Seamless Integration: Sampling Strategies in Federated Learning Systems

0

Sign in to get full access
Overview
- Federated learning enables collaborative machine learning without sharing raw data
- Sampling strategies are crucial for effective federated learning, as they determine which client devices participate in each round
- This paper examines different sampling strategies and their impact on federated learning performance
Plain English Explanation
Federated learning is a technique that allows multiple devices, like smartphones or factory machines, to collaboratively train a machine learning model without sharing their raw data. This is useful when the data is sensitive or distributed across many locations.
The key to making federated learning work is the sampling strategy - deciding which devices get to participate in each round of training. This paper looks at different sampling approaches and how they affect the performance and efficiency of the federated learning system.
Technical Explanation
The paper examines several federated learning sampling strategies:
- Random Sampling: Randomly select a subset of available client devices to participate in each round.
- Importance Sampling: Select clients based on the importance of their data, e.g., how representative it is of the overall dataset.
- Adaptive Sampling: Dynamically adjust the sampling distribution based on client performance and data quality over time.
The researchers evaluate these strategies through simulation experiments, measuring metrics like model accuracy, convergence speed, and communication efficiency. They find that adaptive sampling approaches can outperform random and importance-based sampling, especially in scenarios with data heterogeneity across clients.
Critical Analysis
The paper provides a comprehensive evaluation of sampling strategies for federated learning, an important practical consideration. However, it focuses solely on simulation experiments and does not validate the findings in real-world deployments.
Additionally, the paper does not address robustness to malicious or unreliable client devices, which is a crucial concern for federated learning in many applications. Further research is needed to understand how sampling strategies interact with security and privacy protections.
Conclusion
This paper demonstrates the significance of sampling strategies in federated learning systems. By carefully selecting which clients participate in each round of training, the researchers show it is possible to improve model accuracy, convergence speed, and communication efficiency - key factors for deploying federated learning in real-world manufacturing and collaborative settings. However, additional work is needed to validate these findings in more diverse scenarios and address potential security and robustness concerns.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Seamless Integration: Sampling Strategies in Federated Learning Systems
Tatjana Legler, Vinit Hegiste, Martin Ruskowski
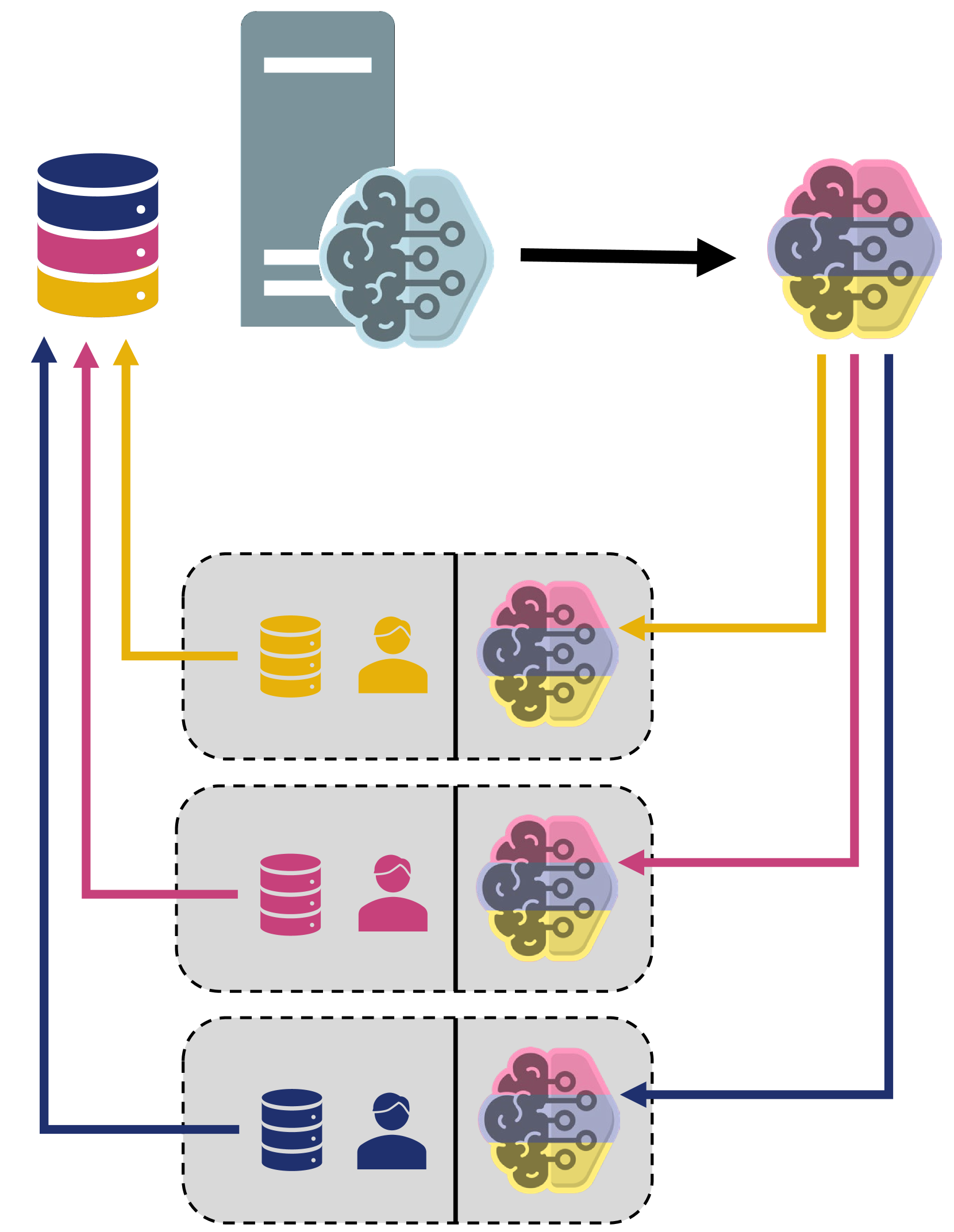
