Adaptive Explicit Knowledge Transfer for Knowledge Distillation

0
🔄
Sign in to get full access
Overview
- Logit-based knowledge distillation (KD) for classification is cost-efficient compared to feature-based KD, but often has inferior performance.
- Recent research has shown that the performance of logit-based KD can be improved by effectively delivering the "implicit (dark) knowledge" from the teacher model to the student model.
- This paper proposes a new method called Adaptive Explicit Knowledge Transfer (AEKT) that achieves improved performance compared to state-of-the-art KD methods.
Plain English Explanation
In knowledge distillation, a smaller "student" model is trained to mimic the behavior of a larger "teacher" model. This is often done by having the student learn the teacher's output probabilities (called "logits") for each class, rather than just the final predicted class.
This logit-based approach is efficient, but it can sometimes result in the student model not performing as well as the teacher. The researchers found that this is often because the student is not effectively learning the "implicit" or "dark" knowledge from the teacher - the subtle information about how confident the teacher is in its predictions for the non-target classes.
The researchers show that by adaptively controlling how the student learns this implicit knowledge, the performance can be improved. They also propose separating the classification and distillation tasks, which helps the student both learn the explicit knowledge (the teacher's confidence in the target class) and model the relationships between classes more effectively.
The result is a new knowledge distillation method called AEKT that outperforms other state-of-the-art approaches on benchmark datasets like CIFAR-100 and ImageNet.
Technical Explanation
The key innovations in the AEKT method are:
-
Adaptive Implicit Knowledge Transfer: Through gradient analysis, the researchers show that effectively delivering the teacher's "implicit (dark) knowledge" about non-target classes to the student can have an adaptive effect on learning. This helps the student model learn this subtle information more effectively.
-
Explicit Knowledge Transfer: The researchers propose a new loss function that enables the student to learn the teacher's "explicit knowledge" (i.e., the teacher's confidence in the target class) along with the implicit knowledge, in an adaptive manner.
-
Separation of Classification and Distillation Tasks: The method separates the classification and distillation tasks, which helps the student both learn the explicit knowledge from the teacher and model the relationships between classes more effectively.
Experiments on the CIFAR-100 and ImageNet datasets demonstrate that AEKT achieves improved performance compared to other state-of-the-art knowledge distillation methods.
Critical Analysis
The paper provides a thorough technical explanation and evaluation of the proposed AEKT method. It addresses the limitations of previous logit-based knowledge distillation approaches and introduces innovative solutions to improve performance.
One potential area for further research is exploring the generalization of the AEKT method to other types of teacher-student architectures or distillation scenarios, such as distilling from an ensemble of teacher models or distilling across different modalities (e.g., image to text).
Additionally, the paper could have delved deeper into the specific mechanisms by which the adaptive implicit knowledge transfer and separation of tasks lead to the observed performance gains. This could help provide more insights into the underlying reasons for the method's effectiveness.
Conclusion
This paper presents a novel knowledge distillation method called Adaptive Explicit Knowledge Transfer (AEKT) that addresses the limitations of previous logit-based approaches. By adaptively transferring the teacher's implicit "dark" knowledge, explicitly transferring the teacher's confidence, and separating the classification and distillation tasks, AEKT achieves state-of-the-art performance on benchmark datasets. The insights and techniques introduced in this work could help advance the field of knowledge distillation and enable more efficient and effective model compression and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Adaptive Explicit Knowledge Transfer for Knowledge Distillation
Hyungkeun Park, Jong-Seok Lee
Logit-based knowledge distillation (KD) for classification is cost-efficient compared to feature-based KD but often subject to inferior performance. Recently, it was shown that the performance of logit-based KD can be improved by effectively delivering the probability distribution for the non-target classes from the teacher model, which is known as `implicit (dark) knowledge', to the student model. Through gradient analysis, we first show that this actually has an effect of adaptively controlling the learning of implicit knowledge. Then, we propose a new loss that enables the student to learn explicit knowledge (i.e., the teacher's confidence about the target class) along with implicit knowledge in an adaptive manner. Furthermore, we propose to separate the classification and distillation tasks for effective distillation and inter-class relationship modeling. Experimental results demonstrate that the proposed method, called adaptive explicit knowledge transfer (AEKT) method, achieves improved performance compared to the state-of-the-art KD methods on the CIFAR-100 and ImageNet datasets.
