Model-based deep reinforcement learning for accelerated learning from flow simulations
2402.16543
0
0
Abstract
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of model-based deep reinforcement learning to accelerate learning from flow simulations.
- The approach combines a learned dynamics model with a reinforcement learning agent to efficiently explore and learn optimal control policies.
- The research aims to enable faster training of simulation-based control systems compared to traditional reinforcement learning methods.
Plain English Explanation
In this research, the authors investigate a new way to train control systems using computer simulations. Traditional reinforcement learning approaches can be slow and inefficient when learning directly from simulations. The researchers propose a model-based reinforcement learning approach that first learns a dynamics model of the simulation. This allows the reinforcement learning agent to plan and explore more efficiently, speeding up the overall training process.
The key idea is to combine a learned dynamics model with a reinforcement learning agent. The dynamics model acts as a proxy for the actual simulation, allowing the agent to rapidly try out different actions and strategies without the overhead of running the full simulation. This simulation-based reinforcement learning approach aims to enable faster training of control policies compared to traditional methods that learn directly from the simulation.
The researchers demonstrate their approach on several fluid dynamics simulation tasks, showing that it can significantly accelerate learning compared to standard reinforcement learning. This has important implications for applications that rely on simulations, such as robotics, autonomous vehicles, and other complex control problems.
Technical Explanation
The paper presents a model-based deep reinforcement learning approach to accelerate learning from flow simulations. The key components are:
-
Learned Dynamics Model: The researchers train a neural network model to learn the underlying dynamics of the flow simulation. This allows the model to predict the future state of the system given the current state and actions.
-
Reinforcement Learning Agent: A reinforcement learning agent is trained to learn an optimal control policy by interacting with the learned dynamics model, rather than the full simulation. This allows the agent to rapidly explore different strategies without the computational overhead of running the complete simulation.
-
Training Procedure: The dynamics model and reinforcement learning agent are trained in an iterative process. The dynamics model is first trained on data from the simulation. Then, the reinforcement learning agent is trained using the learned dynamics model as a proxy for the real simulation. The updated agent is then used to collect more data to further refine the dynamics model.
The researchers evaluate their approach on several fluid dynamics simulation tasks, including controlling the flow around a bluff body and optimizing the shape of an airfoil. They show that their model-based reinforcement learning method can significantly accelerate learning compared to standard reinforcement learning approaches that interact directly with the simulation.
Critical Analysis
The paper presents a promising approach for accelerating the training of simulation-based control systems using model-based reinforcement learning. However, there are a few potential limitations and areas for further research:
-
Accuracy of the Dynamics Model: The effectiveness of the approach relies on the accuracy of the learned dynamics model. If the model fails to capture important aspects of the underlying simulation, it could lead to sub-optimal or even incorrect policies being learned by the reinforcement learning agent.
-
Generalization to Real-World Systems: While the approach is demonstrated on fluid dynamics simulations, it remains to be seen how well the learned policies would transfer to real-world systems. There may be discrepancies between the simulation and the physical world that could impact the performance of the learned controllers.
-
Scalability to More Complex Simulations: The experiments in the paper focus on relatively simple flow simulations. Scaling the approach to more complex, high-dimensional simulations may present additional challenges in terms of model learning and reinforcement learning performance.
-
Interpretability of the Learned Policies: As with many deep learning-based approaches, the learned control policies may be difficult to interpret and understand, which could limit their adoption in safety-critical applications.
Despite these potential limitations, the research presented in this paper represents an important step forward in the field of model-based reinforcement learning and its applications to simulation-based control problems. Further advancements in this area could have significant implications for a wide range of industries and applications.
Conclusion
This paper introduces a novel model-based deep reinforcement learning approach to accelerate learning from flow simulations. By combining a learned dynamics model with a reinforcement learning agent, the researchers demonstrate that they can significantly improve the efficiency of training simulation-based control policies compared to traditional reinforcement learning methods.
The implications of this work are particularly relevant for applications that rely on complex simulations, such as robotics, autonomous vehicles, and aerospace engineering. By enabling faster training of simulation-based control systems, this approach has the potential to drive innovation and unlock new capabilities in these domains.
While the paper highlights some potential limitations, the overall research represents an important contribution to the field of model-based reinforcement learning and its applications to real-world problems. As the field continues to evolve, further advancements in this area could lead to transformative breakthroughs in how we design and optimize complex, simulation-driven systems.
