Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
2405.00451
0
0
🔎
Abstract
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
Create account to get full access
Overview
- Introduces an approach to enhance the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process
- Leverages Monte Carlo Tree Search (MCTS) to collect preference data and break down instance-level rewards into more granular step-level signals
- Combines outcome validation and stepwise self-evaluation to enhance consistency in intermediate steps
- Employs Direct Preference Optimization (DPO) to update the LLM policy using the generated step-level preference data
- Theoretical analysis highlights the importance of using on-policy sampled data for successful self-improving
- Extensive evaluations demonstrate remarkable performance improvements over existing models on various reasoning tasks
Plain English Explanation
The paper presents a novel approach to improve the reasoning abilities of large language models (LLMs), which are powerful AI systems that can understand and generate human-like text. The key idea is to use an iterative process inspired by the successful AlphaZero strategy, which has achieved superhuman performance in games like chess and Go.
The researchers use a technique called Monte Carlo Tree Search (MCTS) to collect data on how the LLM preferences certain outcomes or steps during the reasoning process. MCTS allows the model to look ahead and break down the overall task into smaller, more granular steps. This helps the model learn not just the final answer, but also the individual reasoning steps that lead to it.
To ensure consistency in these intermediate steps, the researchers combine two techniques: outcome validation and stepwise self-evaluation. Outcome validation checks if the final result is correct, while stepwise self-evaluation continuously assesses the quality of the newly generated data.
The model then uses a method called Direct Preference Optimization (DPO) to update its policy based on the step-level preference data collected through this process. Theoretical analysis shows that using data from the model's own decision-making (on-policy data) is crucial for this self-improving approach to work effectively.
The researchers evaluate their method on various arithmetic and commonsense reasoning tasks, and the results are impressive. For example, their approach outperforms a strong baseline model by a significant margin on tasks like GSM8K, MATH, and SciQ. The paper also provides insights into the trade-off between training and inference compute, showing how the proposed method can effectively maximize performance gains.
Technical Explanation
The core idea of the paper is to enhance the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful AlphaZero strategy. The researchers leverage Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals.
To improve consistency in the intermediate steps, the proposed algorithm combines outcome validation and stepwise self-evaluation. Outcome validation checks if the final result is correct, while stepwise self-evaluation continually updates the quality assessment of newly generated data. This helps the model learn not just the final answer, but also the individual reasoning steps that lead to it.
The researchers then employ Direct Preference Optimization (DPO) to update the LLM policy using the generated step-level preference data. Theoretical analysis reveals the critical importance of using on-policy sampled data for successful self-improving.
Extensive evaluations on various arithmetic and commonsense reasoning tasks, such as GSM8K, MATH, and SciQ, demonstrate remarkable performance improvements over existing models. For instance, the proposed approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on these tasks, with substantial percentage increases in accuracy.
Additionally, the paper delves into the training and inference compute tradeoff, providing insights into how the proposed method effectively maximizes performance gains.
Critical Analysis
The paper presents a well-designed and comprehensive approach to enhancing the reasoning capabilities of Large Language Models. The use of MCTS to collect granular step-level preference data and the combination of outcome validation and stepwise self-evaluation are particularly innovative and likely contribute to the observed performance improvements.
However, the paper does not address the potential computational overhead associated with the iterative preference learning process. While the theoretical analysis highlights the importance of using on-policy sampled data, the practical implications of maintaining a balance between exploration and exploitation during this iterative process could be further explored.
Additionally, the paper focuses on a limited set of reasoning tasks, and it would be valuable to see how the proposed approach performs on a wider range of tasks, including more open-ended and natural language understanding challenges. Evaluating the method's robustness and generalizability across diverse domains would provide a more comprehensive understanding of its capabilities.
Lastly, the paper could have delved deeper into the interpretability and explainability of the model's reasoning process. Providing more insights into how the step-level preference data is used to enhance the model's decision-making could help researchers and practitioners better understand the underlying mechanisms driving the performance improvements.
Conclusion
The proposed approach represents a significant advancement in enhancing the reasoning capabilities of Large Language Models. By leveraging an iterative preference learning process inspired by the successful AlphaZero strategy, the researchers have demonstrated substantial performance improvements on various arithmetic and commonsense reasoning tasks.
