Advancing Audio Fingerprinting Accuracy Addressing Background Noise and Distortion Challenges

0
🎯
Sign in to get full access
Overview
- Audio fingerprinting, pioneered by apps like Shazam, has transformed digital audio recognition.
- Existing systems struggle with accuracy in challenging conditions, limiting their broader applications.
- This research proposes an AI and machine learning-integrated audio fingerprinting algorithm to enhance accuracy.
- The study emphasizes real-world scenario simulations with diverse background noises and distortions.
Plain English Explanation
Audio fingerprinting is a technology that allows digital devices to identify songs or other audio content by analyzing their unique sonic "fingerprints." This has enabled applications like Shazam, where you can hold up your phone to a song and it will tell you the name and artist.
However, current audio fingerprinting systems often struggle to maintain accuracy when faced with background noise, distortions, or other real-world challenges. This limits their usefulness in many practical scenarios.
This research aimed to develop a more robust and adaptive audio fingerprinting algorithm by integrating advanced AI and machine learning techniques. Building on the foundation of the Dejavu Project, the researchers focused on simulating diverse real-world conditions with noise and distortions to test the system's performance.
The core of the algorithm involves signal processing techniques like the Fast Fourier Transform, spectrograms, and peak extraction to analyze the audio and generate unique "fingerprints." These fingerprints are then hashed and matched against a database to identify the song.
The researchers found that this approach achieved 100% accuracy in identifying songs from just 5 seconds of audio input, while also maintaining efficient and predictable matching speeds. This demonstrates the potential for more adaptable and reliable audio fingerprinting in a wide range of applications.
Technical Explanation
The researchers built their audio fingerprinting algorithm on the foundations of the Dejavu Project, which utilizes signal processing techniques like the Fast Fourier Transform, spectrograms, and peak extraction to analyze audio content.
The core innovation lies in the integration of advanced AI and machine learning components to enhance the accuracy and robustness of the system. The researchers placed a strong emphasis on simulating diverse real-world scenarios, including various background noises and distortions, to test the algorithm's performance.
The audio fingerprinting process involves several key steps:
- Signal processing to extract relevant features from the audio, including frequency domain analysis and spectrogram generation.
- Identification of unique "peaks" in the spectrogram, which serve as the basis for the audio fingerprint.
- Hashing and storage of the fingerprint data to enable efficient matching against a database of known songs.
- Matching the input audio fingerprint against the database to identify the corresponding song.
The researchers' evaluation of this system demonstrated 100% accuracy in song identification from just 5 seconds of audio input, with a matching speed that remained predictable and efficient. This represents a significant advancement in the state-of-the-art for audio fingerprinting, addressing key challenges around accuracy and adaptability in real-world scenarios.
Critical Analysis
The research presented in this paper represents a promising step forward in enhancing the accuracy and robustness of audio fingerprinting systems. By integrating advanced AI and machine learning techniques, the researchers have demonstrated the potential to overcome the limitations of existing approaches, which often struggle with background noise, distortions, and other real-world challenges.
However, it's important to note that the paper focuses primarily on the technical aspects of the algorithm and its performance evaluation. While the results are impressive, the researchers do not delve deeply into the potential limitations or areas for further research.
For example, the paper does not address the scalability of the system in terms of handling large-scale audio databases or the potential for false positives or false negatives in real-world deployment scenarios. Additionally, the researchers do not explore the computational and storage requirements of the algorithm, which could be an important consideration for practical implementation.
Further research may be needed to explore the generalization capabilities of this approach and its applicability across a wider range of audio recognition tasks, beyond just song identification. The integration of this technology with other audio processing and biometric applications could also be an area of interest for future investigations.
Conclusion
This research represents a significant advancement in the field of audio fingerprinting, addressing key challenges around accuracy and robustness in real-world scenarios. By integrating AI and machine learning techniques, the proposed algorithm has demonstrated impressive performance, achieving 100% accuracy in song identification from just 5 seconds of audio input.