Related Papers
📈
Model predictive control-based value estimation for efficient reinforcement learning
Qizhen Wu, Kexin Liu, Lei Chen
0
0
Reinforcement learning suffers from limitations in real practices primarily due to the number of required interactions with virtual environments. It results in a challenging problem because we are implausible to obtain a local optimal strategy with only a few attempts for many learning methods. Hereby, we design an improved reinforcement learning method based on model predictive control that models the environment through a data-driven approach. Based on the learned environment model, it performs multi-step prediction to estimate the value function and optimize the policy. The method demonstrates higher learning efficiency, faster convergent speed of strategies tending to the local optimal value, and less sample capacity space required by experience replay buffers. Experimental results, both in classic databases and in a dynamic obstacle avoidance scenario for an unmanned aerial vehicle, validate the proposed approaches.
4/12/2024
🤿
Closed-form congestion control via deep symbolic regression
Jean Martins, Igor Almeida, Ricardo Souza, Silvia Lins
0
0
As mobile networks embrace the 5G era, the interest in adopting Reinforcement Learning (RL) algorithms to handle challenges in ultra-low-latency and high throughput scenarios increases. Simultaneously, the advent of packetized fronthaul networks imposes demanding requirements that traditional congestion control mechanisms cannot accomplish, highlighting the potential of RL-based congestion control algorithms. Although learning RL policies optimized for satisfying the stringent fronthaul requirements is feasible, the adoption of neural network models in real deployments still poses some challenges regarding real-time inference and interpretability. This paper proposes a methodology to deal with such challenges while maintaining the performance and generalization capabilities provided by a baseline RL policy. The