PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
2405.06288
0
0
Abstract
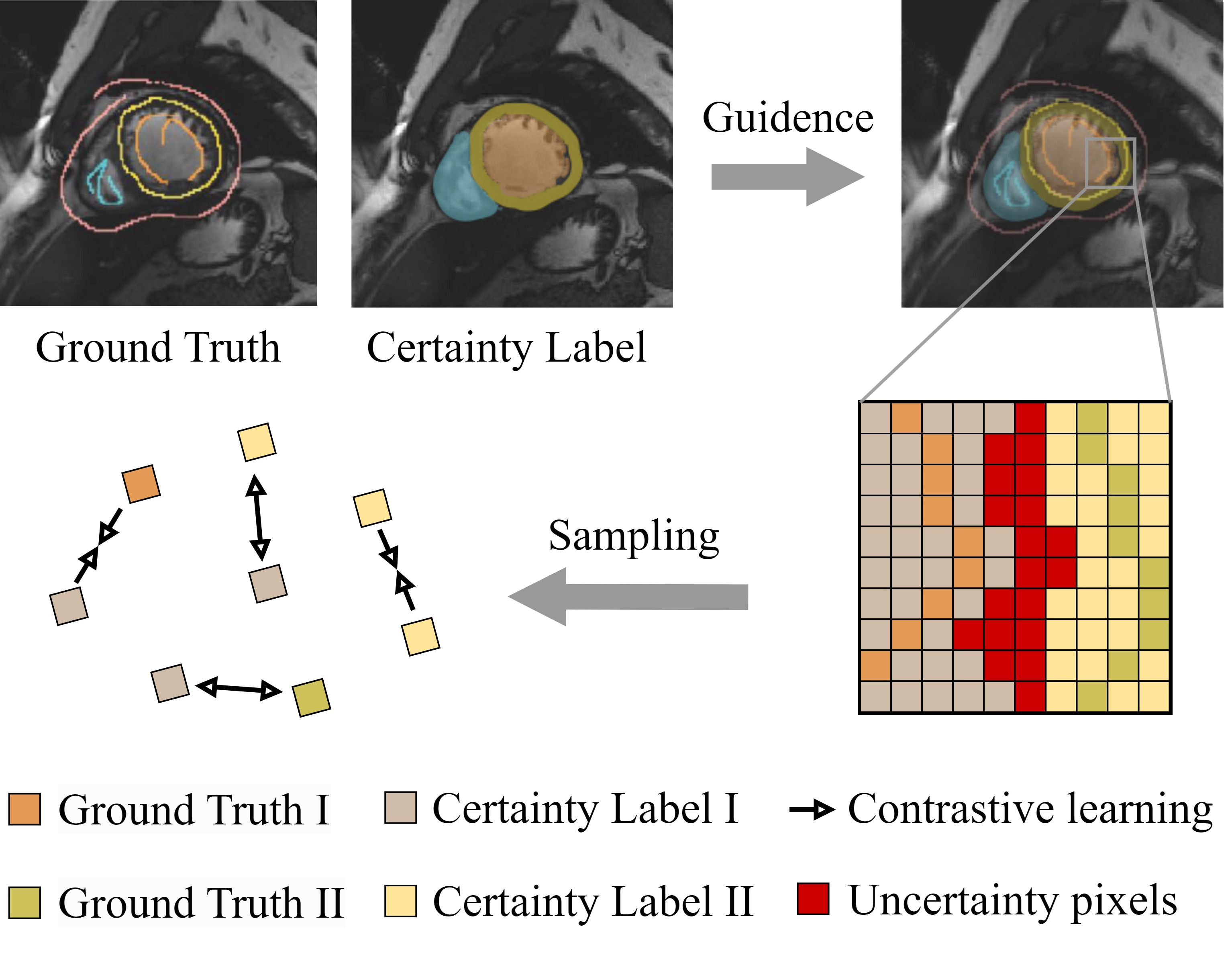
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
Create account to get full access
Overview
- This paper presents a novel weakly supervised medical image segmentation method called PCLMix, which combines pixel-level contrastive learning and dynamic mix augmentation.
- The key ideas are to leverage limited labeled data efficiently through contrastive learning at the pixel level, and to use a dynamic mix augmentation strategy to further improve performance.
- The proposed approach aims to advance the state-of-the-art in medical image segmentation, particularly for tasks with limited annotated data.
Plain English Explanation
Medical image segmentation is the process of dividing an image, such as an X-ray or MRI scan, into meaningful regions or structures (e.g., organs, tumors). This is an important task in healthcare, as it can help clinicians analyze and diagnose medical conditions more effectively.
However, medical image segmentation can be challenging because it often requires a large amount of labeled training data, which can be time-consuming and expensive to obtain. To address this, the authors of this paper have developed a new weakly supervised approach called PCLMix.
The core idea behind PCLMix is to use contrastive learning at the pixel level. Contrastive learning is a technique that trains a model to learn useful representations by comparing (or "contrasting") similar and dissimilar examples. In this case, the model learns to distinguish between pixels that belong to the same object (e.g., an organ) and pixels that belong to different objects.
