Advanced deep-reinforcement-learning methods for flow control: group-invariant and positional-encoding networks improve learning speed and quality

0
👁️
Sign in to get full access
Overview
- Deep reinforcement learning (DRL) can address challenges in traditional flow control methods for non-linear, high-dimensional energy systems.
- This study integrates group-invariant networks and positional encoding into DRL architectures to improve flow control.
- Multi-agent reinforcement learning (MARL) is used to exploit policy invariance in space, combined with group-invariant networks for local symmetry invariance.
- Positional encoding provides location information to agents, mitigating strict invariance constraints.
- The proposed methods are validated on a Rayleigh-Bénard convection case study, aiming to minimize the Nusselt number.
Plain English Explanation
Controlling the flow of fluids, gases, or energy is crucial for maximizing efficiency in a wide range of applications. Traditional flow control methods can struggle with complex, nonlinear systems and large amounts of data. This makes them less useful for real-world energy systems.
This study explores using deep reinforcement learning (DRL) to improve flow control. DRL is a type of machine learning that allows systems to learn how to make decisions by interacting with their environment.
The researchers integrated two key techniques into their DRL approach:
- Group-invariant neural networks (GI-NNs): These networks are designed to be invariant to certain spatial transformations, allowing them to learn more efficiently.
- Positional encoding: This adds information about the location of the agents in the system, helping them overcome limitations from strict spatial invariance.
By combining these techniques with multi-agent reinforcement learning (MARL), the researchers were able to create a DRL system that could more effectively control the flow in a complex, real-world scenario - specifically, Rayleigh-Bénard convection, where the goal is to minimize a key measurement called the Nusselt number.
The results showed that the GI-NNs led to faster learning and better overall performance compared to a standard MARL approach. Adding positional encoding further improved the results, reducing the Nusselt number and stabilizing the learning process.
These findings suggest that choosing the right feature representation method, based on the specific characteristics of the control problem, is crucial for developing effective DRL-based flow control systems. The researchers believe their work could inspire new DRL methods with more invariant and meaningful representations, ultimately leading to better industrial applications.
Technical Explanation
This study advances the use of deep reinforcement learning (DRL) for flow control, a critical task in improving energy efficiency across many applications. Traditional flow control methods struggle with non-linear systems and high-dimensional data, limiting their real-world applicability.
To address these challenges, the researchers integrated two key techniques into their DRL architecture:
- Group-invariant neural networks (GI-NNs): These networks are designed to be invariant to certain spatial transformations, allowing them to learn more efficiently by exploiting the inherent symmetries in the problem.
- Positional encoding: Inspired by the transformer architecture, this adds location information to the agents, mitigating the limitations of strict spatial invariance.
