Adaptive Federated Learning in Heterogeneous Wireless Networks with Independent Sampling

0
🔄
Sign in to get full access
Overview
- Federated Learning (FL) algorithms often sample a subset of clients to address the straggler issue and improve communication efficiency.
- Recent works have proposed various client sampling methods, but they have limitations in jointly addressing system and data heterogeneity.
- This paper advocates a new independent client sampling strategy to minimize the wall-clock training time of FL, considering both data and system heterogeneity.
Plain English Explanation
Federated Learning (FL) is a way for multiple devices, like phones or computers, to collaboratively train a machine learning model without sharing their private data. In traditional FL, a central server will randomly select a subset of devices to participate in each training round, to avoid slow or unreliable devices (known as "stragglers") from slowing down the overall training process.
However, the current client selection methods don't fully account for the fact that different devices may have very different computing power and network speeds (system heterogeneity), as well as different types of data (data heterogeneity). This can still impact the overall training time and performance.
This paper proposes a new independent client sampling strategy that tries to address both system and data heterogeneity. The key idea is to carefully select which devices participate in each round, based on an analysis of how long each device is likely to take to complete a training round and how much their data differs from the average. This allows the system to minimize the total training time while still respecting the privacy constraints of Federated Learning.
Technical Explanation
The paper first derives a new convergence bound for non-convex loss functions with independent client sampling. This provides a theoretical foundation for understanding the impacts of the proposed sampling strategy.
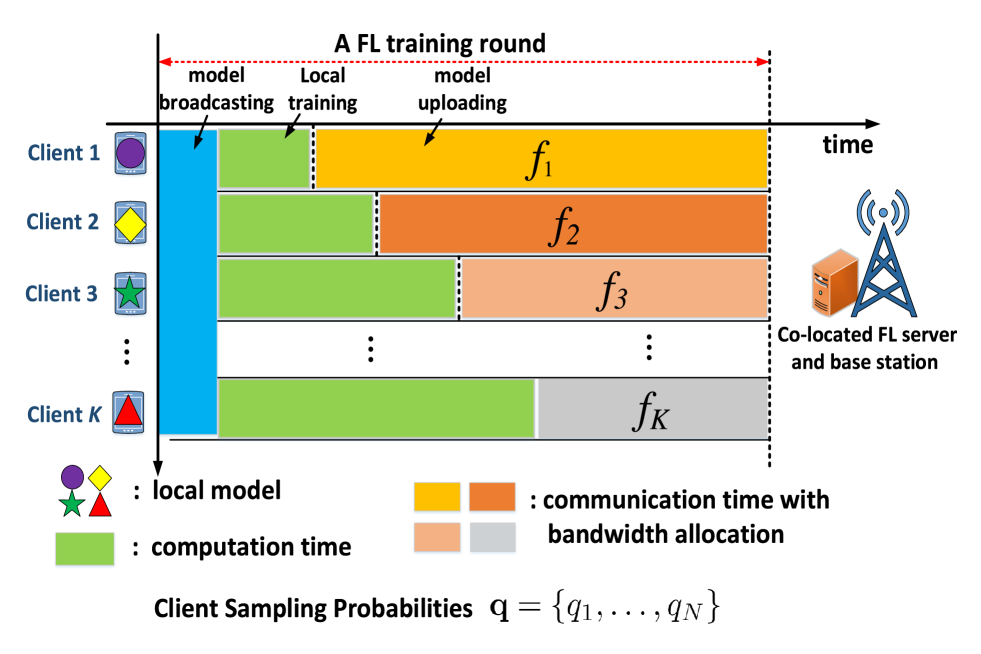
The authors then propose an adaptive bandwidth allocation scheme, which dynamically adjusts the network resources assigned to each participating client based on their system characteristics. This helps mitigate the impact of system heterogeneity.
Building on these insights, the paper introduces an efficient independent client sampling algorithm. This algorithm selects clients to participate in each round based on upper bounds for the convergence rounds and expected per-round training time. The goal is to minimize the overall wall-clock training time while accounting for both data and system heterogeneity.
The proposed approach is evaluated under practical wireless network settings using real-world prototypes. The experiments show that the independent sampling scheme substantially outperforms current state-of-the-art sampling methods across various training models and datasets. This demonstrates the effectiveness of jointly considering system and data heterogeneity in the client sampling process for Federated Learning.
Critical Analysis
The paper addresses an important practical challenge in Federated Learning - how to effectively sample clients to participate in the training process when there is significant heterogeneity in both the data and system characteristics of the participating devices.
The theoretical analysis and proposed adaptive sampling algorithm provide a solid foundation for tackling this problem. However, the paper does not discuss some potential limitations or caveats:
- The analysis assumes certain simplifying conditions, such as non-convex loss functions, that may not always hold in real-world scenarios.
- The adaptive bandwidth allocation scheme relies on accurate modeling of device characteristics, which may be difficult to obtain in practice.
- The evaluation is limited to simulated wireless network settings and may not fully capture the complexities of real-world deployment.
Further research could explore relaxing some of these assumptions, as well as investigating the performance of the proposed approach in more diverse and realistic deployment settings. Conducting user studies to understand the practical concerns and challenges faced by FL practitioners would also be valuable.
Conclusion
This paper presents a novel independent client sampling strategy for Federated Learning that aims to minimize the overall training time by jointly considering system and data heterogeneity. The theoretical analysis, adaptive bandwidth allocation, and efficient sampling algorithm provide a promising approach to improving the practicality and performance of Federated Learning in real-world, resource-constrained environments.
The key contribution is the insight that carefully selecting which clients participate in each training round, based on both their computational/network capabilities and the uniqueness of their data, can lead to significant improvements in the overall training efficiency of Federated Learning systems. This work represents an important step forward in addressing the practical challenges of deploying FL in diverse, heterogeneous settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Adaptive Federated Learning in Heterogeneous Wireless Networks with Independent Sampling
Jiaxiang Geng, Yanzhao Hou, Xiaofeng Tao, Juncheng Wang, Bing Luo
Federated Learning (FL) algorithms commonly sample a random subset of clients to address the straggler issue and improve communication efficiency. While recent works have proposed various client sampling methods, they have limitations in joint system and data heterogeneity design, which may not align with practical heterogeneous wireless networks. In this work, we advocate a new independent client sampling strategy to minimize the wall-clock training time of FL, while considering data heterogeneity and system heterogeneity in both communication and computation. We first derive a new convergence bound for non-convex loss functions with independent client sampling and then propose an adaptive bandwidth allocation scheme. Furthermore, we propose an efficient independent client sampling algorithm based on the upper bounds on the convergence rounds and the expected per-round training time, to minimize the wall-clock time of FL, while considering both the data and system heterogeneity. Experimental results under practical wireless network settings with real-world prototype demonstrate that the proposed independent sampling scheme substantially outperforms the current best sampling schemes under various training models and datasets.
Read more5/15/2024
0
Adaptive Heterogeneous Client Sampling for Federated Learning over Wireless Networks
Bing Luo, Wenli Xiao, Shiqiang Wang, Jianwei Huang, Leandros Tassiulas
Federated learning (FL) algorithms usually sample a fraction of clients in each round (partial participation) when the number of participants is large and the server's communication bandwidth is limited. Recent works on the convergence analysis of FL have focused on unbiased client sampling, e.g., sampling uniformly at random, which suffers from slow wall-clock time for convergence due to high degrees of system heterogeneity and statistical heterogeneity. This paper aims to design an adaptive client sampling algorithm for FL over wireless networks that tackles both system and statistical heterogeneity to minimize the wall-clock convergence time. We obtain a new tractable convergence bound for FL algorithms with arbitrary client sampling probability. Based on the bound, we analytically establish the relationship between the total learning time and sampling probability with an adaptive bandwidth allocation scheme, which results in a non-convex optimization problem. We design an efficient algorithm for learning the unknown parameters in the convergence bound and develop a low-complexity algorithm to approximately solve the non-convex problem. Our solution reveals the impact of system and statistical heterogeneity parameters on the optimal client sampling design. Moreover, our solution shows that as the number of sampled clients increases, the total convergence time first decreases and then increases because a larger sampling number reduces the number of rounds for convergence but results in a longer expected time per-round due to limited wireless bandwidth. Experimental results from both hardware prototype and simulation demonstrate that our proposed sampling scheme significantly reduces the convergence time compared to several baseline sampling schemes.
Read more4/23/2024