Federated Learning (FL) represents a paradigm shift in the field of machine learning, offering an approach for a decentralized training of models across a multitude of devices while maintaining the privacy of local data. However, the dynamic nature of FL systems, characterized by the ongoing incorporation of new clients with potentially diverse data distributions and computational capabilities, poses a significant challenge to the stability and efficiency of these distributed learning networks. The seamless integration of new clients is imperative to sustain and enhance the performance and robustness of FL systems. This paper looks into the complexities of integrating new clients into existing FL systems and explores how data heterogeneity and varying data distribution (not independent and identically distributed) among them can affect model training, system efficiency, scalability and stability. Despite these challenges, the integration of new clients into FL systems presents opportunities to enhance data diversity, improve learning performance, and leverage distributed computational power. In contrast to other fields of application such as the distributed optimization of word predictions on Gboard (where federated learning once originated), there are usually only a few clients in the production environment, which is why information from each new client becomes all the more valuable. This paper outlines strategies for effective client selection strategies and solutions for ensuring system scalability and stability. Using the example of images from optical quality inspection, it offers insights into practical approaches. In conclusion, this paper proposes that addressing the challenges presented by new client integration is crucial to the advancement and efficiency of distributed learning networks, thus paving the way for the adoption of Federated Learning in production environments.
Read more8/21/2024
📶
0
Federated Learning Can Find Friends That Are Advantageous
Nazarii Tupitsa, Samuel Horv'ath, Martin Tak'av{c}, Eduard Gorbunov
In Federated Learning (FL), the distributed nature and heterogeneity of client data present both opportunities and challenges. While collaboration among clients can significantly enhance the learning process, not all collaborations are beneficial; some may even be detrimental. In this study, we introduce a novel algorithm that assigns adaptive aggregation weights to clients participating in FL training, identifying those with data distributions most conducive to a specific learning objective. We demonstrate that our aggregation method converges no worse than the method that aggregates only the updates received from clients with the same data distribution. Furthermore, empirical evaluations consistently reveal that collaborations guided by our algorithm outperform traditional FL approaches. This underscores the critical role of judicious client selection and lays the foundation for more streamlined and effective FL implementations in the coming years.