Additionally, the researchers employ a dynamic mix augmentation strategy, which involves dynamically combining and blending different medical images during training. This helps the model learn more robust and generalizable features, even with limited labeled data.
By combining these two key ideas - pixel-level contrastive learning and dynamic mix augmentation - the PCLMix method is able to achieve state-of-the-art performance in medical image segmentation tasks, even when the amount of labeled data is relatively small.
Technical Explanation
The PCLMix method consists of two main components:
-
Pixel-Level Contrastive Learning (PCL): Instead of learning representations at the image level, the authors propose to learn representations at the pixel level. This means that the model learns to distinguish between pixels that belong to the same object (e.g., an organ) and pixels that belong to different objects. This is done by constructing pixel-level positive and negative pairs during training, and using a contrastive loss function to train the model to learn useful pixel-level representations.
-
Dynamic Mix Augmentation (DMA): The authors also introduce a novel data augmentation strategy called Dynamic Mix Augmentation (DMA). DMA involves dynamically mixing and blending different medical images during training, which helps the model learn more robust and generalizable features. The mixing process is controlled by a set of learnable parameters, which are optimized as part of the training process.
The authors evaluate the PCLMix method on several medical image segmentation datasets, including [object Object], [object Object], [object Object], and [object Object]. They demonstrate that PCLMix outperforms several state-of-the-art weakly supervised and semi-supervised medical image segmentation methods, particularly when the amount of labeled data is limited.
Critical Analysis
The researchers have made a strong contribution to the field of medical image segmentation by addressing the challenge of limited labeled data. The key ideas of pixel-level contrastive learning and dynamic mix augmentation are well-designed and show promising results.
However, there are a few potential limitations and areas for further research:
-
Generalization to different medical imaging modalities: The paper primarily focuses on evaluating the PCLMix method on CT and MRI images. It would be valuable to investigate how well the approach generalizes to other medical imaging modalities, such as [object Object] or ultrasound images.
-
Computational efficiency: The dynamic mix augmentation strategy adds an additional computational overhead during training. It would be important to assess the trade-off between the performance gains and the increased training time and resource requirements.
-
Interpretability and explainability: While the PCLMix method demonstrates strong empirical performance, it would be beneficial to better understand the internal workings of the model and the reasons behind its success. Incorporating techniques for interpreting and explaining the model's decisions could further enhance its usefulness in real-world medical settings.
Overall, the PCLMix method represents a significant step forward in advancing the state-of-the-art in weakly supervised medical image segmentation. The combination of pixel-level contrastive learning and dynamic mix augmentation is a clever and effective approach that deserves further exploration and refinement.
Conclusion
The PCLMix method proposed in this paper provides a novel solution to the challenge of limited labeled data in medical image segmentation. By leveraging pixel-level contrastive learning and dynamic mix augmentation, the authors have developed a weakly supervised approach that can achieve state-of-the-art performance, even with relatively small amounts of annotated data.
This work has the potential to significantly impact the field of medical image analysis, as it can enable more efficient and cost-effective development of segmentation models for various healthcare applications. The insights and techniques presented in this paper could also inspire further research into advanced weakly supervised and semi-supervised learning methods for medical imaging tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mixed Prototype Consistency Learning for Semi-supervised Medical Image Segmentation
Lijian Li
0
0
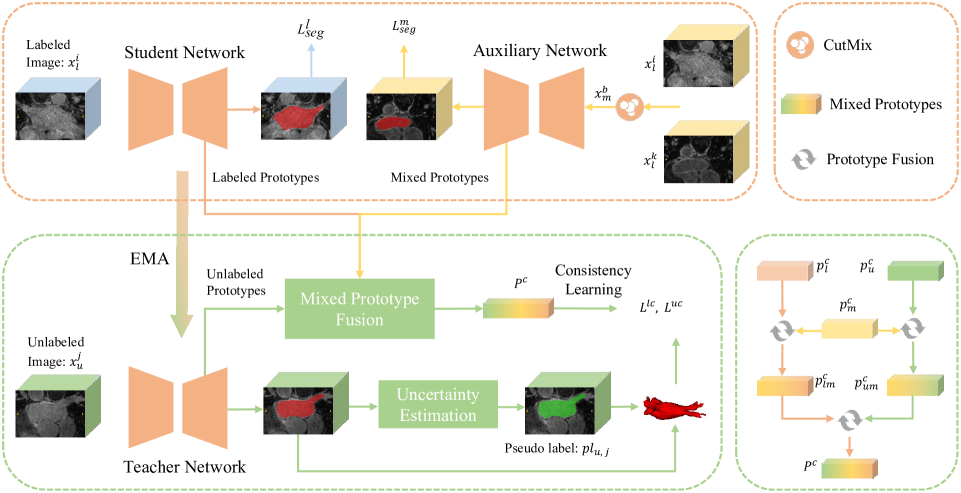
Recently, prototype learning has emerged in semi-supervised medical image segmentation and achieved remarkable performance. However, the scarcity of labeled data limits the expressiveness of prototypes in previous methods, potentially hindering the complete representation of prototypes for class embedding. To address this problem, we propose the Mixed Prototype Consistency Learning (MPCL) framework, which includes a Mean Teacher and an auxiliary network. The Mean Teacher generates prototypes for labeled and unlabeled data, while the auxiliary network produces additional prototypes for mixed data processed by CutMix. Through prototype fusion, mixed prototypes provide extra semantic information to both labeled and unlabeled prototypes. High-quality global prototypes for each class are formed by fusing two enhanced prototypes, optimizing the distribution of hidden embeddings used in consistency learning. Extensive experiments on the left atrium and type B aortic dissection datasets demonstrate MPCL's superiority over previous state-of-the-art approaches, confirming the effectiveness of our framework. The code will be released soon.
