Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions

0
Sign in to get full access
Overview
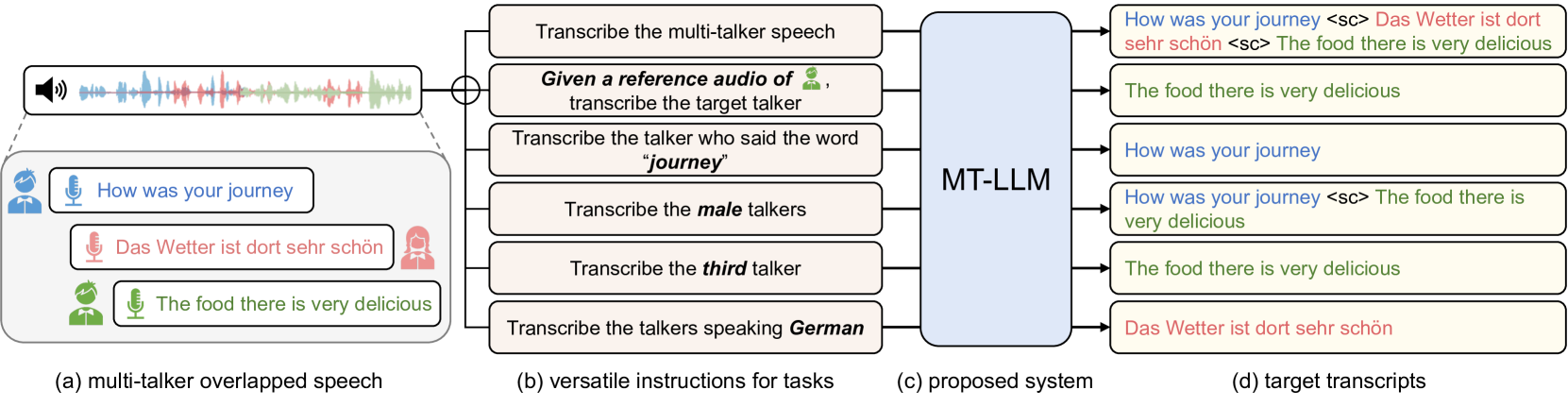
- Large language models (LLMs) can now transcribe speech in multi-talker scenarios using versatile instructions.
- This represents a significant advancement in the field of speech recognition, addressing the "cocktail party problem" where multiple speakers are talking at the same time.
- The paper demonstrates how LLMs can be applied to this challenging task, opening up new possibilities for improved voice interfaces and assistants.
Plain English Explanation
Large language models are powerful AI systems that can understand and generate human-like text. Researchers have now shown that these models can also be used to transcribe speech - even in situations where multiple people are talking at the same time.
This "cocktail party problem" has long been a challenge in speech recognition, as it's difficult for computers to isolate and transcribe individual speakers in a noisy, multi-talker environment. But the researchers found that by providing LLMs with the right instructions, they could effectively tackle this task.
The key is that LLMs are incredibly flexible and can adapt to a wide range of language-related challenges, from understanding context to following complex prompts. This allows them to transcribe speech in these multi-talker scenarios, which could lead to major improvements in voice-based interfaces and assistants.
Technical Explanation
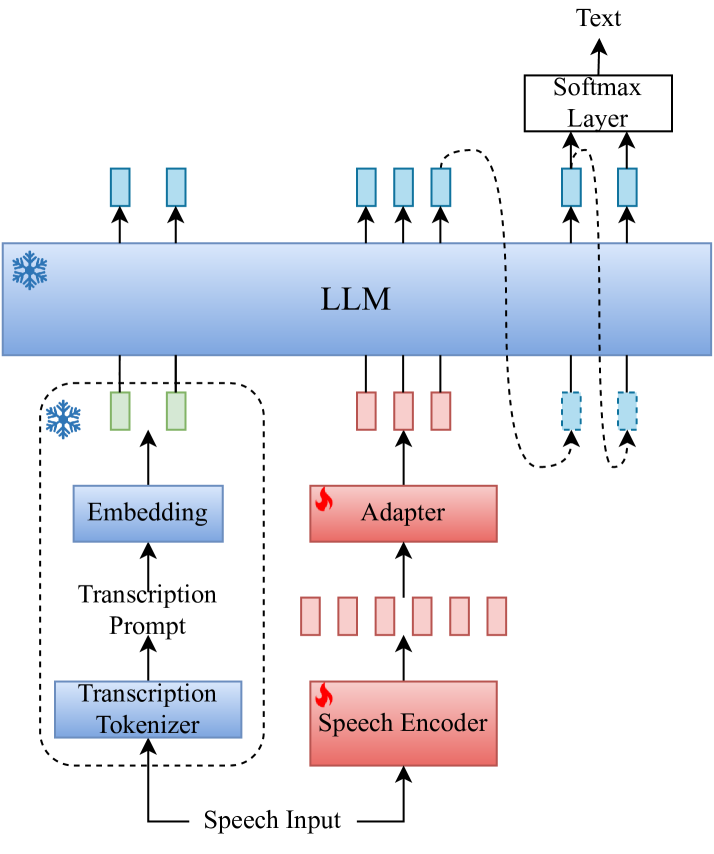
The researchers developed a system that uses a large language model to transcribe speech in multi-talker scenarios. They fine-tuned the LLM on a dataset of speech recordings with multiple speakers, along with corresponding transcripts.
