Adaptive Preference Scaling for Reinforcement Learning with Human Feedback
2406.02764
0
0

Abstract
Reinforcement learning from human feedback (RLHF) is a prevalent approach to align AI systems with human values by learning rewards from human preference data. Due to various reasons, however, such data typically takes the form of rankings over pairs of trajectory segments, which fails to capture the varying strengths of preferences across different pairs. In this paper, we propose a novel adaptive preference loss, underpinned by distributionally robust optimization (DRO), designed to address this uncertainty in preference strength. By incorporating an adaptive scaling parameter into the loss for each pair, our method increases the flexibility of the reward function. Specifically, it assigns small scaling parameters to pairs with ambiguous preferences, leading to more comparable rewards, and large scaling parameters to those with clear preferences for more distinct rewards. Computationally, our proposed loss function is strictly convex and univariate with respect to each scaling parameter, enabling its efficient optimization through a simple second-order algorithm. Our method is versatile and can be readily adapted to various preference optimization frameworks, including direct preference optimization (DPO). Our experiments with robotic control and natural language generation with large language models (LLMs) show that our method not only improves policy performance but also aligns reward function selection more closely with policy optimization, simplifying the hyperparameter tuning process.
Create account to get full access
Overview
- This paper proposes a new approach called Adaptive Preference Scaling (APS) for reinforcement learning with human feedback.
- The key idea is to adaptively adjust the scale of human preferences to better align with the agent's learning process.
- The authors demonstrate that APS can improve the sample efficiency and performance of reinforcement learning agents compared to existing preference-based methods.
Plain English Explanation
The paper focuses on a problem called reinforcement learning with human feedback. In this setup, a machine learning agent is trying to learn how to perform a task by getting feedback from a human. The feedback could be in the form of ratings or rankings that express the human's preferences for different actions the agent takes.
One challenge with this approach is that human preferences can be subjective and may not always map cleanly to the agent's learning objectives. The Adaptive Preference Scaling method proposed in this paper tries to address this by dynamically adjusting the scale of the human feedback to better match the agent's internal understanding.
For example, imagine a human is teaching a robot how to clean a room. The human might say "I really prefer when you fold the towels neatly" on a scale of 1-10. But the robot may not have a good sense of what a "10" means in terms of neatness. By adaptively scaling the human feedback, the robot can better calibrate its actions to match the human's ideal.
The authors show through experiments that this adaptive scaling can lead to more efficient and effective reinforcement learning compared to previous preference-based methods that don't adjust the scale. This could have important applications in areas like interactive AI systems that learn from human users.
Technical Explanation
The key technical contribution of this paper is the Adaptive Preference Scaling (APS) algorithm. APS works by maintaining a calibration model that maps the human's preferences onto the agent's internal reward signal. This calibration model is updated iteratively as the agent interacts with the human and learns about their preferences.
Specifically, the agent will observe the human's preferences for different states or actions, and then use these preferences to update its own reward function. However, rather than directly using the human's raw preferences, the agent will first pass them through the calibration model to adjust the scale. This allows the agent to better align the human feedback with its own internal learning objectives.
The authors demonstrate the effectiveness of APS through experiments on several benchmark reinforcement learning tasks. They compare APS to prior preference-based methods like Contrastive Preference Learning and Iterative Preference Learning, and show that APS achieves higher sample efficiency and performance.
Critical Analysis
One potential limitation of the APS approach is that it assumes the human's preferences can be adequately captured by a simple calibration model. In reality, human preferences may be more complex, noisy, or context-dependent. The paper does not explore how APS would perform in settings with more heterogeneous or diverse human preferences.
Additionally, the experiments in the paper are relatively narrow in scope, focusing on simulated environments and simple tasks. It would be valuable to see how APS scales to more realistic, open-ended interactive AI systems where the complexity of human feedback is higher.
Overall, the APS approach represents a promising step towards more effective and efficient reinforcement learning from human preferences. However, further research is needed to fully understand its limitations and potential for real-world applications.