Read more9/6/2024
🔄
0
New!Harmonizing knowledge Transfer in Neural Network with Unified Distillation
Yaomin Huang, Zaomin Yan, Chaomin Shen, Faming Fang, Guixu Zhang
Knowledge distillation (KD), known for its ability to transfer knowledge from a cumbersome network (teacher) to a lightweight one (student) without altering the architecture, has been garnering increasing attention. Two primary categories emerge within KD methods: feature-based, focusing on intermediate layers' features, and logits-based, targeting the final layer's logits. This paper introduces a novel perspective by leveraging diverse knowledge sources within a unified KD framework. Specifically, we aggregate features from intermediate layers into a comprehensive representation, effectively gathering semantic information from different stages and scales. Subsequently, we predict the distribution parameters from this representation. These steps transform knowledge from the intermediate layers into corresponding distributive forms, thereby allowing for knowledge distillation through a unified distribution constraint at different stages of the network, ensuring the comprehensiveness and coherence of knowledge transfer. Numerous experiments were conducted to validate the effectiveness of the proposed method.
Read more9/30/2024

0
AdaDistill: Adaptive Knowledge Distillation for Deep Face Recognition
Fadi Boutros, Vitomir v{S}truc, Naser Damer
Knowledge distillation (KD) aims at improving the performance of a compact student model by distilling the knowledge from a high-performing teacher model. In this paper, we present an adaptive KD approach, namely AdaDistill, for deep face recognition. The proposed AdaDistill embeds the KD concept into the softmax loss by training the student using a margin penalty softmax loss with distilled class centers from the teacher. Being aware of the relatively low capacity of the compact student model, we propose to distill less complex knowledge at an early stage of training and more complex one at a later stage of training. This relative adjustment of the distilled knowledge is controlled by the progression of the learning capability of the student over the training iterations without the need to tune any hyper-parameters. Extensive experiments and ablation studies show that AdaDistill can enhance the discriminative learning capability of the student and demonstrate superiority over various state-of-the-art competitors on several challenging benchmarks, such as IJB-B, IJB-C, and ICCV2021-MFR
Read more7/2/2024
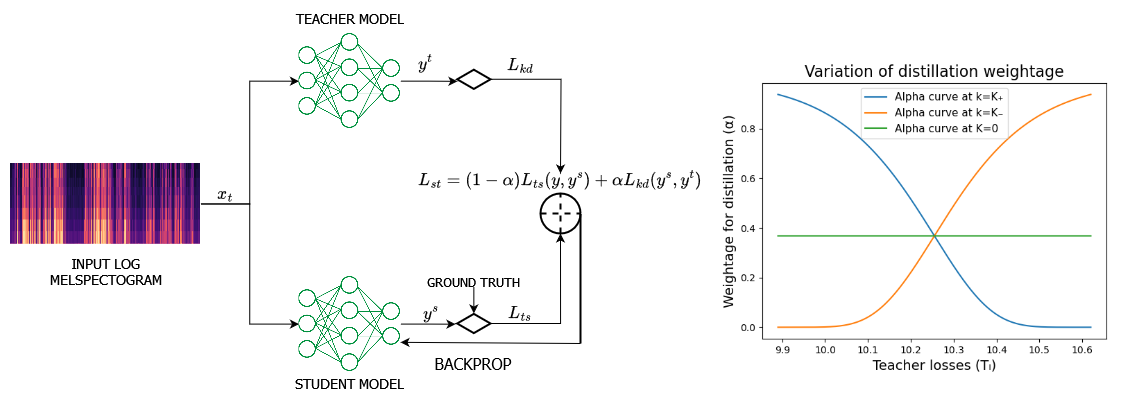
0
AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting
Shreyan Ganguly, Roshan Nayak, Rakshith Rao, Ujan Deb, Prathosh AP
Knowledge distillation, a widely used model compression technique, works on the basis of transferring knowledge from a cumbersome teacher model to a lightweight student model. The technique involves jointly optimizing the task specific and knowledge distillation losses with a weight assigned to them. Despite these weights playing a crucial role in the performance of the distillation process, current methods provide equal weight to both losses, leading to suboptimal performance. In this paper, we propose Adaptive Knowledge Distillation, a novel technique inspired by curriculum learning to adaptively weigh the losses at instance level. This technique goes by the notion that sample difficulty increases with teacher loss. Our method follows a plug-and-play paradigm that can be applied on top of any task-specific and distillation objectives. Experiments show that our method performs better than conventional knowledge distillation method and existing instance-level loss functions.
Read more5/15/2024