Learning smooth functions in high dimensions: from sparse polynomials to deep neural networks
2404.03761
0
0
Abstract
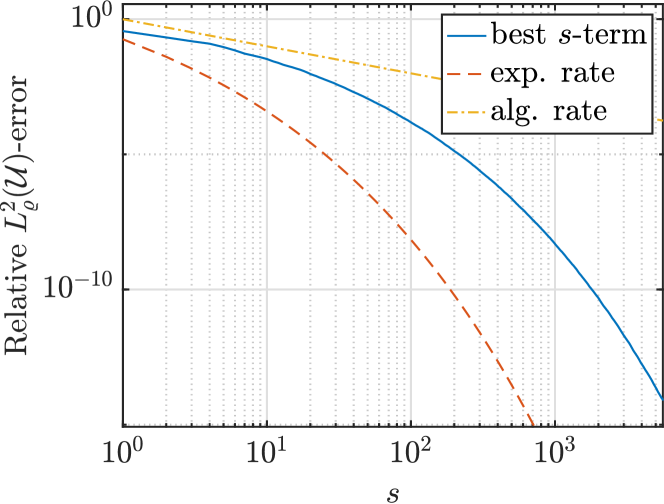
Learning approximations to smooth target functions of many variables from finite sets of pointwise samples is an important task in scientific computing and its many applications in computational science and engineering. Despite well over half a century of research on high-dimensional approximation, this remains a challenging problem. Yet, significant advances have been made in the last decade towards efficient methods for doing this, commencing with so-called sparse polynomial approximation methods and continuing most recently with methods based on Deep Neural Networks (DNNs). In tandem, there have been substantial advances in the relevant approximation theory and analysis of these techniques. In this work, we survey this recent progress. We describe the contemporary motivations for this problem, which stem from parametric models and computational uncertainty quantification; the relevant function classes, namely, classes of infinite-dimensional, Banach-valued, holomorphic functions; fundamental limits of learnability from finite data for these classes; and finally, sparse polynomial and DNN methods for efficiently learning such functions from finite data. For the latter, there is currently a significant gap between the approximation theory of DNNs and the practical performance of deep learning. Aiming to narrow this gap, we develop the topic of practical existence theory, which asserts the existence of dimension-independent DNN architectures and training strategies that achieve provably near-optimal generalization errors in terms of the amount of training data.
Create account to get full access
Overview
- This paper explores the problem of learning smooth functions in high-dimensional spaces, which is a fundamental challenge in machine learning and has important applications in areas like scientific computing and engineering.
- The authors investigate how different techniques, from sparse polynomials to deep neural networks, can be used to effectively learn these smooth functions.
- They provide a comprehensive overview of the theoretical and practical considerations involved in this task, highlighting the key trade-offs and design choices that researchers and practitioners must navigate.
Plain English Explanation
Imagine you're trying to understand how some complex system behaves, like the weather or the stock market. You can't directly observe all the factors that influence this system, but you can collect data on various inputs and outputs. The goal is to find a mathematical function that can accurately predict the output given the inputs.
This is a challenging problem, especially when you're dealing with high-dimensional systems that have a large number of inputs. Traditional approaches, like using simple polynomial functions, often struggle to capture the complex, smooth relationships between the inputs and outputs.
In this paper, the authors explore more advanced techniques, such as sparse polynomials and deep neural networks, to overcome these challenges. They delve into the theoretical foundations and practical considerations of these methods, helping researchers and practitioners understand the trade-offs and choose the best approach for their specific problem.
The key idea is to find a function that can smoothly and accurately capture the relationships in high-dimensional data, without becoming overly complex or prone to overfitting. This has important applications in fields like scientific computing, engineering, and machine learning, where being able to model and predict complex, high-dimensional phenomena is crucial.
Technical Explanation
The paper begins by discussing the motivations and challenges involved in learning smooth functions in high dimensions. The authors highlight the importance of this problem in various application domains, such as scientific computing, engineering, and machine learning, where accurately modeling complex, high-dimensional phenomena is essential.
One of the key challenges is the curse of dimensionality, which makes it difficult to construct effective function approximators as the number of input variables increases. The authors explore how traditional approaches, such as using sparse polynomials, can struggle to capture the complex, smooth relationships in high-dimensional data.
To address these challenges, the paper delves into more advanced techniques, including deep neural networks and adaptive sparse polynomial methods. The authors provide a comprehensive overview of the theoretical and practical considerations involved in applying these methods, highlighting the trade-offs and design choices that researchers and practitioners must navigate.
The paper also discusses the potential pitfalls and limitations of these approaches, such as the risk of overfitting or the difficulty of ensuring reliability in high-dimensional settings. The authors encourage readers to think critically about the research and consider potential areas for further exploration and improvement.
Critical Analysis
The paper provides a thorough and well-researched exploration of the challenges and potential solutions for learning smooth functions in high-dimensional spaces. The authors' comprehensive coverage of both traditional and more advanced techniques, such as sparse polynomials and deep neural networks, is a particular strength of the work.
