Advancing Prompt Learning through an External Layer

0

Sign in to get full access
Overview
- The paper explores an approach to improve prompt learning for vision-language models.
- It introduces an "external layer" that can be optimized separately from the pre-trained model.
- The key idea is to learn prompt embeddings that can effectively steer the pre-trained model to perform desired tasks.
Plain English Explanation
The paper focuses on improving "prompt learning" for vision-language models. Prompt learning involves providing short textual instructions, or "prompts," to guide a pre-trained model in performing a specific task, like image classification or text generation.
The researchers propose adding an "external layer" to the model, which can be optimized separately from the main pre-trained model. This external layer learns prompt embeddings that effectively steer the pre-trained model to perform the desired tasks. The key idea is that by learning these prompt embeddings independently, the model can be more easily adapted to new tasks or datasets, without having to retrain the entire model.
Essentially, the external layer acts as an intermediary between the user's prompt and the pre-trained model's internal representations. By optimizing this layer, the researchers aim to unlock the full potential of pre-trained vision-language models for a wide range of applications.
Technical Explanation
The paper introduces a novel architecture that includes an "external layer" in addition to the pre-trained vision-language model. This external layer is responsible for generating prompt embeddings, which are then used to condition the pre-trained model's outputs.
The researchers formulate the problem as an optimal transport task, where the goal is to find the optimal mapping between the user's prompt and the pre-trained model's internal representations. By learning this mapping through the external layer, the model can effectively leverage the pre-trained knowledge while adapting to new tasks or datasets.
The external layer is trained using a combination of task-specific loss functions and a regularization term that encourages the prompt embeddings to be diverse and informative. This approach allows the model to learn prompts that are both effective for the target task and distinct from each other, enabling better generalization.
The paper demonstrates the effectiveness of this approach through experiments on various vision-language tasks, including image classification, image-text retrieval, and text generation. The results show that the external layer-based approach outperforms traditional prompt learning methods, particularly in low-data regimes and when transferring to new tasks.
Critical Analysis
The paper presents a promising approach to improving prompt learning for vision-language models. By introducing the external layer, the researchers have provided a flexible and efficient way to adapt pre-trained models to new tasks without the need for full model retraining.
One potential limitation mentioned in the paper is the need for task-specific training of the external layer. While this allows for customization, it may limit the model's ability to generalize across a wide range of tasks without extensive fine-tuning. Exploring ways to learn more universal prompt embeddings could be an area for future research.
Additionally, the paper does not address the potential for the external layer to introduce unwanted biases or artifacts into the model's outputs. As with any prompt-based approach, there is a risk of the model becoming overly dependent on the prompts, which could lead to suboptimal or biased performance in certain scenarios. Investigating the robustness and interpretability of the external layer's prompt embeddings would be an important next step.
Overall, the paper offers a novel and compelling approach to advancing the field of prompt learning, with potential implications for a wide range of vision-language applications. Continued research in this area, addressing the identified limitations and exploring further extensions, could lead to significant advancements in the flexibility and performance of pre-trained models.
Conclusion
The paper presents an innovative approach to improving prompt learning for vision-language models by introducing an "external layer" that can be optimized separately from the pre-trained model. This external layer learns prompt embeddings that effectively steer the pre-trained model to perform desired tasks, enabling better adaptation to new datasets and applications without the need for full model retraining.