The key innovations, such as the use of MCTS to collect granular step-level preference data and the combination of outcome validation and stepwise self-evaluation, show the potential of this approach to push the boundaries of LLM reasoning abilities. The theoretical insights on the importance of on-policy sampled data further strengthen the foundations of this self-improving system.
While the paper raises some potential areas for further exploration, such as computational overhead and interpretability, the overall contribution is valuable and could have far-reaching implications for the development of more capable and trustworthy AI systems. As the field of large language models continues to evolve, this research represents an important step towards building genuinely intelligent and reasoning-driven models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Step-level Value Preference Optimization for Mathematical Reasoning
Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan
0
0
Direct Preference Optimization (DPO) using an implicit reward model has proven to be an effective alternative to reinforcement learning from human feedback (RLHF) for fine-tuning preference aligned large language models (LLMs). However, the overall preference annotations of responses do not fully capture the fine-grained quality of model outputs in complex multi-step reasoning tasks, such as mathematical reasoning. To address this limitation, we introduce a novel algorithm called Step-level Value Preference Optimization (SVPO). Our approach employs Monte Carlo Tree Search (MCTS) to automatically annotate step-level preferences for multi-step reasoning. Furthermore, from the perspective of learning-to-rank, we train an explicit value model to replicate the behavior of the implicit reward model, complementing standard preference optimization. This value model enables the LLM to generate higher reward responses with minimal cost during inference. Experimental results demonstrate that our method achieves state-of-the-art performance on both in-domain and out-of-domain mathematical reasoning benchmarks.
6/18/2024
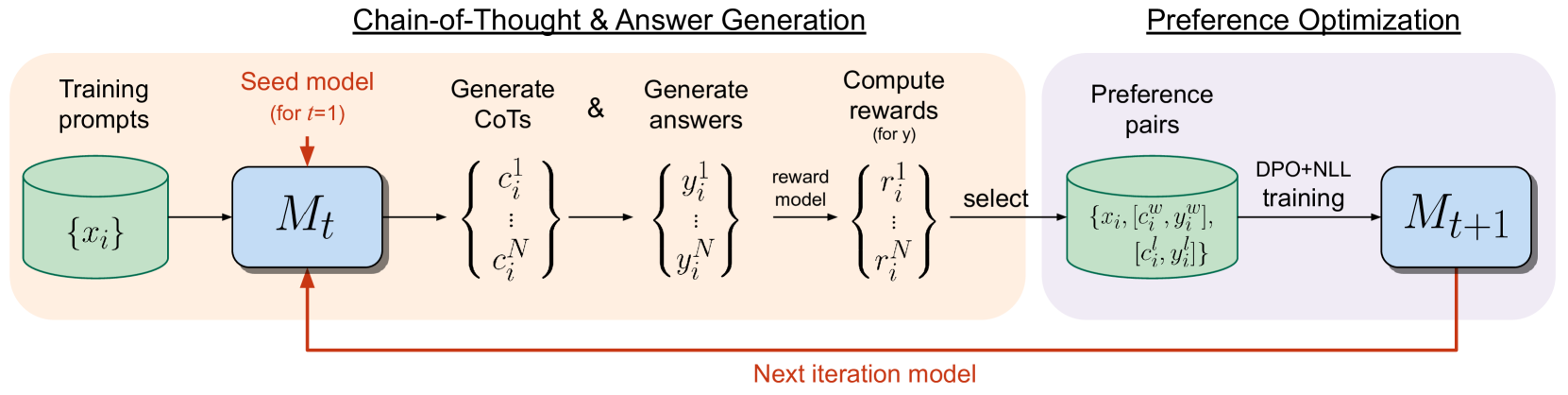
Iterative Reasoning Preference Optimization
Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, Jason Weston
0
0
Iterative preference optimization methods have recently been shown to perform well for general instruction tuning tasks, but typically make little improvement on reasoning tasks (Yuan et al., 2024, Chen et al., 2024). In this work we develop an iterative approach that optimizes the preference between competing generated Chain-of-Thought (CoT) candidates by optimizing for winning vs. losing reasoning steps that lead to the correct answer. We train using a modified DPO loss (Rafailov et al., 2023) with an additional negative log-likelihood term, which we find to be crucial. We show reasoning improves across repeated iterations of this scheme. While only relying on examples in the training set, our approach results in increasing accuracy on GSM8K, MATH, and ARC-Challenge for Llama-2-70B-Chat, outperforming other Llama-2-based models not relying on additionally sourced datasets. For example, we see a large improvement from 55.6% to 81.6% on GSM8K and an accuracy of 88.7% with majority voting out of 32 samples.
