Advancing LLM Reasoning Generalists with Preference Trees
2404.02078
1
0
Abstract
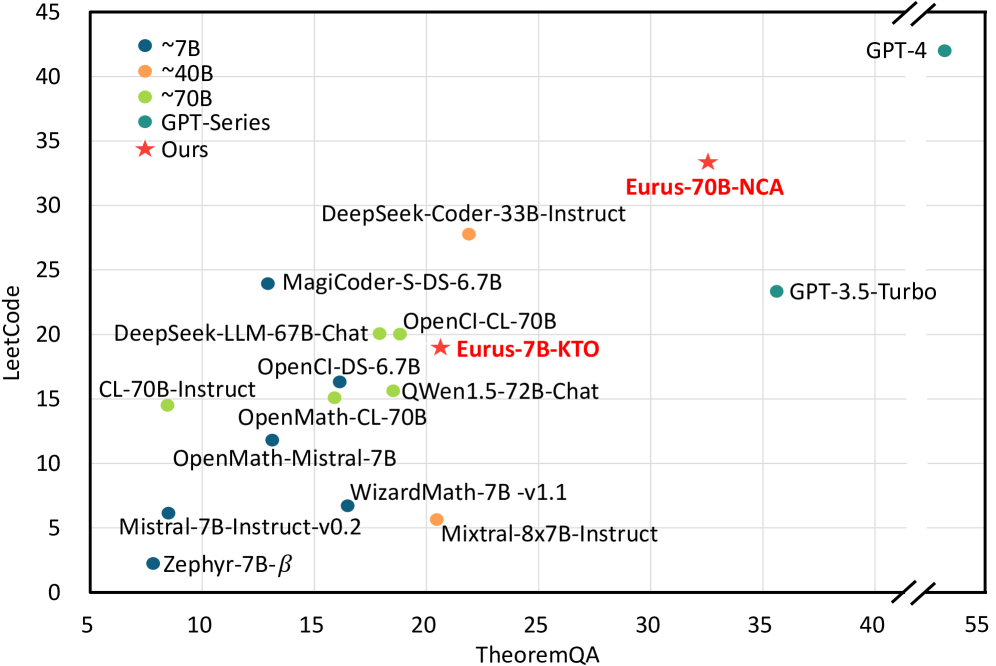
We introduce Eurus, a suite of large language models (LLMs) optimized for reasoning. Finetuned from Mistral-7B and CodeLlama-70B, Eurus models achieve state-of-the-art results among open-source models on a diverse set of benchmarks covering mathematics, code generation, and logical reasoning problems. Notably, Eurus-70B beats GPT-3.5 Turbo in reasoning through a comprehensive benchmarking across 12 tests covering five tasks, and achieves a 33.3% pass@1 accuracy on LeetCode and 32.6% on TheoremQA, two challenging benchmarks, substantially outperforming existing open-source models by margins more than 13.3%. The strong performance of Eurus can be primarily attributed to UltraInteract, our newly-curated large-scale, high-quality alignment dataset specifically designed for complex reasoning tasks. UltraInteract can be used in both supervised fine-tuning and preference learning. For each instruction, it includes a preference tree consisting of (1) reasoning chains with diverse planning strategies in a unified format, (2) multi-turn interaction trajectories with the environment and the critique, and (3) pairwise data to facilitate preference learning. UltraInteract allows us to conduct an in-depth exploration of preference learning for reasoning tasks. Our investigation reveals that some well-established preference learning algorithms may be less suitable for reasoning tasks compared to their effectiveness in general conversations. Inspired by this, we derive a novel reward modeling objective which, together with UltraInteract, leads to a strong reward model.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a new approach called "UltraInteract" that uses tree-structured alignment data to improve the reasoning capabilities of large language models (LLMs).
- The researchers developed a dataset of preference trees, where users express their preferences between different response options for a given context.
- This alignment data is used to train LLMs to better understand human preferences and make more informed decisions, particularly in open-ended tasks that require complex reasoning.
Plain English Explanation
The paper focuses on enhancing the reasoning abilities of large language models (LLMs), which are AI systems that can generate human-like text. These models are powerful, but they can struggle with open-ended tasks that require complex reasoning, such as decision-making or problem-solving.
The researchers developed a new approach called "UltraInteract" to address this challenge. UltraInteract uses a dataset of "preference trees" to train the LLMs. Preference trees are like a decision tree, where users express their preferences between different response options for a given situation. For example, in a scenario where a customer is choosing a product, the preference tree might show that the customer values price over features, but then also prefers a longer warranty over a shorter one.
By training the LLMs on this preference tree data, the researchers aim to help the models better understand human preferences and make more informed decisions. This could be particularly useful in open-ended tasks where there are many possible options, and the model needs to consider the trade-offs and priorities of the user or decision-maker.