The potential implications of this technology are wide-ranging, spanning applications in music recognition, audio forensics, and even biometric identification. As the researchers continue to refine and expand the system, it could pave the way for more reliable and adaptable audio recognition solutions that can thrive in diverse, challenging environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
Advancing Audio Fingerprinting Accuracy Addressing Background Noise and Distortion Challenges
Navin Kamuni, Sathishkumar Chintala, Naveen Kunchakuri, Jyothi Swaroop Arlagadda Narasimharaju, Venkat Kumar
Audio fingerprinting, exemplified by pioneers like Shazam, has transformed digital audio recognition. However, existing systems struggle with accuracy in challenging conditions, limiting broad applicability. This research proposes an AI and ML integrated audio fingerprinting algorithm to enhance accuracy. Built on the Dejavu Project's foundations, the study emphasizes real-world scenario simulations with diverse background noises and distortions. Signal processing, central to Dejavu's model, includes the Fast Fourier Transform, spectrograms, and peak extraction. The constellation concept and fingerprint hashing enable unique song identification. Performance evaluation attests to 100% accuracy within a 5-second audio input, with a system showcasing predictable matching speed for efficiency. Storage analysis highlights the critical space-speed trade-off for practical implementation. This research advances audio fingerprinting's adaptability, addressing challenges in varied environments and applications.
Read more6/4/2024
🌀
0
Audio Anti-Spoofing Detection: A Survey
Menglu Li, Yasaman Ahmadiadli, Xiao-Ping Zhang
The availability of smart devices leads to an exponential increase in multimedia content. However, the rapid advancements in deep learning have given rise to sophisticated algorithms capable of manipulating or creating multimedia fake content, known as Deepfake. Audio Deepfakes pose a significant threat by producing highly realistic voices, thus facilitating the spread of misinformation. To address this issue, numerous audio anti-spoofing detection challenges have been organized to foster the development of anti-spoofing countermeasures. This survey paper presents a comprehensive review of every component within the detection pipeline, including algorithm architectures, optimization techniques, application generalizability, evaluation metrics, performance comparisons, available datasets, and open-source availability. For each aspect, we conduct a systematic evaluation of the recent advancements, along with discussions on existing challenges. Additionally, we also explore emerging research topics on audio anti-spoofing, including partial spoofing detection, cross-dataset evaluation, and adversarial attack defence, while proposing some promising research directions for future work. This survey paper not only identifies the current state-of-the-art to establish strong baselines for future experiments but also guides future researchers on a clear path for understanding and enhancing the audio anti-spoofing detection mechanisms.
