Audio Fingerprinting with Holographic Reduced Representations

0
Sign in to get full access
Overview
- This paper explores the use of holographic reduced representations (HRRs) for audio fingerprinting, which can help identify audio content even in the presence of background noise.
- The researchers propose a novel audio fingerprinting system that leverages HRRs to create compact, robust audio signatures.
- The system is evaluated on various datasets, including those with background noise, demonstrating improved accuracy compared to existing methods.
Plain English Explanation
Audio fingerprinting is a technique used to identify audio content, such as a song or speech recording, even when it's mixed with other sounds or altered in some way. The Advancing Audio Fingerprinting Accuracy by Addressing Background Noise paper showed how this can be challenging when there's a lot of background noise.
In this paper, the researchers explore using a special type of mathematical representation called Generalized Holographic Reduced Representations to create audio fingerprints that are more robust to noise. These fingerprints are compact, efficient data summaries that can uniquely identify audio content, even if it's buried in background sounds.
The researchers tested their approach on various datasets, including ones with a lot of background noise, and found that it outperformed existing audio fingerprinting methods in terms of accuracy. This means the system can more reliably identify audio content, even in noisy environments, which could be useful for applications like music recognition, speech processing, and security.
Technical Explanation
The paper proposes a novel audio fingerprinting system that leverages Holographic Reduced Representations (HRRs) to create compact, robust audio signatures. HRRs are a type of high-dimensional vector representation that can capture the relationships between audio features in a compact and noise-tolerant way.
The system first extracts a set of audio features from the input audio signal, such as spectral characteristics and temporal patterns. These features are then encoded into an HRR, which serves as the audio fingerprint. The researchers explore different techniques for constructing the HRR, including the use of Reverberant Room Impulse Responses (RevRIR) to model the acoustic environment.
The performance of the proposed system is evaluated on several audio fingerprinting datasets, including those with significant background noise. The results demonstrate that the HRR-based approach outperforms existing audio fingerprinting methods in terms of accuracy, particularly in noisy environments. The researchers also investigate the impact of different HRR construction techniques and parameters on the overall system performance.
Critical Analysis
The paper presents a promising approach to improving audio fingerprinting accuracy in the presence of background noise. The use of HRRs is a novel and well-motivated technique, as these representations have been shown to be robust to noise and distortion in other domains, such as 3D object recognition.
However, the paper does not discuss the potential limitations of the proposed system. For instance, it's unclear how the system would perform in the presence of more complex or dynamic background noise, such as multiple overlapping audio sources. Additionally, the paper does not address the computational complexity of the HRR construction process, which could be a practical concern for real-time applications.
Further research could explore the Distinguishing Neural Speech Synthesis Models Through Fingerprints approach to better understand the robustness of the HRR-based fingerprints against more sophisticated adversarial attacks or attempts to spoof the system.
Conclusion
This paper presents a novel audio fingerprinting system that leverages Holographic Reduced Representations (HRRs) to create compact, noise-tolerant audio signatures. The proposed approach demonstrates improved accuracy compared to existing methods, particularly in the presence of background noise, which is a common challenge in real-world audio processing applications.