Technical Explanation
The paper introduces the "UltraInteract" dataset, which contains tree-structured alignment data capturing user preferences. In this dataset, users are presented with a context (e.g., a decision-making scenario) and a set of possible response options. The users then express their preferences by selecting the option they most prefer, and then further refining their preferences by selecting the option they prefer between the remaining options.
This process continues, creating a tree-like structure that represents the user's evolving preferences. The researchers collected a large dataset of these preference trees, which they then used to train large language models (LLMs) to better understand and reason about human preferences.
The key insight is that this tree-structured alignment data provides a richer signal for the LLMs compared to traditional binary or categorical preference data. By learning the structure of how users refine their preferences, the models can better capture the nuances and trade-offs that people consider when making decisions.
The researchers evaluate their approach on a range of tasks, including open-ended decision-making and problem-solving, and find that LLMs trained on the UltraInteract dataset demonstrate improved reasoning and decision-making capabilities compared to models trained on traditional datasets.
Critical Analysis
The paper presents a novel and promising approach to enhancing the reasoning abilities of large language models. The use of preference trees as a training signal is an interesting idea that could help models better understand and reason about human decision-making processes.
However, the paper does not address several potential limitations and areas for further research. For example, the researchers do not discuss how the preference tree data was collected or how representative it is of the broader population. There may be biases or skewed preferences in the dataset that could limit the generalizability of the models.
Additionally, the paper does not explore how the UltraInteract approach could be applied to more open-ended, real-world decision-making scenarios, where the context and options may be less well-defined. Further research would be needed to understand the scalability and robustness of the approach in more complex, ambiguous settings.
Finally, the paper does not address potential ethical concerns around the use of large language models for decision-making, particularly in high-stakes domains. As these models become more capable of reasoning about human preferences, it will be important to consider the implications and potential risks, such as the amplification of biases or the displacement of human decision-makers.
Conclusion
Overall, the "UltraInteract" approach presented in this paper represents an interesting and potentially valuable step towards enhancing the reasoning capabilities of large language models. By leveraging tree-structured preference data, the researchers have demonstrated that LLMs can be trained to better understand and reason about human decision-making processes.
This work could have important implications for a wide range of applications, from personal decision support systems to more informed policy-making and planning. However, further research is needed to address the limitations and potential ethical concerns raised in the paper, as well as to explore the scalability and real-world applicability of the approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
0
0
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the critical importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and SciQ, with substantial percentage increases in accuracy to $80.7%$ (+$4.8%$), $32.2%$ (+$3.3%$), and $88.5%$ (+$7.7%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains.
5/2/2024
Iterative Reasoning Preference Optimization
Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, Jason Weston
0
0
Iterative preference optimization methods have recently been shown to perform well for general instruction tuning tasks, but typically make little improvement on reasoning tasks (Yuan et al., 2024, Chen et al., 2024). In this work we develop an iterative approach that optimizes the preference between competing generated Chain-of-Thought (CoT) candidates by optimizing for winning vs. losing reasoning steps that lead to the correct answer. We train using a modified DPO loss (Rafailov et al., 2023) with an additional negative log-likelihood term, which we find to be crucial. We show reasoning improves across repeated iterations of this scheme. While only relying on examples in the training set, our approach results in increasing accuracy on GSM8K, MATH, and ARC-Challenge for Llama-2-70B-Chat, outperforming other Llama-2-based models not relying on additionally sourced datasets. For example, we see a large improvement from 55.6% to 81.6% on GSM8K and an accuracy of 88.7% with majority voting out of 32 samples.
5/8/2024
💬
LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
Shibo Hao, Yi Gu, Haotian Luo, Tianyang Liu, Xiyan Shao, Xinyuan Wang, Shuhua Xie, Haodi Ma, Adithya Samavedhi, Qiyue Gao, Zhen Wang, Zhiting Hu
0
0
Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Despite the flux of research on developing advanced reasoning approaches, systematically analyzing the diverse LLMs and reasoning strategies in generating reasoning chains remains a significant challenge. The difficulties stem from the lack of two key elements: (1) an automatic method for evaluating the generated reasoning chains on different tasks, and (2) a unified formalism and implementation of the diverse reasoning approaches for systematic comparison. This paper aims to close the gap: (1) We introduce AutoRace for fully automated reasoning chain evaluation. Existing metrics rely on expensive human annotations or pre-defined LLM prompts not adaptable to different tasks. In contrast, AutoRace automatically creates detailed evaluation criteria tailored for each task, and uses GPT-4 for accurate evaluation following the criteria. (2) We develop LLM Reasoners, a library for standardized modular implementation of existing and new reasoning algorithms, under a unified formulation of the search, reward, and world model components. With the new evaluation and library, (3) we conduct extensive study of different reasoning approaches (e.g., CoT, ToT, RAP). The analysis reveals interesting findings about different factors contributing to reasoning, including the reward-guidance, breadth-vs-depth in search, world model, and prompt formats, etc.
4/9/2024
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
0
0
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
4/1/2024