Crucially, they also provided the LLM with versatile instructions that allowed it to adapt to different task variations. For example, the model could be instructed to transcribe a specific speaker's words, or to provide a full transcript of all speakers.
Through extensive testing, the researchers demonstrated that this LLM-based system outperformed traditional speech recognition approaches in multi-talker scenarios. The model was able to accurately identify and transcribe individual speakers, even when there was significant background noise and overlapping speech.
The researchers attribute the success of their approach to the inherent flexibility and contextual understanding of large language models. By leveraging these capabilities, they were able to create a speech transcription system that is more robust and versatile than previous methods.
Critical Analysis
The researchers acknowledge several limitations of their work. The dataset used for fine-tuning the LLM, while large, may not fully capture the diversity of real-world multi-talker scenarios. Additionally, the model's performance could be further improved by incorporating more advanced audio processing techniques.
It's also worth noting that while the results are impressive, the system is still not perfect. There may be edge cases or challenging audio environments where the LLM-based approach struggles to maintain accurate transcription.
Further research is needed to fully understand the capabilities and limitations of using large language models for this task. Exploring ways to combine LLMs with other speech recognition techniques could lead to even more robust and versatile systems.
Conclusion
This research demonstrates the remarkable potential of large language models to tackle the challenging problem of multi-talker speech recognition. By leveraging the flexibility and contextual understanding of LLMs, the researchers have created a system that can effectively transcribe speech in complex, noisy environments.
While not without its limitations, this work represents a significant step forward in the field of speech recognition. The ability to accurately transcribe speech in multi-talker scenarios has far-reaching implications, from improved voice assistants to more effective collaboration tools.
As large language models continue to advance, we can expect to see even more innovative applications in the realm of speech and audio processing. This research serves as an exciting glimpse into the future of how these powerful AI systems can be applied to solve complex, real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024
0
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, Furu Wei
The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at url{aka.ms/wavllm}.
Read more8/15/2024
0
A Transcription Prompt-based Efficient Audio Large Language Model for Robust Speech Recognition
Yangze Li, Xiong Wang, Songjun Cao, Yike Zhang, Long Ma, Lei Xie
Audio-LLM introduces audio modality into a large language model (LLM) to enable a powerful LLM to recognize, understand, and generate audio. However, during speech recognition in noisy environments, we observed the presence of illusions and repetition issues in audio-LLM, leading to substitution and insertion errors. This paper proposes a transcription prompt-based audio-LLM by introducing an ASR expert as a transcription tokenizer and a hybrid Autoregressive (AR) Non-autoregressive (NAR) decoding approach to solve the above problems. Experiments on 10k-hour WenetSpeech Mandarin corpus show that our approach decreases 12.2% and 9.6% CER relatively on Test_Net and Test_Meeting evaluation sets compared with baseline. Notably, we reduce the decoding repetition rate on the evaluation set to zero, showing that the decoding repetition problem has been solved fundamentally.
Read more8/20/2024

0
Just ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue
Junkai Wu, Xulin Fan, Bo-Ru Lu, Xilin Jiang, Nima Mesgarani, Mark Hasegawa-Johnson, Mari Ostendorf
In recent years, we have observed a rapid advancement in speech language models (SpeechLLMs), catching up with humans' listening and reasoning abilities. Remarkably, SpeechLLMs have demonstrated impressive spoken dialogue question-answering (SQA) performance in benchmarks like Gaokao, the English listening test of the college entrance exam in China, which seemingly requires understanding both the spoken content and voice characteristics of speakers in a conversation. However, after carefully examining Gaokao's questions, we find the correct answers to many questions can be inferred from the conversation context alone without identifying the speaker asked in the question. Our evaluation of state-of-the-art models Qwen-Audio and WavLLM in both Gaokao and our proposed What Do You Like? dataset shows a significantly higher accuracy in these context-based questions than in identity-critical questions, which can only be answered correctly with correct speaker identification. Our results and analysis suggest that when solving SQA, the current SpeechLLMs exhibit limited speaker awareness from the audio and behave similarly to an LLM reasoning from the conversation transcription without sound. We propose that our definitions and automated classification of context-based and identity-critical questions could offer a more accurate evaluation framework of SpeechLLMs in SQA tasks.
Read more9/10/2024