6/27/2024
✅
Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy F. Chen, Shafiq Joty
0
0
Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through Direct Preference Optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
4/16/2024
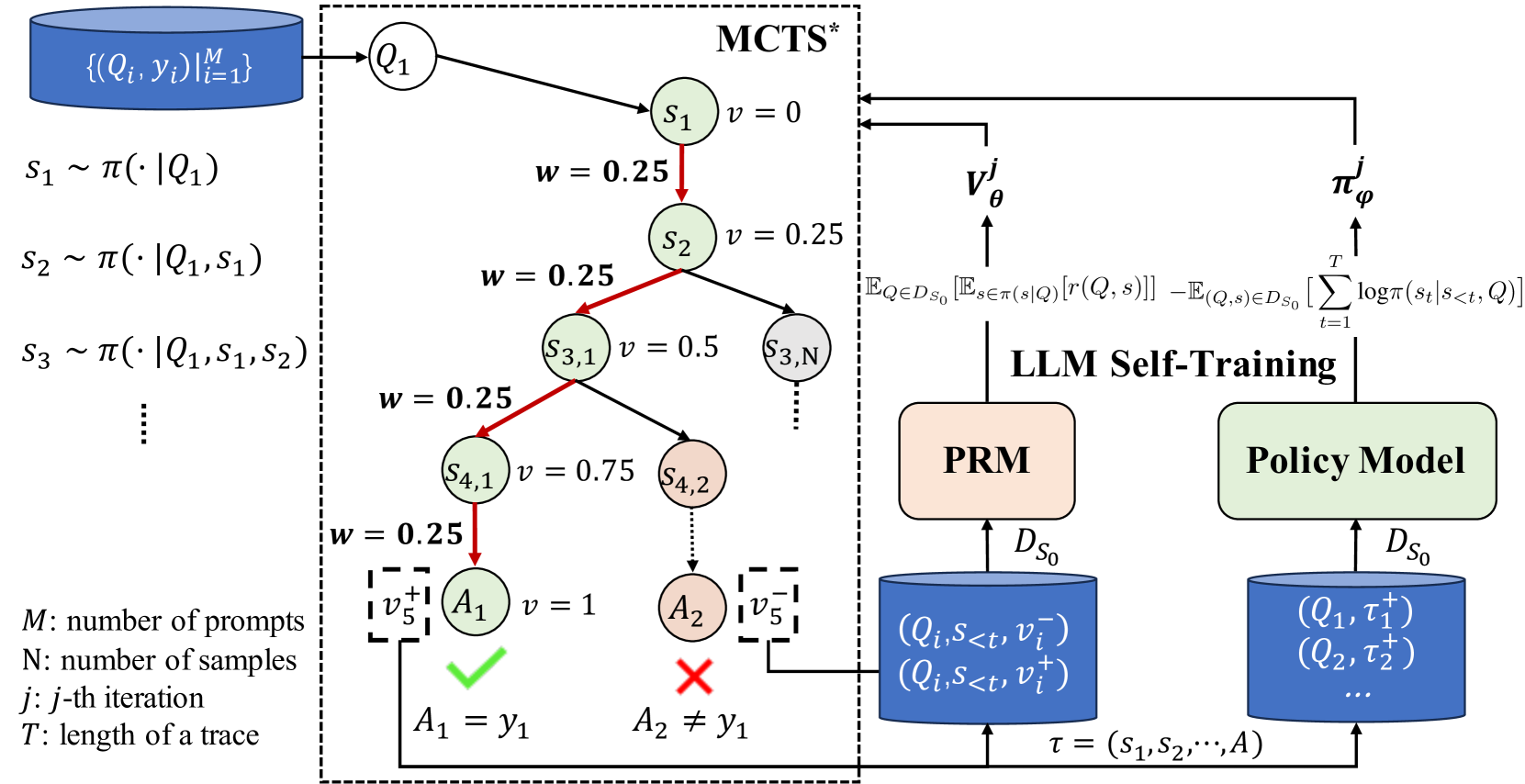
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Dan Zhang, Sining Zhoubian, Yisong Yue, Yuxiao Dong, Jie Tang
0
0
Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^text{EM}$ and Self-Rewarding LM.
6/7/2024