4/17/2024

Multi-level Asymmetric Contrastive Learning for Volumetric Medical Image Segmentation Pre-training
Shuang Zeng, Lei Zhu, Xinliang Zhang, Qian Chen, Hangzhou He, Lujia Jin, Zifeng Tian, Qiushi Ren, Zhaoheng Xie, Yanye Lu
0
0
Medical image segmentation is a fundamental yet challenging task due to the arduous process of acquiring large volumes of high-quality labeled data from experts. Contrastive learning offers a promising but still problematic solution to this dilemma. Because existing medical contrastive learning strategies focus on extracting image-level representation, which ignores abundant multi-level representations. And they underutilize the decoder either by random initialization or separate pre-training from the encoder, thereby neglecting the potential collaboration between the encoder and decoder. To address these issues, we propose a novel multi-level asymmetric contrastive learning framework named MACL for volumetric medical image segmentation pre-training. Specifically, we design an asymmetric contrastive learning structure to pre-train encoder and decoder simultaneously to provide better initialization for segmentation models. Moreover, we develop a multi-level contrastive learning strategy that integrates correspondences across feature-level, image-level, and pixel-level representations to ensure the encoder and decoder capture comprehensive details from representations of varying scales and granularities during the pre-training phase. Finally, experiments on 12 volumetric medical image datasets indicate our MACL framework outperforms existing 11 contrastive learning strategies. {itshape i.e.} Our MACL achieves a superior performance with more precise predictions from visualization figures and 2.28%, 1.32%, 1.62% and 1.60% Average Dice higher than previous best results on CHD, MMWHS, CHAOS and AMOS, respectively. And our MACL also has a strong generalization ability among 5 variant U-Net backbones. Our code will be available at https://github.com/stevezs315/MACL.
5/14/2024

ProbMCL: Simple Probabilistic Contrastive Learning for Multi-label Visual Classification
Ahmad Sajedi, Samir Khaki, Yuri A. Lawryshyn, Konstantinos N. Plataniotis
0
0
Multi-label image classification presents a challenging task in many domains, including computer vision and medical imaging. Recent advancements have introduced graph-based and transformer-based methods to improve performance and capture label dependencies. However, these methods often include complex modules that entail heavy computation and lack interpretability. In this paper, we propose Probabilistic Multi-label Contrastive Learning (ProbMCL), a novel framework to address these challenges in multi-label image classification tasks. Our simple yet effective approach employs supervised contrastive learning, in which samples that share enough labels with an anchor image based on a decision threshold are introduced as a positive set. This structure captures label dependencies by pulling positive pair embeddings together and pushing away negative samples that fall below the threshold. We enhance representation learning by incorporating a mixture density network into contrastive learning and generating Gaussian mixture distributions to explore the epistemic uncertainty of the feature encoder. We validate the effectiveness of our framework through experimentation with datasets from the computer vision and medical imaging domains. Our method outperforms the existing state-of-the-art methods while achieving a low computational footprint on both datasets. Visualization analyses also demonstrate that ProbMCL-learned classifiers maintain a meaningful semantic topology.
4/15/2024

A Point-Neighborhood Learning Framework for Nasal Endoscope Image Segmentation
Pengyu Jie, Wanquan Liu, Chenqiang Gao, Yihui Wen, Rui He, Pengcheng Li, Jintao Zhang, Deyu Meng
0
0
The lesion segmentation on endoscopic images is challenging due to its complex and ambiguous features. Fully-supervised deep learning segmentation methods can receive good performance based on entirely pixel-level labeled dataset but greatly increase experts' labeling burden. Semi-supervised and weakly supervised methods can ease labeling burden, but heavily strengthen the learning difficulty. To alleviate this difficulty, weakly semi-supervised segmentation adopts a new annotation protocol of adding a large number of point annotation samples into a few pixel-level annotation samples. However, existing methods only mine points' limited information while ignoring reliable prior surrounding the point annotations. In this paper, we propose a weakly semi-supervised method called Point-Neighborhood Learning (PNL) framework. To mine the prior of the pixels surrounding the annotated point, we transform a single-point annotation into a circular area named a point-neighborhood. We propose point-neighborhood supervision loss and pseudo-label scoring mechanism to enhance training supervision. Point-neighborhoods are also used to augment the data diversity. Our method greatly improves performance without changing the structure of segmentation network. Comprehensive experiments show the superiority of our method over the other existing methods, demonstrating its effectiveness in point-annotated medical images. The project code will be available on: https://github.com/ParryJay/PNL.
5/31/2024