Adaptive Mix for Semi-Supervised Medical Image Segmentation

0

Sign in to get full access
Overview
- Introduces an "Adaptive Mix" approach for semi-supervised medical image segmentation
- Leverages both labeled and unlabeled data to improve model performance
- Adaptively mixes labeled and unlabeled data based on prediction uncertainty
Plain English Explanation
The paper presents a new method called "Adaptive Mix" for improving medical image segmentation models by using both labeled and unlabeled data. In many real-world scenarios, getting labeled medical data can be difficult and expensive, while unlabeled data is more readily available.
The key idea of Adaptive Mix is to adaptively combine the labeled and unlabeled data during training, based on the model's prediction uncertainty. For areas of the image where the model is less certain about the segmentation, more unlabeled data is used. This helps the model learn from the unlabeled data and improve its overall performance, without overfitting to the limited labeled data.
The authors show that this Adaptive Mix approach outperforms previous semi-supervised methods for medical image segmentation, achieving state-of-the-art results on several benchmark datasets. By effectively leveraging both labeled and unlabeled data, Adaptive Mix can lead to more accurate and robust segmentation models, which is crucial for many medical imaging applications.
Technical Explanation
The paper proposes an "Adaptive Mix" approach for semi-supervised medical image segmentation. The core idea is to adaptively mix labeled and unlabeled data during training, based on the model's prediction uncertainty.
The authors first train a segmentation model using the limited labeled data. They then use this model to generate predicted segmentation maps for the unlabeled data. The prediction uncertainty for each pixel is estimated using the model's output probability distribution.
For areas of the image where the model is more uncertain about the segmentation, the authors increase the mixing proportion of unlabeled data during training. Conversely, for areas where the model is more confident, they use more of the labeled data.
This Adaptive Mix strategy allows the model to learn from the unlabeled data in regions where it needs more guidance, while still prioritizing the labeled data where it is most helpful. The authors demonstrate that this approach outperforms previous semi-supervised methods on several medical image segmentation benchmarks.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Adaptive Mix method, comparing it against a range of state-of-the-art semi-supervised approaches across multiple medical imaging datasets.
One potential limitation is that the method relies on accurate uncertainty estimation to drive the adaptive mixing. If the model's uncertainty estimates are not well-calibrated, this could negatively impact the performance. The authors do not discuss any potential issues with uncertainty estimation in their experiments.
Additionally, the paper could benefit from a more in-depth analysis of the types of medical imaging tasks and datasets where Adaptive Mix is most effective. Understanding the specific characteristics of the data and problem domains that are well-suited for this approach would help guide future applications.
Overall, the Adaptive Mix method represents a promising advance in semi-supervised medical image segmentation. Further research on robust uncertainty estimation and the broader applicability of the technique could further strengthen its impact.
Conclusion
The "Adaptive Mix" approach presented in this paper offers an effective way to leverage both labeled and unlabeled medical image data to improve segmentation performance. By adaptively combining the two data sources based on prediction uncertainty, the model can learn valuable information from the unlabeled data without overfitting to the limited labeled examples.