The researchers used multi-agent reinforcement learning (MARL) to leverage policy invariance in space, combining it with the group-invariant networks to ensure local symmetry invariance.
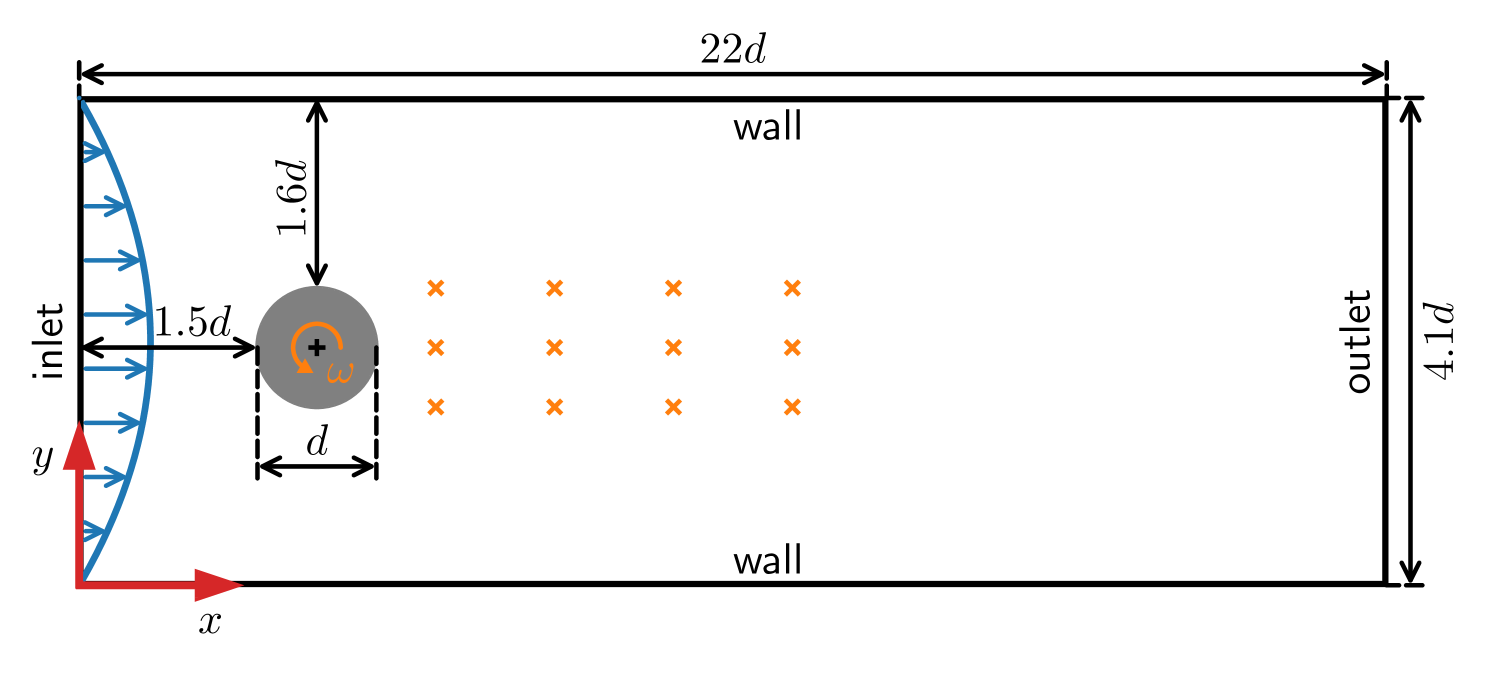
The proposed methods were validated on a case study of Rayleigh-Bénard convection, where the goal was to minimize the Nusselt number (Nu), a key metric of heat transfer.
The results showed that the GI-NNs achieved faster convergence and better average policy performance compared to the base MARL approach. Notably, the GI-NNs cut the DRL training time in half and improved learning reproducibility.
Incorporating positional encoding further enhanced these results, effectively reducing the minimum Nu and stabilizing the convergence. Interestingly, the researchers found that group-invariant networks excel at improving learning speed, while positional encoding specializes in improving learning quality.
These findings demonstrate the importance of carefully selecting the appropriate feature representation method based on the characteristics of the control problem at hand. The researchers believe their work will inspire the development of novel DRL methods with more invariant and meaningful representations, ultimately leading to better industrial applications.
Critical Analysis
The study presents a compelling approach to enhancing DRL-based flow control by leveraging group-invariant networks and positional encoding. The researchers provide a robust validation of their methods using the challenging Rayleigh-Bénard convection case study, demonstrating significant improvements in learning speed, policy performance, and reproducibility.
One potential limitation of the study is the focus on a single, specific case study. While the Rayleigh-Bénard convection problem is a well-established benchmark, it would be valuable to see the proposed techniques applied to a wider range of flow control scenarios, including real-world industrial applications, to further validate their generalizability.
Additionally, the paper does not delve into the computational complexity or resource requirements of the GI-NN and positional encoding approaches. Understanding the tradeoffs between the performance gains and the increased model complexity or training time would be useful for practitioners considering the adoption of these techniques.
Another area for further exploration could be the sensitivity of the proposed methods to the specific hyperparameter settings and architectural choices. Investigating the robustness of the techniques to these design decisions, and potentially exploring automated hyperparameter tuning or architecture search, could help make the approach more accessible and broadly applicable.
Despite these potential areas for further research, the study presents a significant step forward in the application of DRL to flow control problems, offering valuable insights into the importance of feature representation and the strategic combination of different techniques to enhance learning and performance.
Conclusion
This study demonstrates the power of integrating group-invariant neural networks and positional encoding into deep reinforcement learning architectures for flow control applications. By leveraging the inherent symmetries in the problem and providing location-aware representations to the agents, the researchers were able to achieve substantial improvements in learning speed, policy performance, and convergence stability compared to standard MARL approaches.