method consists of (1) training a congestion control policy specialized in fronthaul-like networks via reinforcement learning, (2) collecting state-action experiences from the baseline, and (3) performing deep symbolic regression on the collected dataset. The proposed process overcomes the challenges related to inference-time limitations through closed-form expressions that approximate the baseline performance (link utilization, delay, and fairness) and which can be directly implemented in any programming language. Finally, we analyze the inner workings of the closed-form expressions.
5/3/2024
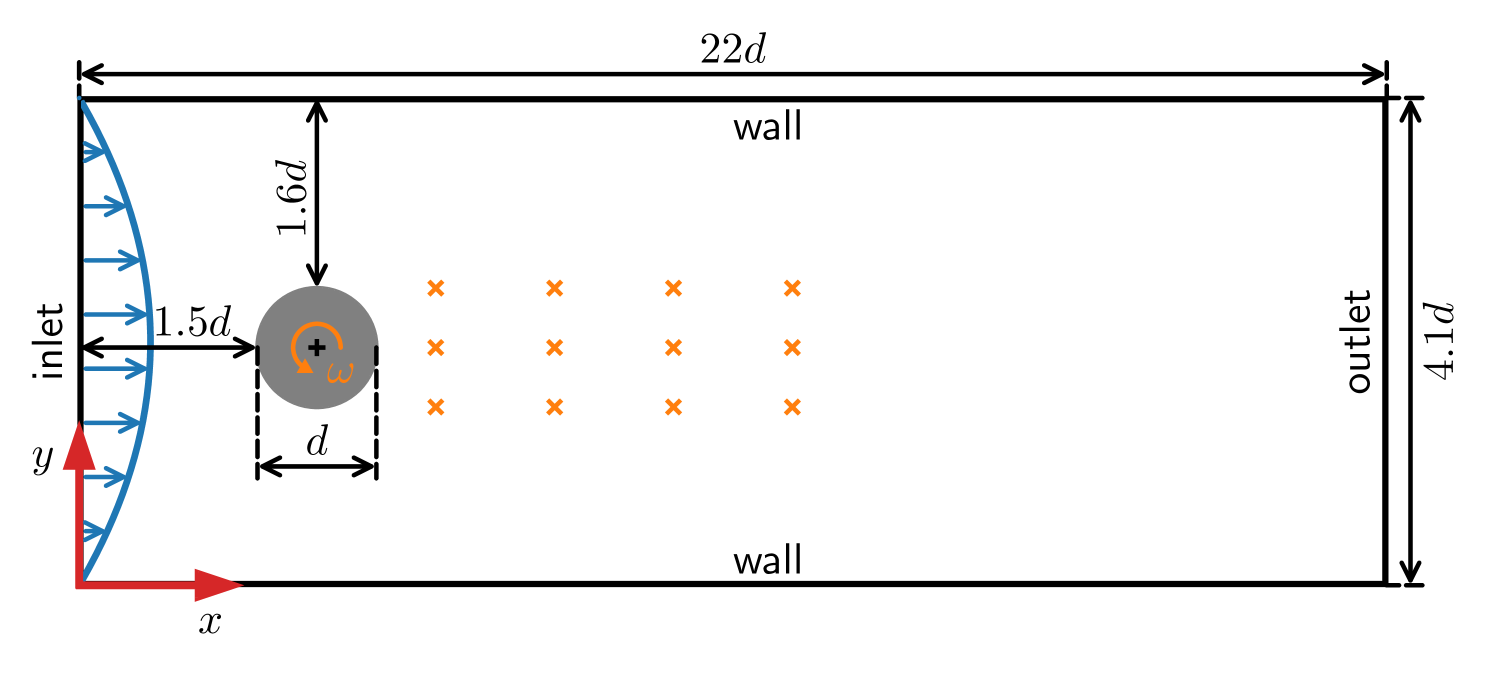
Autonomous vehicle decision and control through reinforcement learning with traffic flow randomization
Yuan Lin, Antai Xie, Xiao Liu
0
0
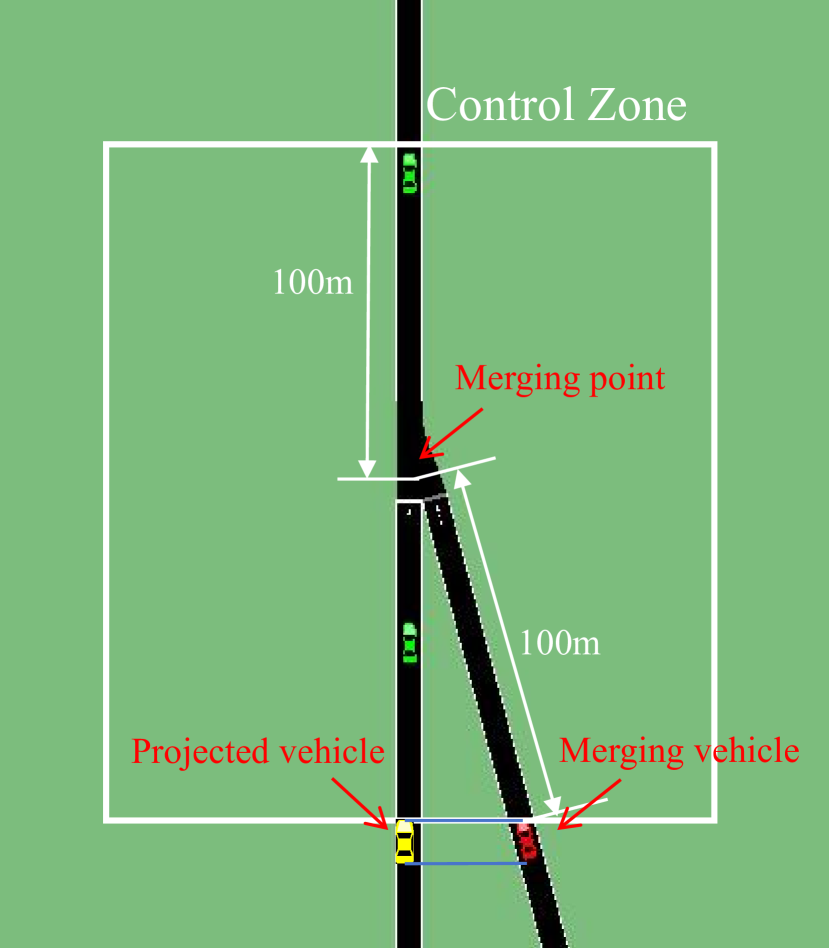
Most of the current studies on autonomous vehicle decision-making and control tasks based on reinforcement learning are conducted in simulated environments. The training and testing of these studies are carried out under rule-based microscopic traffic flow, with little consideration of migrating them to real or near-real environments to test their performance. It may lead to a degradation in performance when the trained model is tested in more realistic traffic scenes. In this study, we propose a method to randomize the driving style and behavior of surrounding vehicles by randomizing certain parameters of the car-following model and the lane-changing model of rule-based microscopic traffic flow in SUMO. We trained policies with deep reinforcement learning algorithms under the domain randomized rule-based microscopic traffic flow in freeway and merging scenes, and then tested them separately in rule-based microscopic traffic flow and high-fidelity microscopic traffic flow. Results indicate that the policy trained under domain randomization traffic flow has significantly better success rate and calculative reward compared to the models trained under other microscopic traffic flows.