The strong empirical results demonstrate the potential of this semi-supervised technique to enhance medical image analysis capabilities, which could have important implications for clinical workflows and patient outcomes. As the authors suggest, further research on uncertainty estimation and the generalization of Adaptive Mix could lead to even more robust and versatile medical image segmentation models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Mix for Semi-Supervised Medical Image Segmentation
Zhiqiang Shen, Peng Cao, Junming Su, Jinzhu Yang, Osmar R. Zaiane
Mix-up is a key technique for consistency regularization-based semi-supervised learning methods, generating strong-perturbed samples for strong-weak pseudo-supervision. Existing mix-up operations are performed either randomly or with predefined rules, such as replacing low-confidence patches with high-confidence ones. The former lacks control over the perturbation degree, leading to overfitting on randomly perturbed samples, while the latter tends to generate images with trivial perturbations, both of which limit the effectiveness of consistency learning. This paper aims to answer the following question: How can image mix-up perturbation be adaptively performed during training? To this end, we propose an Adaptive Mix algorithm (AdaMix) for image mix-up in a self-paced learning manner. Given that, in general, a model's performance gradually improves during training, AdaMix is equipped with a self-paced curriculum that, in the initial training stage, provides relatively simple perturbed samples and then gradually increases the difficulty of perturbed images by adaptively controlling the perturbation degree based on the model's learning state estimated by a self-paced regularize. We develop three frameworks with our AdaMix, i.e., AdaMix-ST, AdaMix-MT, and AdaMix-CT, for semi-supervised medical image segmentation. Extensive experiments on three public datasets, including both 2D and 3D modalities, show that the proposed frameworks are capable of achieving superior performance. For example, compared with the state-of-the-art, AdaMix-CT achieves relative improvements of 2.62% in Dice and 48.25% in average surface distance on the ACDC dataset with 10% labeled data. The results demonstrate that mix-up operations with dynamically adjusted perturbation strength based on the segmentation model's state can significantly enhance the effectiveness of consistency regularization.
Read more8/1/2024

0
SUMix: Mixup with Semantic and Uncertain Information
Huafeng Qin, Xin Jin, Hongyu Zhu, Hongchao Liao, Moun^im A. El-Yacoubi, Xinbo Gao