Conclusion
This paper introduces a new method called Adaptive Preference Scaling (APS) for reinforcement learning agents to better leverage human feedback. By dynamically adjusting the scale of the human's preferences, APS can improve the sample efficiency and performance of the learning process compared to previous preference-based approaches.
The key innovation of APS is the use of a calibration model that maps the human's preferences onto the agent's internal reward function. This allows the agent to better align the human feedback with its own learning objectives, overcoming challenges around the subjectivity and scale of human preferences.
The experimental results in the paper demonstrate the potential of APS, but also highlight areas for future research to expand its applicability to more complex, real-world scenarios involving diverse human preferences and interactive AI systems. Overall, this work represents an important step forward in the field of reinforcement learning with human feedback.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
Contrastive Preference Learning: Learning from Human Feedback without RL
Joey Hejna, Rafael Rafailov, Harshit Sikchi, Chelsea Finn, Scott Niekum, W. Bradley Knox, Dorsa Sadigh
0
0
Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for aligning models with human intent. Typically RLHF algorithms operate in two phases: first, use human preferences to learn a reward function and second, align the model by optimizing the learned reward via reinforcement learning (RL). This paradigm assumes that human preferences are distributed according to reward, but recent work suggests that they instead follow the regret under the user's optimal policy. Thus, learning a reward function from feedback is not only based on a flawed assumption of human preference, but also leads to unwieldy optimization challenges that stem from policy gradients or bootstrapping in the RL phase. Because of these optimization challenges, contemporary RLHF methods restrict themselves to contextual bandit settings (e.g., as in large language models) or limit observation dimensionality (e.g., state-based robotics). We overcome these limitations by introducing a new family of algorithms for optimizing behavior from human feedback using the regret-based model of human preferences. Using the principle of maximum entropy, we derive Contrastive Preference Learning (CPL), an algorithm for learning optimal policies from preferences without learning reward functions, circumventing the need for RL. CPL is fully off-policy, uses only a simple contrastive objective, and can be applied to arbitrary MDPs. This enables CPL to elegantly scale to high-dimensional and sequential RLHF problems while being simpler than prior methods.