Read more7/18/2024
0
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
Read more5/28/2024
0
Advances in Robust Federated Learning: Heterogeneity Considerations
Chuan Chen, Tianchi Liao, Xiaojun Deng, Zihou Wu, Sheng Huang, Zibin Zheng
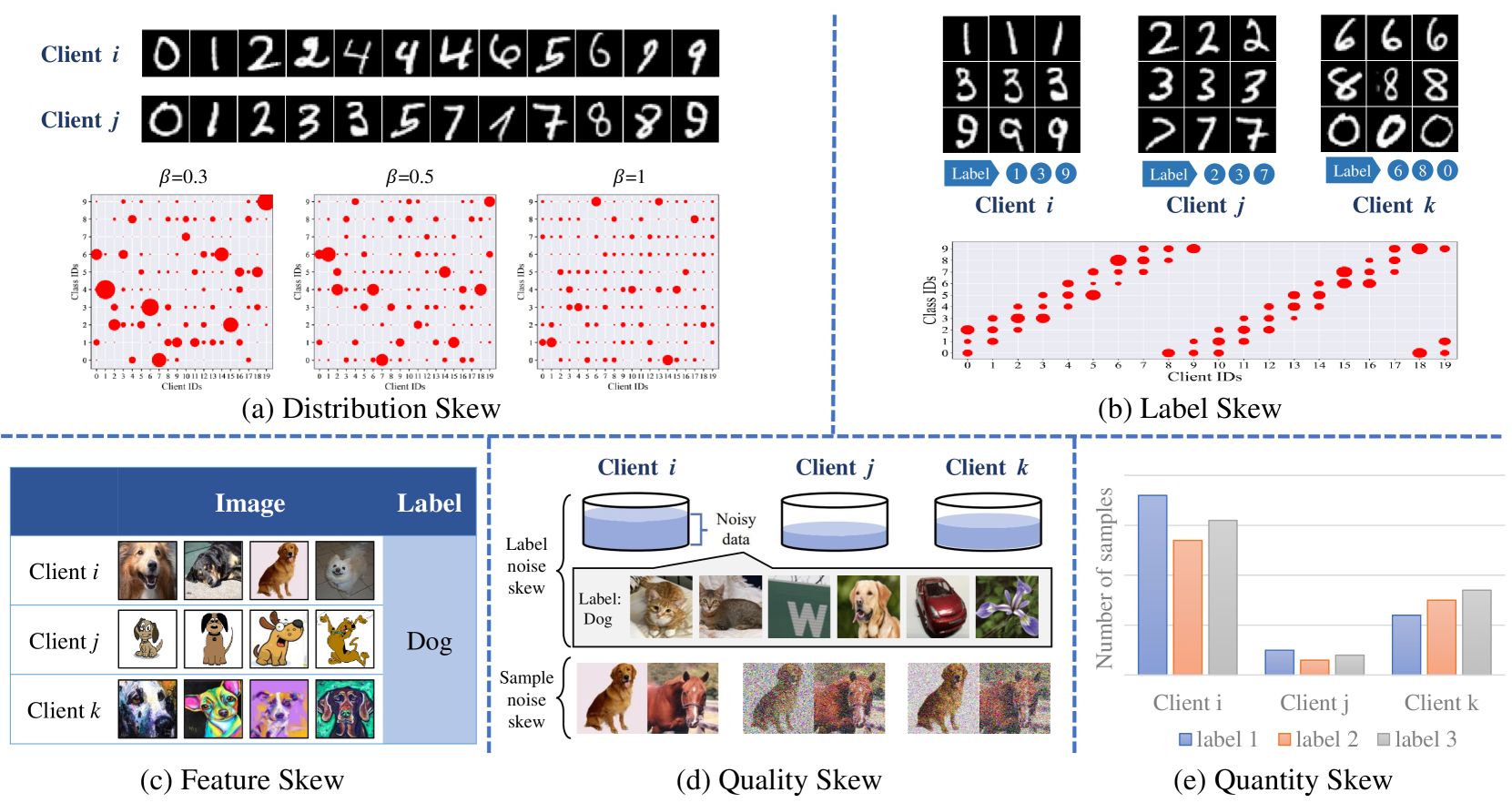
In the field of heterogeneous federated learning (FL), the key challenge is to efficiently and collaboratively train models across multiple clients with different data distributions, model structures, task objectives, computational capabilities, and communication resources. This diversity leads to significant heterogeneity, which increases the complexity of model training. In this paper, we first outline the basic concepts of heterogeneous federated learning and summarize the research challenges in federated learning in terms of five aspects: data, model, task, device, and communication. In addition, we explore how existing state-of-the-art approaches cope with the heterogeneity of federated learning, and categorize and review these approaches at three different levels: data-level, model-level, and architecture-level. Subsequently, the paper extensively discusses privacy-preserving strategies in heterogeneous federated learning environments. Finally, the paper discusses current open issues and directions for future research, aiming to promote the further development of heterogeneous federated learning.
Read more5/17/2024