Mixup data augmentation approaches have been applied for various tasks of deep learning to improve the generalization ability of deep neural networks. Some existing approaches CutMix, SaliencyMix, etc. randomly replace a patch in one image with patches from another to generate the mixed image. Similarly, the corresponding labels are linearly combined by a fixed ratio $lambda$ by l. The objects in two images may be overlapped during the mixing process, so some semantic information is corrupted in the mixed samples. In this case, the mixed image does not match the mixed label information. Besides, such a label may mislead the deep learning model training, which results in poor performance. To solve this problem, we proposed a novel approach named SUMix to learn the mixing ratio as well as the uncertainty for the mixed samples during the training process. First, we design a learnable similarity function to compute an accurate mix ratio. Second, an approach is investigated as a regularized term to model the uncertainty of the mixed samples. We conduct experiments on five image benchmarks, and extensive experimental results imply that our method is capable of improving the performance of classifiers with different cutting-based mixup approaches. The source code is available at https://github.com/JinXins/SUMix.
Read more9/11/2024
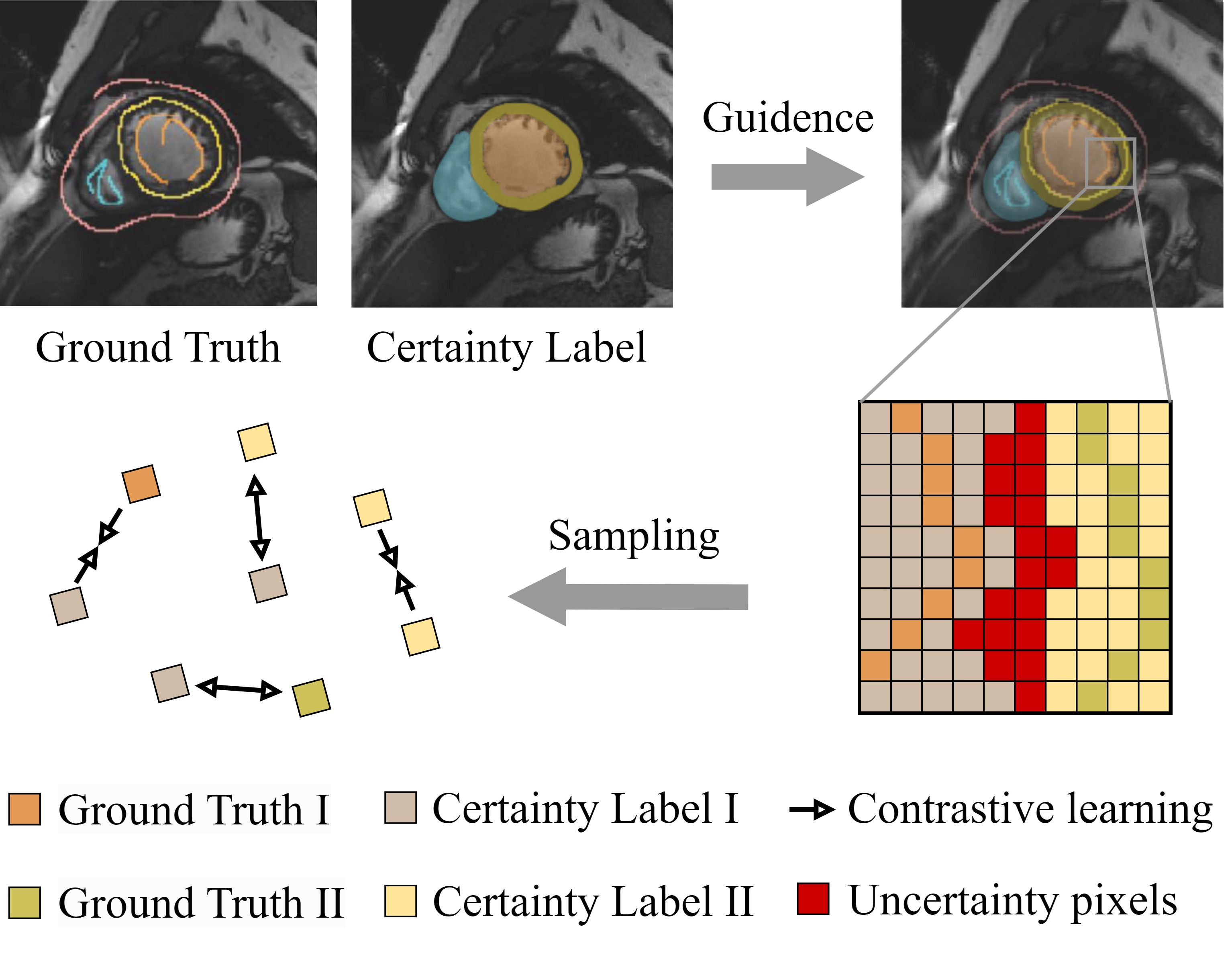
0
PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
Yu Lei, Haolun Luo, Lituan Wang, Zhenwei Zhang, Lei Zhang
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
Read more5/21/2024

0
A Survey on Mixup Augmentations and Beyond
Xin Jin, Hongyu Zhu, Siyuan Li, Zedong Wang, Zicheng Liu, Chang Yu, Huafeng Qin, Stan Z. Li
As Deep Neural Networks have achieved thrilling breakthroughs in the past decade, data augmentations have garnered increasing attention as regularization techniques when massive labeled data are unavailable. Among existing augmentations, Mixup and relevant data-mixing methods that convexly combine selected samples and the corresponding labels are widely adopted because they yield high performances by generating data-dependent virtual data while easily migrating to various domains. This survey presents a comprehensive review of foundational mixup methods and their applications. We first elaborate on the training pipeline with mixup augmentations as a unified framework containing modules. A reformulated framework could contain various mixup methods and give intuitive operational procedures. Then, we systematically investigate the applications of mixup augmentations on vision downstream tasks, various data modalities, and some analysis & theorems of mixup. Meanwhile, we conclude the current status and limitations of mixup research and point out further work for effective and efficient mixup augmentations. This survey can provide researchers with the current state of the art in mixup methods and provide some insights and guidance roles in the mixup arena. An online project with this survey is available at url{https://github.com/Westlake-AI/Awesome-Mixup}.
Read more9/10/2024