The technical insights and experimental results suggest that this approach can unlock the full potential of pre-trained vision-language models, particularly in low-data regimes and when transferring to new tasks. While the paper identifies some potential limitations, the overall contribution represents a significant step forward in the field of prompt learning and its applications in various real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Advancing Prompt Learning through an External Layer
Fangming Cui, Xun Yang, Chao Wu, Liang Xiao, Xinmei Tian
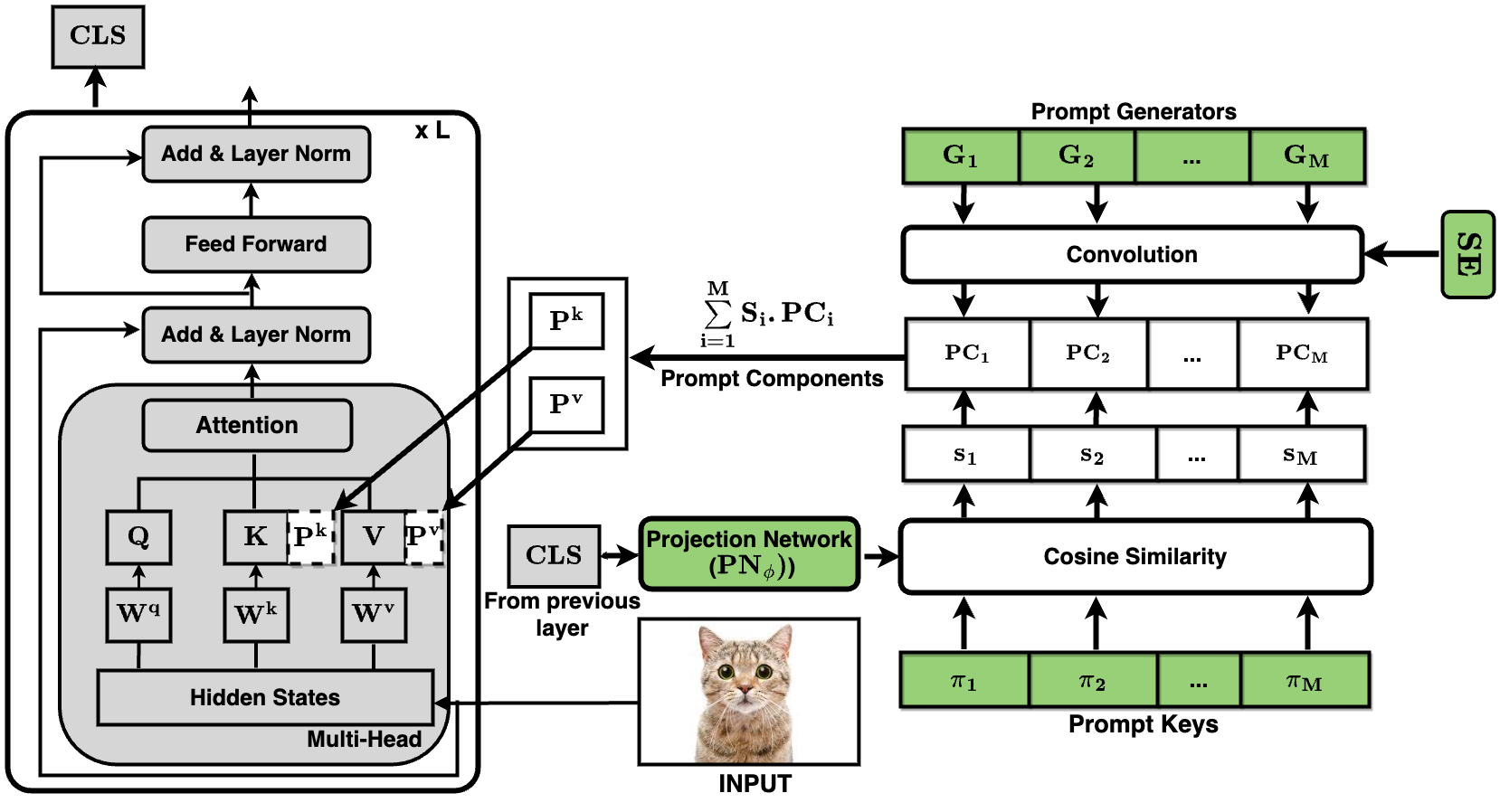
Prompt learning represents a promising method for adapting pre-trained vision-language models (VLMs) to various downstream tasks by learning a set of text embeddings. One challenge inherent to these methods is the poor generalization performance due to the invalidity of the learned text embeddings for unseen tasks. A straightforward approach to bridge this gap is to freeze the text embeddings in prompts, which results in a lack of capacity to adapt VLMs for downstream tasks. To address this dilemma, we propose a paradigm called EnPrompt with a novel External Layer (EnLa). Specifically, we propose a textual external layer and learnable visual embeddings for adapting VLMs to downstream tasks. The learnable external layer is built upon valid embeddings of pre-trained CLIP. This design considers the balance of learning capabilities between the two branches. To align the textual and visual features, we propose a novel two-pronged approach: i) we introduce the optimal transport as the discrepancy metric to align the vision and text modalities, and ii) we introduce a novel strengthening feature to enhance the interaction between these two modalities. Four representative experiments (i.e., base-to-novel generalization, few-shot learning, cross-dataset generalization, domain shifts generalization) across 15 datasets demonstrate that our method outperforms the existing prompt learning method.