0
Enhanced Federated Optimization: Adaptive Unbiased Client Sampling with Reduced Variance
Dun Zeng, Zenglin Xu, Yu Pan, Xu Luo, Qifan Wang, Xiaoying Tang
Federated Learning (FL) is a distributed learning paradigm to train a global model across multiple devices without collecting local data. In FL, a server typically selects a subset of clients for each training round to optimize resource usage. Central to this process is the technique of unbiased client sampling, which ensures a representative selection of clients. Current methods primarily utilize a random sampling procedure which, despite its effectiveness, achieves suboptimal efficiency owing to the loose upper bound caused by the sampling variance. In this work, by adopting an independent sampling procedure, we propose a federated optimization framework focused on adaptive unbiased client sampling, improving the convergence rate via an online variance reduction strategy. In particular, we present the first adaptive client sampler, K-Vib, employing an independent sampling procedure. K-Vib achieves a linear speed-up on the regret bound $tilde{mathcal{O}}big(N^{frac{1}{3}}T^{frac{2}{3}}/K^{frac{4}{3}}big)$ within a set communication budget $K$. Empirical studies indicate that K-Vib doubles the speed compared to baseline algorithms, demonstrating significant potential in federated optimization.
Read more9/4/2024

0
Seamless Integration: Sampling Strategies in Federated Learning Systems
Tatjana Legler, Vinit Hegiste, Martin Ruskowski
Federated Learning (FL) represents a paradigm shift in the field of machine learning, offering an approach for a decentralized training of models across a multitude of devices while maintaining the privacy of local data. However, the dynamic nature of FL systems, characterized by the ongoing incorporation of new clients with potentially diverse data distributions and computational capabilities, poses a significant challenge to the stability and efficiency of these distributed learning networks. The seamless integration of new clients is imperative to sustain and enhance the performance and robustness of FL systems. This paper looks into the complexities of integrating new clients into existing FL systems and explores how data heterogeneity and varying data distribution (not independent and identically distributed) among them can affect model training, system efficiency, scalability and stability. Despite these challenges, the integration of new clients into FL systems presents opportunities to enhance data diversity, improve learning performance, and leverage distributed computational power. In contrast to other fields of application such as the distributed optimization of word predictions on Gboard (where federated learning once originated), there are usually only a few clients in the production environment, which is why information from each new client becomes all the more valuable. This paper outlines strategies for effective client selection strategies and solutions for ensuring system scalability and stability. Using the example of images from optical quality inspection, it offers insights into practical approaches. In conclusion, this paper proposes that addressing the challenges presented by new client integration is crucial to the advancement and efficiency of distributed learning networks, thus paving the way for the adoption of Federated Learning in production environments.
Read more8/21/2024