Adaptive hp-Polynomial Based Sparse Grid Collocation Algorithms for Piecewise Smooth Functions with Kinks

0
Sign in to get full access
Overview
- This research paper presents an adaptive hp-polynomial based sparse grid collocation algorithm for approximating piecewise smooth functions with kinks.
- The algorithm uses a hierarchical sparse grid structure and adapts the local polynomial degree (h-refinement) and grid density (p-refinement) based on the smoothness of the target function.
- The method is designed to efficiently handle functions with discontinuities or sharp changes, known as "kinks," which are common in many real-world applications.
Plain English Explanation
The paper describes a new way to numerically approximate functions that have sudden changes or jumps in their behavior, called "kinks." Many real-world functions, like stock prices or weather patterns, have these kinks.
The approach uses a technique called "sparse grids," which is a way to efficiently sample the function at a small number of carefully chosen points, rather than on a dense grid. It also adapts the degree of the polynomial used to approximate the function, as well as the density of the grid, based on how smooth the function is in different regions.
This allows the algorithm to focus its computational resources on the tricky parts of the function with kinks, while using simpler approximations in the smoother regions. The goal is to get an accurate representation of the function without having to do a lot of expensive computations.
Technical Explanation
The paper introduces an adaptive hp-polynomial based sparse grid collocation algorithm for approximating piecewise smooth functions with kinks. The method is built on hierarchical sparse grids, which adaptively refine the grid density (h-refinement) and polynomial degree (p-refinement) based on the local smoothness of the function.
The algorithm starts with a coarse sparse grid and iteratively adds more grid points and increases the polynomial degree in regions with kinks or low smoothness. This adaptive refinement strategy allows the method to efficiently capture the sharp features of the function while maintaining a relatively small number of grid points.
The paper presents numerical experiments demonstrating the performance of the adaptive hp-sparse grid approach on several test functions with kinks. The results show that the method can achieve high accuracy with far fewer degrees of freedom compared to traditional uniform grid approaches or non-adaptive sparse grids.
Critical Analysis
The paper provides a thorough theoretical and numerical analysis of the proposed adaptive hp-sparse grid collocation algorithm. The authors address the challenges of approximating functions with kinks, which can be difficult for many standard numerical methods.
One potential limitation of the approach is that it assumes the function is piecewise smooth, with a known number and location of kinks. In practice, this information may not be available a priori, and the algorithm would need to be extended to automatically detect the kink locations.
Additionally, the paper focuses on scalar-valued functions, but many real-world applications involve vector-valued or matrix-valued functions. Extending the adaptive hp-sparse grid method to these higher-dimensional settings could be an interesting area for future research.
Overall, the proposed algorithm appears to be a promising approach for efficiently approximating piecewise smooth functions with kinks, and the paper makes a valuable contribution to the field of numerical analysis and scientific computing.
Conclusion
This research paper presents an adaptive hp-polynomial based sparse grid collocation algorithm for approximating piecewise smooth functions with kinks. The method uses a hierarchical sparse grid structure and adaptively refines the grid density and polynomial degree based on the local smoothness of the target function.
The key innovation is the ability to efficiently capture sharp features and discontinuities in the function while maintaining a relatively small number of grid points. The numerical experiments demonstrate the effectiveness of the approach, which could have important applications in fields such as engineering, physics, and finance, where piecewise smooth functions with kinks are commonly encountered.