The use of HRRs is a promising direction for improving the robustness of audio fingerprinting, and the techniques explored in this paper could have broader implications for other audio signal processing tasks, such as speech recognition, music information retrieval, and audio surveillance. Further research is needed to explore the limitations and practical considerations of the HRR-based approach, but this work represents an important step forward in enhancing the reliability and applicability of audio fingerprinting systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Audio Fingerprinting with Holographic Reduced Representations
Yusuke Fujita, Tatsuya Komatsu
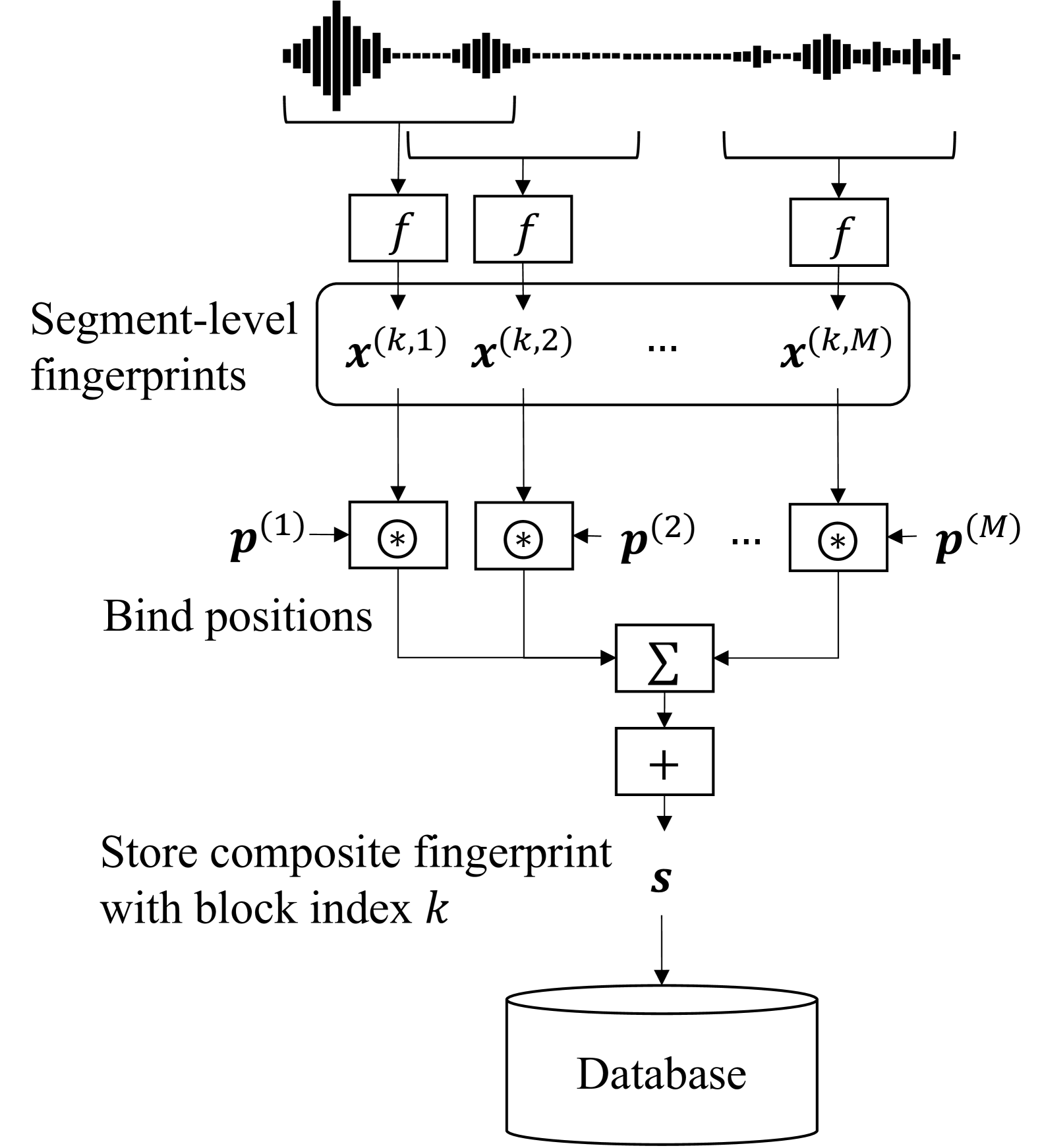
This paper proposes an audio fingerprinting model with holographic reduced representation (HRR). The proposed method reduces the number of stored fingerprints, whereas conventional neural audio fingerprinting requires many fingerprints for each audio track to achieve high accuracy and time resolution. We utilize HRR to aggregate multiple fingerprints into a composite fingerprint via circular convolution and summation, resulting in fewer fingerprints with the same dimensional space as the original. Our search method efficiently finds a combined fingerprint in which a query fingerprint exists. Using HRR's inverse operation, it can recover the relative position within a combined fingerprint, retaining the original time resolution. Experiments show that our method can reduce the number of fingerprints with modest accuracy degradation while maintaining the time resolution, outperforming simple decimation and summation-based aggregation methods.