One potential limitation of the paper is that it does not delve deeply into the practical implementation details or the specific trade-offs between the different methods. While the theoretical foundations are well-explained, readers may benefit from more concrete examples or case studies to better understand how these techniques perform in real-world scenarios.
Additionally, the paper could have addressed some of the potential ethical and societal implications of this research, particularly in domains where high-dimensional modeling can have significant impacts on decision-making or resource allocation. Incorporating such considerations could further strengthen the paper's relevance and impact.
Overall, the paper represents a valuable contribution to the literature on high-dimensional function learning, providing a solid foundation for researchers and practitioners to build upon. By encouraging critical thinking and highlighting areas for further exploration, the authors have set the stage for continued advancements in this important and challenging field.
Conclusion
This paper offers a comprehensive exploration of the problem of learning smooth functions in high-dimensional spaces, a fundamental challenge with far-reaching applications in scientific computing, engineering, and machine learning. The authors investigate how different techniques, from sparse polynomials to deep neural networks, can be leveraged to effectively model these complex, high-dimensional relationships.
By providing a thorough overview of the theoretical and practical considerations involved, the paper equips researchers and practitioners with the knowledge to navigate the trade-offs and choose the most suitable approach for their specific problem. The authors' critical analysis also encourages readers to think deeply about the potential limitations and areas for further research, ultimately driving progress in this important field.
As the demand for accurate, high-dimensional modeling continues to grow, this paper serves as a valuable resource for understanding the state of the art and charting the path forward. By bridging the gap between theoretical advances and practical applications, the authors have made a significant contribution to the ongoing efforts to harness the power of complex, high-dimensional data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Approximation and interpolation of deep neural networks
Vlad-Raul Constantinescu, Ionel Popescu
0
0
In this paper, we prove that in the overparametrized regime, deep neural network provide universal approximations and can interpolate any data set, as long as the activation function is locally in $L^1(RR)$ and not an affine function. Additionally, if the activation function is smooth and such an interpolation networks exists, then the set of parameters which interpolate forms a manifold. Furthermore, we give a characterization of the Hessian of the loss function evaluated at the interpolation points. In the last section, we provide a practical probabilistic method of finding such a point under general conditions on the activation function.
4/26/2024
Neural network learns low-dimensional polynomials with SGD near the information-theoretic limit
Jason D. Lee, Kazusato Oko, Taiji Suzuki, Denny Wu
0
0
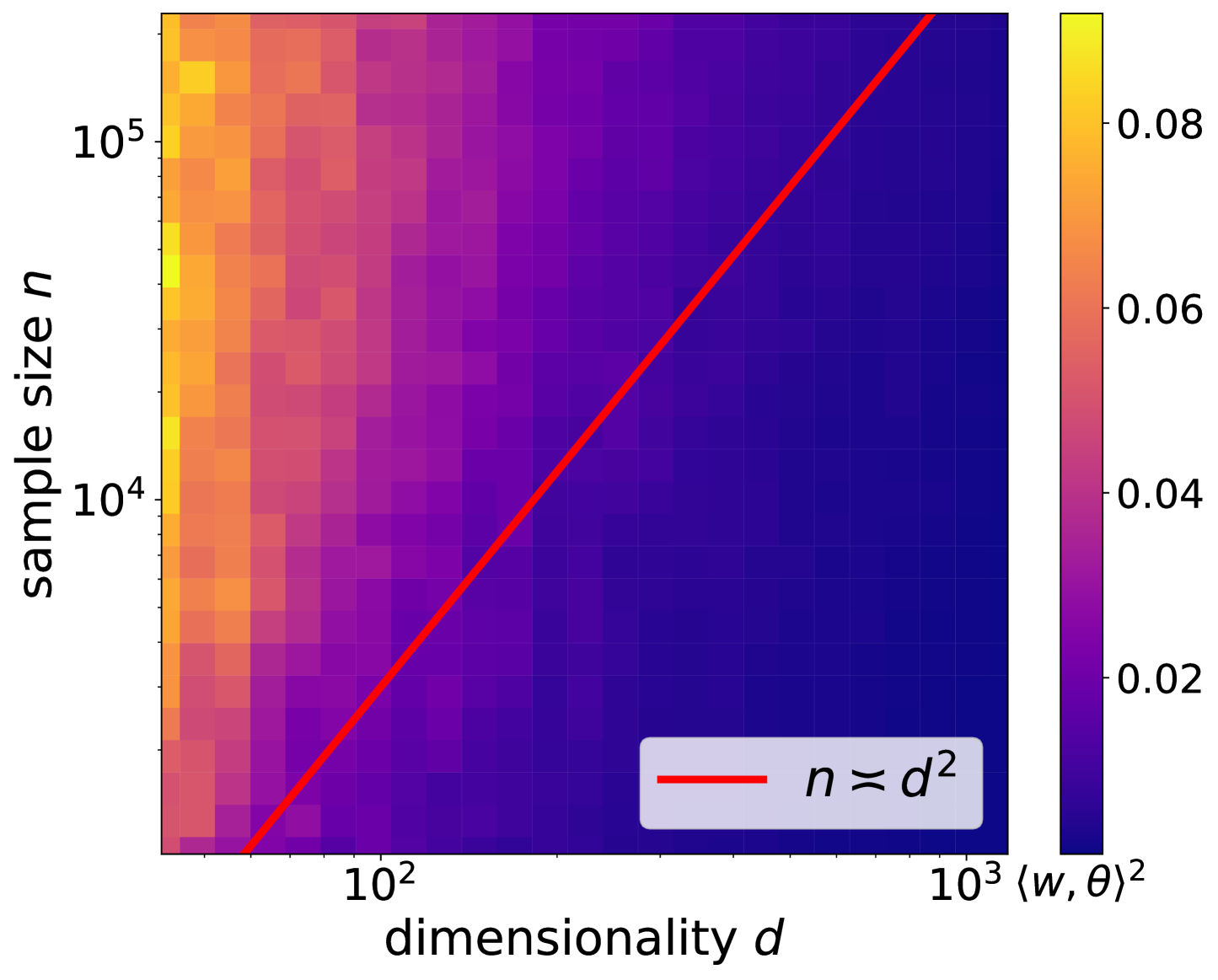
We study the problem of gradient descent learning of a single-index target function $f_*(boldsymbol{x}) = textstylesigma_*left(langleboldsymbol{x},boldsymbol{theta}rangleright)$ under isotropic Gaussian data in $mathbb{R}^d$, where the link function $sigma_*:mathbb{R}tomathbb{R}$ is an unknown degree $q$ polynomial with information exponent $p$ (defined as the lowest degree in the Hermite expansion). Prior works showed that gradient-based training of neural networks can learn this target with $ngtrsim d^{Theta(p)}$ samples, and such statistical complexity is predicted to be necessary by