The results of this work not only inspire the development of novel DRL methods with more invariant and meaningful representations but also provide valuable guidance for practitioners seeking to apply these techniques to real-world industrial challenges. As the demand for energy-efficient systems continues to grow, the insights gained from this study could play a crucial role in unlocking the full potential of DRL-based flow control, ultimately contributing to a more sustainable and efficient energy landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Advanced deep-reinforcement-learning methods for flow control: group-invariant and positional-encoding networks improve learning speed and quality
Joogoo Jeon, Jean Rabault, Joel Vasanth, Francisco Alc'antara-'Avila, Shilaj Baral, Ricardo Vinuesa
Flow control is key to maximize energy efficiency in a wide range of applications. However, traditional flow-control methods face significant challenges in addressing non-linear systems and high-dimensional data, limiting their application in realistic energy systems. This study advances deep-reinforcement-learning (DRL) methods for flow control, particularly focusing on integrating group-invariant networks and positional encoding into DRL architectures. Our methods leverage multi-agent reinforcement learning (MARL) to exploit policy invariance in space, in combination with group-invariant networks to ensure local symmetry invariance. Additionally, a positional encoding inspired by the transformer architecture is incorporated to provide location information to the agents, mitigating action constraints from strict invariance. The proposed methods are verified using a case study of Rayleigh-B'enard convection, where the goal is to minimize the Nusselt number Nu. The group-invariant neural networks (GI-NNs) show faster convergence compared to the base MARL, achieving better average policy performance. The GI-NNs not only cut DRL training time in half but also notably enhance learning reproducibility. Positional encoding further enhances these results, effectively reducing the minimum Nu and stabilizing convergence. Interestingly, group invariant networks specialize in improving learning speed and positional encoding specializes in improving learning quality. These results demonstrate that choosing a suitable feature-representation method according to the purpose as well as the characteristics of each control problem is essential. We believe that the results of this study will not only inspire novel DRL methods with invariant and unique representations, but also provide useful insights for industrial applications.
Read more7/26/2024
0
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner, Janis Geise
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
Read more4/11/2024

0
Model-Based Reinforcement Learning for Control of Strongly-Disturbed Unsteady Aerodynamic Flows
Zhecheng Liu (University of California, Los Angeles), Diederik Beckers (California Institute of Technology), Jeff D. Eldredge (University of California, Los Angeles)
The intrinsic high dimension of fluid dynamics is an inherent challenge to control of aerodynamic flows, and this is further complicated by a flow's nonlinear response to strong disturbances. Deep reinforcement learning, which takes advantage of the exploratory aspects of reinforcement learning (RL) and the rich nonlinearity of a deep neural network, provides a promising approach to discover feasible control strategies. However, the typical model-free approach to reinforcement learning requires a significant amount of interaction between the flow environment and the RL agent during training, and this high training cost impedes its development and application. In this work, we propose a model-based reinforcement learning (MBRL) approach by incorporating a novel reduced-order model as a surrogate for the full environment. The model consists of a physics-augmented autoencoder, which compresses high-dimensional CFD flow field snaphsots into a three-dimensional latent space, and a latent dynamics model that is trained to accurately predict the long-time dynamics of trajectories in the latent space in response to action sequences. The robustness and generalizability of the model is demonstrated in two distinct flow environments, a pitching airfoil in a highly disturbed environment and a vertical-axis wind turbine in a disturbance-free environment. Based on the trained model in the first problem, we realize an MBRL strategy to mitigate lift variation during gust-airfoil encounters. We demonstrate that the policy learned in the reduced-order environment translates to an effective control strategy in the full CFD environment.
Read more8/28/2024
🤿
0
Closed-form congestion control via deep symbolic regression
Jean Martins, Igor Almeida, Ricardo Souza, Silvia Lins
As mobile networks embrace the 5G era, the interest in adopting Reinforcement Learning (RL) algorithms to handle challenges in ultra-low-latency and high throughput scenarios increases. Simultaneously, the advent of packetized fronthaul networks imposes demanding requirements that traditional congestion control mechanisms cannot accomplish, highlighting the potential of RL-based congestion control algorithms. Although learning RL policies optimized for satisfying the stringent fronthaul requirements is feasible, the adoption of neural network models in real deployments still poses some challenges regarding real-time inference and interpretability. This paper proposes a methodology to deal with such challenges while maintaining the performance and generalization capabilities provided by a baseline RL policy. The method consists of (1) training a congestion control policy specialized in fronthaul-like networks via reinforcement learning, (2) collecting state-action experiences from the baseline, and (3) performing deep symbolic regression on the collected dataset. The proposed process overcomes the challenges related to inference-time limitations through closed-form expressions that approximate the baseline performance (link utilization, delay, and fairness) and which can be directly implemented in any programming language. Finally, we analyze the inner workings of the closed-form expressions.
Read more5/3/2024