Read more6/21/2024
🎯
0
Advancing Audio Fingerprinting Accuracy Addressing Background Noise and Distortion Challenges
Navin Kamuni, Sathishkumar Chintala, Naveen Kunchakuri, Jyothi Swaroop Arlagadda Narasimharaju, Venkat Kumar
Audio fingerprinting, exemplified by pioneers like Shazam, has transformed digital audio recognition. However, existing systems struggle with accuracy in challenging conditions, limiting broad applicability. This research proposes an AI and ML integrated audio fingerprinting algorithm to enhance accuracy. Built on the Dejavu Project's foundations, the study emphasizes real-world scenario simulations with diverse background noises and distortions. Signal processing, central to Dejavu's model, includes the Fast Fourier Transform, spectrograms, and peak extraction. The constellation concept and fingerprint hashing enable unique song identification. Performance evaluation attests to 100% accuracy within a 5-second audio input, with a system showcasing predictable matching speed for efficiency. Storage analysis highlights the critical space-speed trade-off for practical implementation. This research advances audio fingerprinting's adaptability, addressing challenges in varied environments and applications.
Read more6/4/2024

0
Generalized Holographic Reduced Representations
Calvin Yeung, Zhuowen Zou, Mohsen Imani
Deep learning has achieved remarkable success in recent years. Central to its success is its ability to learn representations that preserve task-relevant structure. However, massive energy, compute, and data costs are required to learn general representations. This paper explores Hyperdimensional Computing (HDC), a computationally and data-efficient brain-inspired alternative. HDC acts as a bridge between connectionist and symbolic approaches to artificial intelligence (AI), allowing explicit specification of representational structure as in symbolic approaches while retaining the flexibility of connectionist approaches. However, HDC's simplicity poses challenges for encoding complex compositional structures, especially in its binding operation. To address this, we propose Generalized Holographic Reduced Representations (GHRR), an extension of Fourier Holographic Reduced Representations (FHRR), a specific HDC implementation. GHRR introduces a flexible, non-commutative binding operation, enabling improved encoding of complex data structures while preserving HDC's desirable properties of robustness and transparency. In this work, we introduce the GHRR framework, prove its theoretical properties and its adherence to HDC properties, explore its kernel and binding characteristics, and perform empirical experiments showcasing its flexible non-commutativity, enhanced decoding accuracy for compositional structures, and improved memorization capacity compared to FHRR.
Read more5/17/2024

0
Representation Loss Minimization with Randomized Selection Strategy for Efficient Environmental Fake Audio Detection
Orchid Chetia Phukan, Girish, Mohd Mujtaba Akhtar, Swarup Ranjan Behera, Nitin Choudhury, Arun Balaji Buduru, Rajesh Sharma, S. R Mahadeva Prasanna
The adaptation of foundation models has significantly advanced environmental audio deepfake detection (EADD), a rapidly growing area of research. These models are typically fine-tuned or utilized in their frozen states for downstream tasks. However, the dimensionality of their representations can substantially lead to a high parameter count of downstream models, leading to higher computational demands. So, a general way is to compress these representations by leveraging state-of-the-art (SOTA) unsupervised dimensionality reduction techniques (PCA, SVD, KPCA, GRP) for efficient EADD. However, with the application of such techniques, we observe a drop in performance. So in this paper, we show that representation vectors contain redundant information, and randomly selecting 40-50% of representation values and building downstream models on it preserves or sometimes even improves performance. We show that such random selection preserves more performance than the SOTA dimensionality reduction techniques while reducing model parameters and inference time by almost over half.
Read more9/25/2024