Advancing Multi-talker ASR Performance with Large Language Models

0
🚀
Sign in to get full access
Overview
- This paper presents a novel approach for serialized output training, where a model learns to generate multiple output elements in a sequential manner.
- The proposed method aims to improve the performance of text generation tasks by capturing dependencies between output tokens.
- The authors evaluate their approach on several natural language generation benchmarks and demonstrate its effectiveness compared to traditional sequence-to-sequence models.
Plain English Explanation
The paper introduces a new way of training machine learning models to generate text. Typically, these models are trained to produce an entire output sequence all at once. However, the authors argue that it can be beneficial for the model to learn to generate the output in a more sequential manner, producing one element at a time.
This "serialized output training" approach allows the model to better capture the relationships between the different parts of the output. For example, when generating a sentence, the model can learn how the choice of one word affects the subsequent words, resulting in more coherent and natural-sounding text.
The researchers evaluate their serialized output training method on several language generation tasks, such as summarizing articles or translating between languages. They find that this approach outperforms traditional sequence-to-sequence models, which generate the entire output at once.
The key idea is that by breaking down the output generation process into smaller, sequential steps, the model can learn more nuanced patterns in the data and produce higher-quality text. This could have important applications in areas like [<a href="https://aimodels.fyi/papers/arxiv/cross-speaker-encoding-network-multi-talker-speech">speech synthesis</a>], [<a href="https://aimodels.fyi/papers/arxiv/investigating-decoder-only-large-language-models-speech">language modeling</a>], and [<a href="https://aimodels.fyi/papers/arxiv/generating-data-text-to-speech-large-language">text generation</a>].
Technical Explanation
The paper proposes a novel training approach called "Serialized Output Training" (SOT) for sequence-to-sequence models. In traditional sequence-to-sequence models, the output is generated all at once, with the model predicting the entire output sequence in a single step.
In contrast, the SOT method trains the model to generate the output in a more sequential manner, predicting one output element at a time. This is achieved by modifying the model architecture to include a "dominance predictor" component, which learns to predict the relative importance of each output token. The model then uses this predicted dominance to guide the sequential generation of the output.
The authors evaluate their SOT approach on several natural language generation tasks, including text summarization, machine translation, and data-to-text generation. They compare the performance of SOT models to traditional sequence-to-sequence models and find that the SOT models consistently outperform the baselines, particularly on longer output sequences.
The key insight behind SOT is that by breaking down the output generation process into smaller, sequential steps, the model can better capture the dependencies between output tokens. This allows the model to generate more coherent and natural-sounding text, as it can learn how the choice of one output element affects the subsequent elements.
Critical Analysis
The paper presents a compelling approach for improving the performance of sequence-to-sequence models in text generation tasks. The authors provide a thorough evaluation of their method on diverse benchmarks, which strengthens the case for the effectiveness of their serialized output training approach.
One potential limitation of the SOT method is that it may increase the computational complexity of the model, as the additional "dominance predictor" component adds an extra layer of processing. The authors acknowledge this and suggest that future work could explore ways to optimize the model architecture and training process to mitigate any efficiency concerns.
Additionally, the paper does not delve deeply into the interpretability of the learned dominance predictor. It would be interesting to understand how the model determines the relative importance of each output token and whether this provides any insights into the underlying patterns in the data.
Another area for further research could be exploring the application of SOT to other domains beyond natural language processing, such as [<a href="https://aimodels.fyi/papers/arxiv/style-talker-finetuning-audio-language-model-style">audio generation</a>] or [<a href="https://aimodels.fyi/papers/arxiv/generating-data-text-to-speech-large-language">multimodal generation</a>]. The core principles of serialized output training may be relevant in these areas as well.
Conclusion
This paper presents a novel approach called "Serialized Output Training" (SOT) that aims to improve the performance of sequence-to-sequence models in text generation tasks. By training the model to generate output elements in a more sequential manner, the SOT method captures dependencies between output tokens, leading to more coherent and natural-sounding text.
The authors provide a thorough evaluation of their approach on several benchmarks, demonstrating its effectiveness compared to traditional sequence-to-sequence models. While the paper identifies some potential computational overhead, the core idea of serialized output training shows promise and could have broader applications in fields like speech synthesis, language modeling, and multimodal generation.
Overall, this work contributes a valuable advancement in the field of text generation and highlights the importance of exploring novel model architectures and training strategies to unlock the full potential of machine learning for natural language tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Advancing Multi-talker ASR Performance with Large Language Models
Mohan Shi, Zengrui Jin, Yaoxun Xu, Yong Xu, Shi-Xiong Zhang, Kun Wei, Yiwen Shao, Chunlei Zhang, Dong Yu
Recognizing overlapping speech from multiple speakers in conversational scenarios is one of the most challenging problem for automatic speech recognition (ASR). Serialized output training (SOT) is a classic method to address multi-talker ASR, with the idea of concatenating transcriptions from multiple speakers according to the emission times of their speech for training. However, SOT-style transcriptions, derived from concatenating multiple related utterances in a conversation, depend significantly on modeling long contexts. Therefore, compared to traditional methods that primarily emphasize encoder performance in attention-based encoder-decoder (AED) architectures, a novel approach utilizing large language models (LLMs) that leverages the capabilities of pre-trained decoders may be better suited for such complex and challenging scenarios. In this paper, we propose an LLM-based SOT approach for multi-talker ASR, leveraging pre-trained speech encoder and LLM, fine-tuning them on multi-talker dataset using appropriate strategies. Experimental results demonstrate that our approach surpasses traditional AED-based methods on the simulated dataset LibriMix and achieves state-of-the-art performance on the evaluation set of the real-world dataset AMI, outperforming the AED model trained with 1000 times more supervised data in previous works.
Read more9/2/2024
0
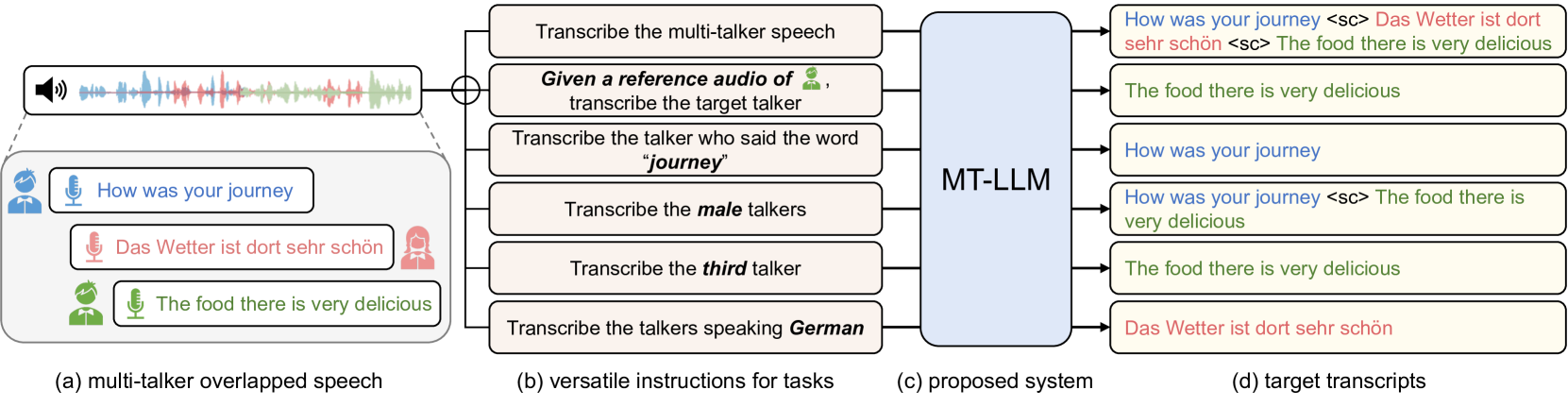
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024