5/1/2024
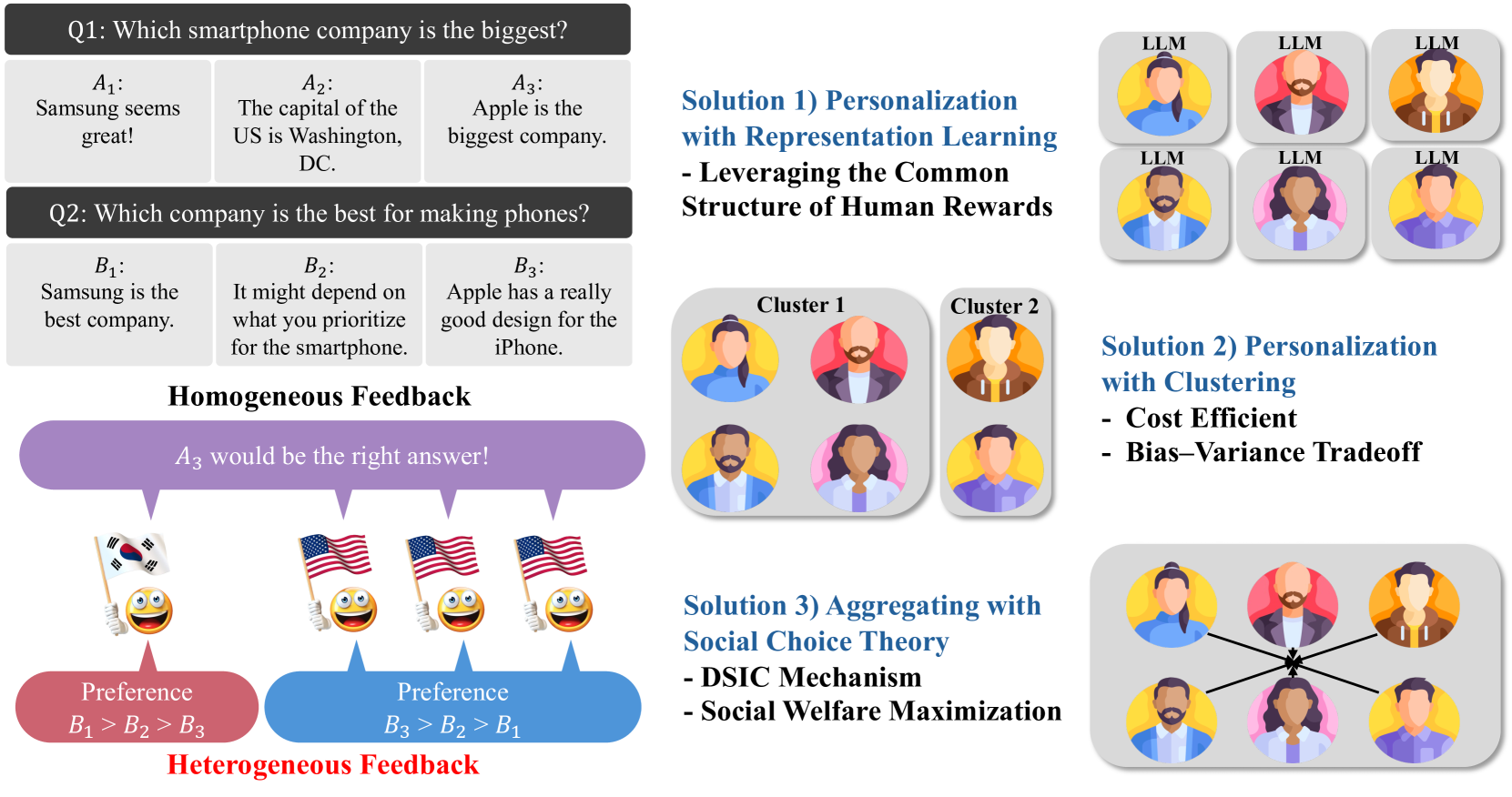
Principled RLHF from Heterogeneous Feedback via Personalization and Preference Aggregation
Chanwoo Park, Mingyang Liu, Dingwen Kong, Kaiqing Zhang, Asuman Ozdaglar
0
0
Reinforcement learning from human feedback (RLHF) has been an effective technique for aligning AI systems with human values, with remarkable successes in fine-tuning large-language models recently. Most existing RLHF paradigms make the underlying assumption that human preferences are relatively homogeneous, and can be encoded by a single reward model. In this paper, we focus on addressing the issues due to the inherent heterogeneity in human preferences, as well as their potential strategic behavior in providing feedback. Specifically, we propose two frameworks to address heterogeneous human feedback in principled ways: personalization-based one and aggregation-based one. For the former, we propose two approaches based on representation learning and clustering, respectively, for learning multiple reward models that trades off the bias (due to preference heterogeneity) and variance (due to the use of fewer data for learning each model by personalization). We then establish sample complexity guarantees for both approaches. For the latter, we aim to adhere to the single-model framework, as already deployed in the current RLHF paradigm, by carefully aggregating diverse and truthful preferences from humans. We propose two approaches based on reward and preference aggregation, respectively: the former utilizes both utilitarianism and Leximin approaches to aggregate individual reward models, with sample complexity guarantees; the latter directly aggregates the human feedback in the form of probabilistic opinions. Under the probabilistic-opinion-feedback model, we also develop an approach to handle strategic human labelers who may bias and manipulate the aggregated preferences with untruthful feedback. Based on the ideas in mechanism design, our approach ensures truthful preference reporting, with the induced aggregation rule maximizing social welfare functions.
5/28/2024
🏅
Multi-turn Reinforcement Learning from Preference Human Feedback
Lior Shani, Aviv Rosenberg, Asaf Cassel, Oran Lang, Daniele Calandriello, Avital Zipori, Hila Noga, Orgad Keller, Bilal Piot, Idan Szpektor, Avinatan Hassidim, Yossi Matias, R'emi Munos
0
0
Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
5/24/2024
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024