4/22/2024
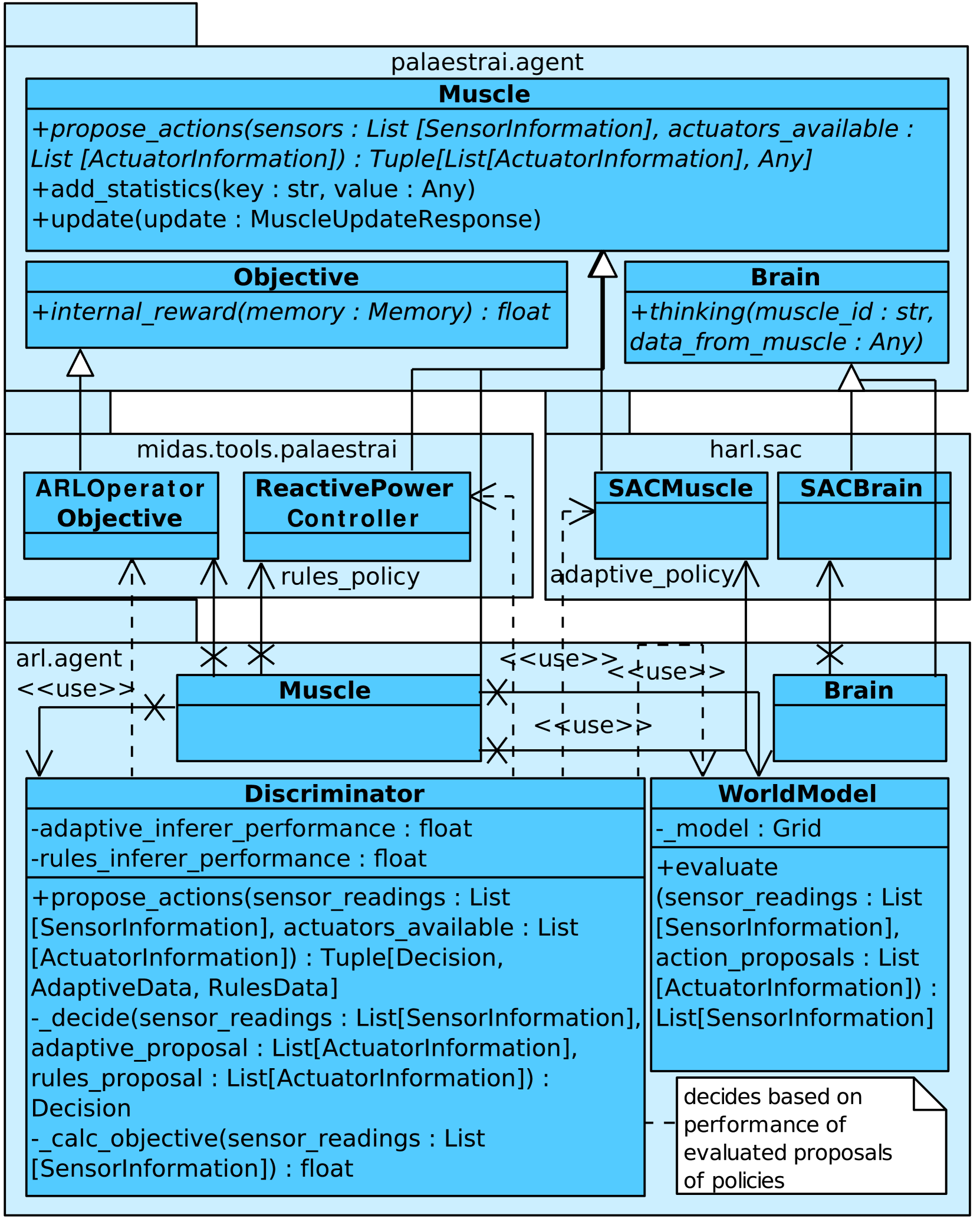
Imitation Game: A Model-based and Imitation Learning Deep Reinforcement Learning Hybrid
Eric MSP Veith, Torben Logemann, Aleksandr Berezin, Arlena Well{ss}ow, Stephan Balduin
0
0
Autonomous and learning systems based on Deep Reinforcement Learning have firmly established themselves as a foundation for approaches to creating resilient and efficient Cyber-Physical Energy Systems. However, most current approaches suffer from two distinct problems: Modern model-free algorithms such as Soft Actor Critic need a high number of samples to learn a meaningful policy, as well as a fallback to ward against concept drifts (e. g., catastrophic forgetting). In this paper, we present the work in progress towards a hybrid agent architecture that combines model-based Deep Reinforcement Learning with imitation learning to overcome both problems.
4/3/2024