While the paper focuses on scalar-valued functions, extending the adaptive hp-sparse grid method to vector-valued and matrix-valued functions is an interesting direction for future research. Overall, this work represents a significant advance in the field of numerical approximation and has the potential to impact a wide range of computational science and engineering problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive hp-Polynomial Based Sparse Grid Collocation Algorithms for Piecewise Smooth Functions with Kinks
Hendrik Wilka, Jens Lang
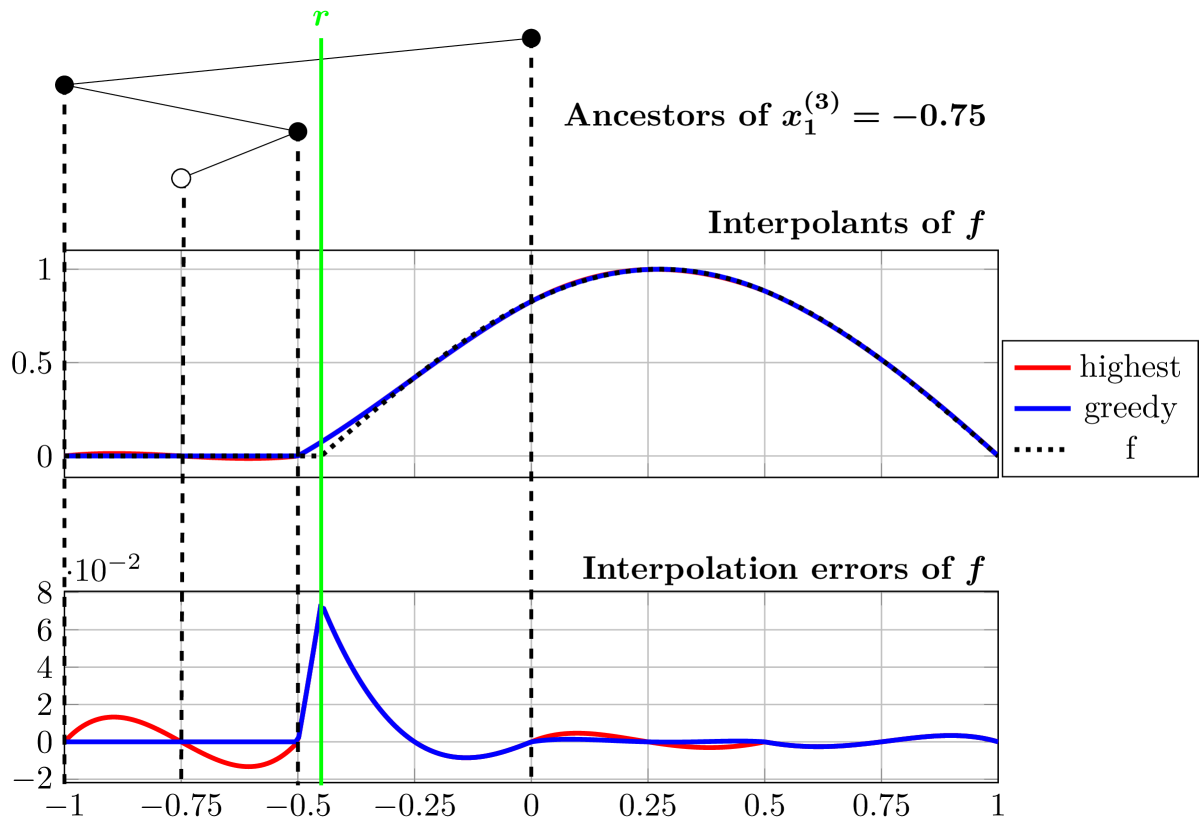
High-dimensional interpolation problems appear in various applications of uncertainty quantification, stochastic optimization and machine learning. Such problems are computationally expensive and request the use of adaptive grid generation strategies like anisotropic sparse grids to mitigate the curse of dimensionality. However, it is well known that the standard dimension-adaptive sparse grid method converges very slowly or even fails in the case of non-smooth functions. For piecewise smooth functions with kinks, we construct two novel hp-adaptive sparse grid collocation algorithms that combine low-order basis functions with local support in parts of the domain with less regularity and variable-order basis functions elsewhere. Spatial refinement is realized by means of a hierarchical multivariate knot tree which allows the construction of localised hierarchical basis functions with varying order. Hierarchical surplus is used as an error indicator to automatically detect the non-smooth region and adaptively refine the collocation points there. The local polynomial degrees are optionally selected by a greedy approach or a kink detection procedure. Three numerical benchmark examples with different dimensions are discussed and comparison with locally linear and highest degree basis functions are given to show the efficiency and accuracy of the proposed methods.