Read more8/12/2024

0
Rethinking Visual Prompting for Multimodal Large Language Models with External Knowledge
Yuanze Lin, Yunsheng Li, Dongdong Chen, Weijian Xu, Ronald Clark, Philip Torr, Lu Yuan
In recent years, multimodal large language models (MLLMs) have made significant strides by training on vast high-quality image-text datasets, enabling them to generally understand images well. However, the inherent difficulty in explicitly conveying fine-grained or spatially dense information in text, such as masks, poses a challenge for MLLMs, limiting their ability to answer questions requiring an understanding of detailed or localized visual elements. Drawing inspiration from the Retrieval-Augmented Generation (RAG) concept, this paper proposes a new visual prompt approach to integrate fine-grained external knowledge, gleaned from specialized vision models (e.g., instance segmentation/OCR models), into MLLMs. This is a promising yet underexplored direction for enhancing MLLMs' performance. Our approach diverges from concurrent works, which transform external knowledge into additional text prompts, necessitating the model to indirectly learn the correspondence between visual content and text coordinates. Instead, we propose embedding fine-grained knowledge information directly into a spatial embedding map as a visual prompt. This design can be effortlessly incorporated into various MLLMs, such as LLaVA and Mipha, considerably improving their visual understanding performance. Through rigorous experiments, we demonstrate that our method can enhance MLLM performance across nine benchmarks, amplifying their fine-grained context-aware capabilities.
Read more7/8/2024

0
Revisiting Prompt Pretraining of Vision-Language Models
Zhenyuan Chen, Lingfeng Yang, Shuo Chen, Zhaowei Chen, Jiajun Liang, Xiang Li
Prompt learning is an effective method to customize Vision-Language Models (VLMs) for various downstream tasks, involving tuning very few parameters of input prompt tokens. Recently, prompt pretraining in large-scale dataset (e.g., ImageNet-21K) has played a crucial role in prompt learning for universal visual discrimination. However, we revisit and observe that the limited learnable prompts could face underfitting risks given the extensive images during prompt pretraining, simultaneously leading to poor generalization. To address the above issues, in this paper, we propose a general framework termed Revisiting Prompt Pretraining (RPP), which targets at improving the fitting and generalization ability from two aspects: prompt structure and prompt supervision. For prompt structure, we break the restriction in common practice where query, key, and value vectors are derived from the shared learnable prompt token. Instead, we introduce unshared individual query, key, and value learnable prompts, thereby enhancing the model's fitting capacity through increased parameter diversity. For prompt supervision, we additionally utilize soft labels derived from zero-shot probability predictions provided by a pretrained Contrastive Language Image Pretraining (CLIP) teacher model. These soft labels yield more nuanced and general insights into the inter-class relationships, thereby endowing the pretraining process with better generalization ability. RPP produces a more resilient prompt initialization, enhancing its robust transferability across diverse visual recognition tasks. Experiments across various benchmarks consistently confirm the state-of-the-art (SOTA) performance of our pretrained prompts. Codes and models will be made available soon.
Read more9/11/2024
0
Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy, Riddhiman Moulick, Vinay K. Verma, Saptarshi Ghosh, Abir Das
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pretrained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by ~3% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components.
Read more4/1/2024