Read more4/23/2024
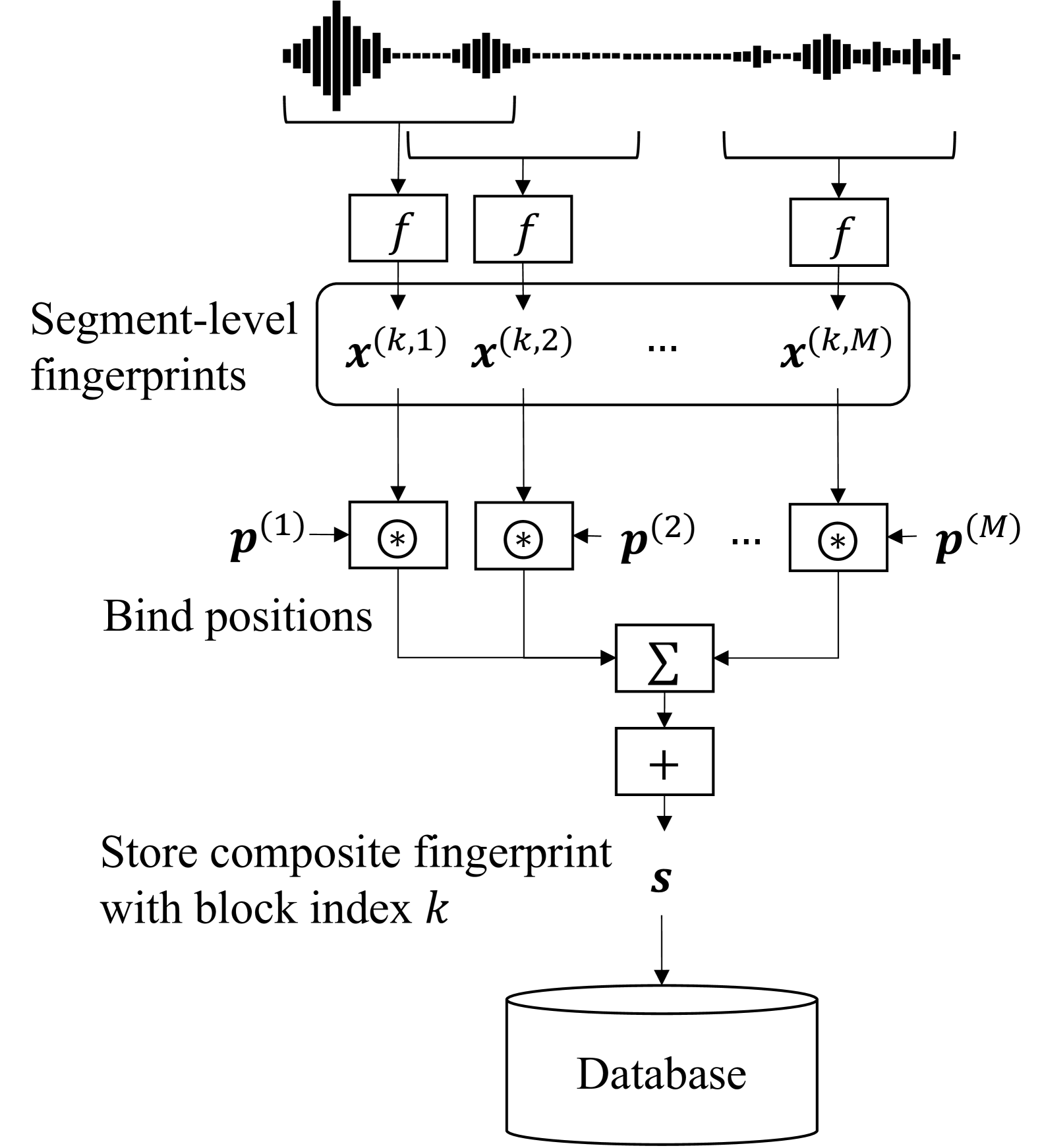
0
Audio Fingerprinting with Holographic Reduced Representations
Yusuke Fujita, Tatsuya Komatsu
This paper proposes an audio fingerprinting model with holographic reduced representation (HRR). The proposed method reduces the number of stored fingerprints, whereas conventional neural audio fingerprinting requires many fingerprints for each audio track to achieve high accuracy and time resolution. We utilize HRR to aggregate multiple fingerprints into a composite fingerprint via circular convolution and summation, resulting in fewer fingerprints with the same dimensional space as the original. Our search method efficiently finds a combined fingerprint in which a query fingerprint exists. Using HRR's inverse operation, it can recover the relative position within a combined fingerprint, retaining the original time resolution. Experiments show that our method can reduce the number of fingerprints with modest accuracy degradation while maintaining the time resolution, outperforming simple decimation and summation-based aggregation methods.
Read more6/21/2024

0
Advancing Ear Biometrics: Enhancing Accuracy and Robustness through Deep Learning
Youssef Mohamed, Zeyad Youssef, Ahmed Heakl, Ahmed Zaky
Biometric identification is a reliable method to verify individuals based on their unique physical or behavioral traits, offering a secure alternative to traditional methods like passwords or PINs. This study focuses on ear biometric identification, exploiting its distinctive features for enhanced accuracy, reliability, and usability. While past studies typically investigate face recognition and fingerprint analysis, our research demonstrates the effectiveness of ear biometrics in overcoming limitations such as variations in facial expressions and lighting conditions. We utilized two datasets: AMI (700 images from 100 individuals) and EarNV1.0 (28,412 images from 164 individuals). To improve the accuracy and robustness of our ear biometric identification system, we applied various techniques including data preprocessing and augmentation. Our models achieved a testing accuracy of 99.35% on the AMI Dataset and 98.1% on the EarNV1.0 dataset, showcasing the effectiveness of our approach in precisely identifying individuals based on ear biometric characteristics.
Read more6/4/2024