Read more4/4/2024

0
Machine Learning Optimized Orthogonal Basis Piecewise Polynomial Approximation
Hannes Waclawek, Stefan Huber
Piecewise Polynomials (PPs) are utilized in several engineering disciplines, like trajectory planning, to approximate position profiles given in the form of a set of points. While the approximation target along with domain-specific requirements, like Ck -continuity, can be formulated as a system of equations and a result can be computed directly, such closed-form solutions posses limited flexibility with respect to polynomial degrees, polynomial bases or adding further domain-specific requirements. Sufficiently complex optimization goals soon call for the use of numerical methods, like gradient descent. Since gradient descent lies at the heart of training Artificial Neural Networks (ANNs), modern Machine Learning (ML) frameworks like TensorFlow come with a set of gradient-based optimizers potentially suitable for a wide range of optimization problems beyond the training task for ANNs. Our approach is to utilize the versatility of PP models and combine it with the potential of modern ML optimizers for the use in function approximation in 1D trajectory planning in the context of electronic cam design. We utilize available optimizers of the ML framework TensorFlow directly, outside of the scope of ANNs, to optimize model parameters of our PP model. In this paper, we show how an orthogonal polynomial basis contributes to improving approximation and continuity optimization performance. Utilizing Chebyshev polynomials of the first kind, we develop a novel regularization approach enabling clearly improved convergence behavior. We show that, using this regularization approach, Chebyshev basis performs better than power basis for all relevant optimizers in the combined approximation and continuity optimization setting and demonstrate usability of the presented approach within the electronic cam domain.
Read more5/9/2024
0
Learning smooth functions in high dimensions: from sparse polynomials to deep neural networks
Ben Adcock, Simone Brugiapaglia, Nick Dexter, Sebastian Moraga
Learning approximations to smooth target functions of many variables from finite sets of pointwise samples is an important task in scientific computing and its many applications in computational science and engineering. Despite well over half a century of research on high-dimensional approximation, this remains a challenging problem. Yet, significant advances have been made in the last decade towards efficient methods for doing this, commencing with so-called sparse polynomial approximation methods and continuing most recently with methods based on Deep Neural Networks (DNNs). In tandem, there have been substantial advances in the relevant approximation theory and analysis of these techniques. In this work, we survey this recent progress. We describe the contemporary motivations for this problem, which stem from parametric models and computational uncertainty quantification; the relevant function classes, namely, classes of infinite-dimensional, Banach-valued, holomorphic functions; fundamental limits of learnability from finite data for these classes; and finally, sparse polynomial and DNN methods for efficiently learning such functions from finite data. For the latter, there is currently a significant gap between the approximation theory of DNNs and the practical performance of deep learning. Aiming to narrow this gap, we develop the topic of practical existence theory, which asserts the existence of dimension-independent DNN architectures and training strategies that achieve provably near-optimal generalization errors in terms of the amount of training data.
Read more4/8/2024
0
Tensor Decomposition Meets RKHS: Efficient Algorithms for Smooth and Misaligned Data
Brett W. Larsen, Tamara G. Kolda, Anru R. Zhang, Alex H. Williams
The canonical polyadic (CP) tensor decomposition decomposes a multidimensional data array into a sum of outer products of finite-dimensional vectors. Instead, we can replace some or all of the vectors with continuous functions (infinite-dimensional vectors) from a reproducing kernel Hilbert space (RKHS). We refer to tensors with some infinite-dimensional modes as quasitensors, and the approach of decomposing a tensor with some continuous RKHS modes is referred to as CP-HiFi (hybrid infinite and finite dimensional) tensor decomposition. An advantage of CP-HiFi is that it can enforce smoothness in the infinite dimensional modes. Further, CP-HiFi does not require the observed data to lie on a regular and finite rectangular grid and naturally incorporates misaligned data. We detail the methodology and illustrate it on a synthetic example.
Read more8/13/2024