the correlational statistical query lower bound. Surprisingly, we prove that a two-layer neural network optimized by an SGD-based algorithm learns $f_*$ of arbitrary polynomial link function with a sample and runtime complexity of $n asymp T asymp C(q) cdot dmathrm{polylog} d$, where constant $C(q)$ only depends on the degree of $sigma_*$, regardless of information exponent; this dimension dependence matches the information theoretic limit up to polylogarithmic factors. Core to our analysis is the reuse of minibatch in the gradient computation, which gives rise to higher-order information beyond correlational queries.
6/4/2024

Physics-informed deep learning and compressive collocation for high-dimensional diffusion-reaction equations: practical existence theory and numerics
Simone Brugiapaglia, Nick Dexter, Samir Karam, Weiqi Wang
0
0
On the forefront of scientific computing, Deep Learning (DL), i.e., machine learning with Deep Neural Networks (DNNs), has emerged a powerful new tool for solving Partial Differential Equations (PDEs). It has been observed that DNNs are particularly well suited to weakening the effect of the curse of dimensionality, a term coined by Richard E. Bellman in the late `50s to describe challenges such as the exponential dependence of the sample complexity, i.e., the number of samples required to solve an approximation problem, on the dimension of the ambient space. However, although DNNs have been used to solve PDEs since the `90s, the literature underpinning their mathematical efficiency in terms of numerical analysis (i.e., stability, accuracy, and sample complexity), is only recently beginning to emerge. In this paper, we leverage recent advancements in function approximation using sparsity-based techniques and random sampling to develop and analyze an efficient high-dimensional PDE solver based on DL. We show, both theoretically and numerically, that it can compete with a novel stable and accurate compressive spectral collocation method. In particular, we demonstrate a new practical existence theorem, which establishes the existence of a class of trainable DNNs with suitable bounds on the network architecture and a sufficient condition on the sample complexity, with logarithmic or, at worst, linear scaling in dimension, such that the resulting networks stably and accurately approximate a diffusion-reaction PDE with high probability.
6/11/2024
Polynomial-Augmented Neural Networks (PANNs) with Weak Orthogonality Constraints for Enhanced Function and PDE Approximation
Madison Cooley, Shandian Zhe, Robert M. Kirby, Varun Shankar
0
0
We present polynomial-augmented neural networks (PANNs), a novel machine learning architecture that combines deep neural networks (DNNs) with a polynomial approximant. PANNs combine the strengths of DNNs (flexibility and efficiency in higher-dimensional approximation) with those of polynomial approximation (rapid convergence rates for smooth functions). To aid in both stable training and enhanced accuracy over a variety of problems, we present (1) a family of orthogonality constraints that impose mutual orthogonality between the polynomial and the DNN within a PANN; (2) a simple basis pruning approach to combat the curse of dimensionality introduced by the polynomial component; and (3) an adaptation of a polynomial preconditioning strategy to both DNNs and polynomials. We test the resulting architecture for its polynomial reproduction properties, ability to approximate both smooth functions and functions of limited smoothness, and as a method for the solution of partial differential equations (PDEs). Through these experiments, we demonstrate that PANNs offer superior approximation properties to DNNs for both regression and the numerical solution of PDEs, while also offering enhanced accuracy over both polynomial and DNN-based regression (each) when regressing functions with limited smoothness.
6/5/2024