0
Serialized Output Training by Learned Dominance
Ying Shi, Lantian Li, Shi Yin, Dong Wang, Jiqing Han
Serialized Output Training (SOT) has showcased state-of-the-art performance in multi-talker speech recognition by sequentially decoding the speech of individual speakers. To address the challenging label-permutation issue, prior methods have relied on either the Permutation Invariant Training (PIT) or the time-based First-In-First-Out (FIFO) rule. This study presents a model-based serialization strategy that incorporates an auxiliary module into the Attention Encoder-Decoder architecture, autonomously identifying the crucial factors to order the output sequence of the speech components in multi-talker speech. Experiments conducted on the LibriSpeech and LibriMix databases reveal that our approach significantly outperforms the PIT and FIFO baselines in both 2-mix and 3-mix scenarios. Further analysis shows that the serialization module identifies dominant speech components in a mixture by factors including loudness and gender, and orders speech components based on the dominance score.
Read more7/8/2024

0
Cross-Speaker Encoding Network for Multi-Talker Speech Recognition
Jiawen Kang, Lingwei Meng, Mingyu Cui, Haohan Guo, Xixin Wu, Xunying Liu, Helen Meng
End-to-end multi-talker speech recognition has garnered great interest as an effective approach to directly transcribe overlapped speech from multiple speakers. Current methods typically adopt either 1) single-input multiple-output (SIMO) models with a branched encoder, or 2) single-input single-output (SISO) models based on attention-based encoder-decoder architecture with serialized output training (SOT). In this work, we propose a Cross-Speaker Encoding (CSE) network to address the limitations of SIMO models by aggregating cross-speaker representations. Furthermore, the CSE model is integrated with SOT to leverage both the advantages of SIMO and SISO while mitigating their drawbacks. To the best of our knowledge, this work represents an early effort to integrate SIMO and SISO for multi-talker speech recognition. Experiments on the two-speaker LibrispeechMix dataset show that the CES model reduces word error rate (WER) by 8% over the SIMO baseline. The CSE-SOT model reduces WER by 10% overall and by 16% on high-overlap speech compared to the SOT model. Code is available at https://github.com/kjw11/CSEnet-ASR.
Read more7/23/2024