🚀
Autonomous Locomotion Mode Transition in Quadruped Track-Legged Robots: A Simulation-Based Analysis for Step Negotiation
Jie Wang, Krispin Davies
0
0
Hybrid track/wheel-legged robots combine the advantages of wheel-based and leg-based locomotion, granting adaptability across varied terrains through efficient transitions between rolling and walking modes. However, automating these transitions remains a significant challenge. In this paper, we introduce a method designed for autonomous mode transition in a quadruped hybrid robot with a track/wheel-legged configuration, especially during step negotiation. Our approach hinges on a decision-making mechanism that evaluates the energy efficiency of both locomotion modes using a proposed energy-based criterion. To guarantee a smooth negotiation of steps, we incorporate two climbing gaits designated for the assessment of energy usage in walking locomotion. Simulation results validate the method's effectiveness, showing successful autonomous transitions across steps of diverse heights. Our suggested approach has universal applicability and can be modified to suit other hybrid robots of similar mechanical configuration, provided their locomotion energy performance is studied beforehand.
4/4/2024
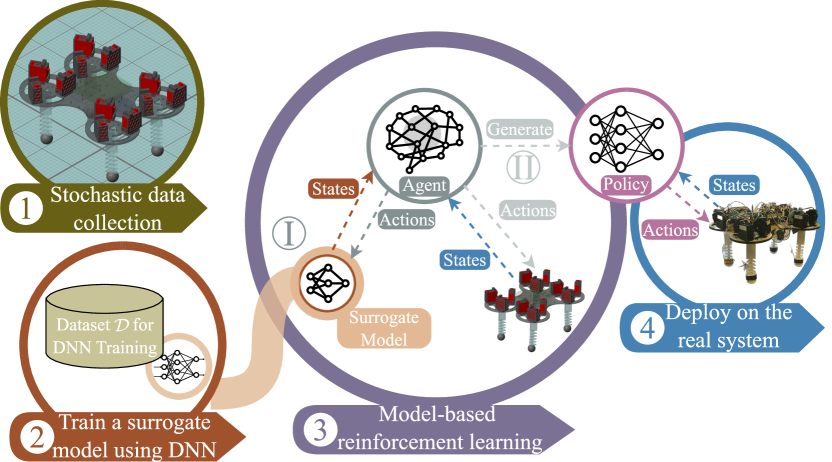
Optimal Gait Control for a Tendon-driven Soft Quadruped Robot by Model-based Reinforcement Learning
Xuezhi Niu, Kaige Tan, Lei Feng
0
0
This study presents an innovative approach to optimal gait control for a soft quadruped robot enabled by four Compressible Tendon-driven Soft Actuators (CTSAs). Improving our previous studies of using model-free reinforcement learning for gait control, we employ model-based reinforcement learning (MBRL) to further enhance the performance of the gait controller. Compared to rigid robots, the proposed soft quadruped robot has better safety, less weight, and a simpler mechanism for fabrication and control. However, the primary challenge lies in developing sophisticated control algorithms to attain optimal gait control for fast and stable locomotion. The research employs a multi-stage methodology, including state space restriction, data-driven model training, and reinforcement learning algorithm development. Compared to benchmark methods, the proposed MBRL algorithm, combined with post-training, significantly improves the efficiency and performance of gait control policies. The developed policy is both robust and adaptable to the robot's deformable morphology. The study concludes by highlighting the practical applicability of these findings in real-world scenarios.
6/12/2024

Optimal Gait Design for a Soft Quadruped Robot via Multi-fidelity Bayesian Optimization
Kaige Tan, Xuezhi Niu, Qinglei Ji, Lei Feng, Martin Torngren
0
0
This study focuses on the locomotion capability improvement in a tendon-driven soft quadruped robot through an online adaptive learning approach. Leveraging the inverse kinematics model of the soft quadruped robot, we employ a central pattern generator to design a parametric gait pattern, and use Bayesian optimization (BO) to find the optimal parameters. Further, to address the challenges of modeling discrepancies, we implement a multi-fidelity BO approach, combining data from both simulation and physical experiments throughout training and optimization. This strategy enables the adaptive refinement of the gait pattern and ensures a smooth transition from simulation to real-world deployment for the controller. Moreover, we integrate a computational task off-loading architecture by edge computing, which reduces the onboard computational and memory overhead, to improve real-time control performance and facilitate an effective online learning process. The proposed approach successfully achieves optimal walking gait design for physical deployment with high efficiency, effectively addressing challenges related to the reality gap in soft robotics.
6/12/2024