The Solution for Language-Enhanced Image New Category Discovery

0

Sign in to get full access
Overview
- This paper proposes a solution for language-enhanced image new category discovery, which involves using language information to help identify new categories of images that were not part of the original training dataset.
- The key idea is to leverage natural language descriptions of images to guide the discovery of new visual categories, going beyond what is possible with image data alone.
- The authors develop a novel approach that combines language and visual information to effectively identify new image categories in a zero-shot learning setting.
Plain English Explanation
The researchers have created a new method to help computers discover new types of images that weren't included in their original training data. Typically, image recognition systems are limited to only the categories they were trained on. But this new approach allows the system to use language information, like captions or descriptions, to identify new visual categories that it didn't already know about.
The core idea is to combine the power of language and visual data to find new image categories more effectively than using just images alone. By leveraging the rich semantic information in language, the system can learn to recognize new visual concepts that it wasn't explicitly trained on. This could be particularly useful for applications where the space of possible image categories is very large or constantly evolving, such as in Tai: Text-as-Image Multi-Label Image Classification or Instructing Prompt-to-Prompt Generation with Zero-Shot.
Technical Explanation
The authors propose a novel framework called Language-Enhanced Image New Category Discovery (LEINCD) that integrates language and visual information to identify new image categories. The key components include:
- Visual Encoder: A convolutional neural network (CNN) that learns to extract visual features from images.
- Language Encoder: A transformer-based language model that encodes text descriptions of the images.
- Category Classifier: A module that takes the combined visual and language features and predicts the image category, including the ability to identify new unseen categories.
The model is trained in a two-stage process. First, it learns to classify images into the known categories using both visual and language data. Then, in the second stage, the model is fine-tuned to detect new image categories by leveraging the language information. This allows the system to go beyond the original set of known categories and discover new visual concepts.
The authors evaluate their approach on several benchmark datasets and show that it outperforms prior methods for zero-shot image classification and new category discovery. The language-enhanced visual representations learned by the model are particularly effective at identifying novel image categories that were not part of the original training data.
Critical Analysis
The LEINCD framework represents an interesting and promising direction for advancing image recognition capabilities. By incorporating language understanding, the model can better capture the rich semantic associations between visual and textual information, enabling the discovery of new image categories.
However, the paper does not fully address some potential limitations and areas for further research. For example, the reliance on high-quality text descriptions for each image may limit the scalability of the approach, as obtaining comprehensive captions can be costly and labor-intensive. Exploring ways to leverage more readily available language data, such as Pseudo-Prompt: Generating Pre-Trained Vision-Language Models or Dual-Modal Prompting for Sketch-Based Image Retrieval, could help address this challenge.
Additionally, the evaluation focuses primarily on the task of new category discovery, but it would be valuable to assess the model's performance on other downstream applications, such as Retrieval-Enhanced Visual Prompt Learning for Few-Shot, to better understand its broader utility and limitations.
Conclusion
The Language-Enhanced Image New Category Discovery framework proposed in this paper represents an important step towards more flexible and adaptive image recognition systems. By leveraging language information, the model can go beyond the fixed set of categories in the training data and discover new visual concepts, opening up exciting possibilities for applications that require handling evolving or open-ended image domains.
While the paper demonstrates promising results, further research is needed to address potential scalability and generalization challenges. Exploring ways to leverage more diverse language data sources and evaluating the model's performance on a broader range of tasks could help strengthen the approach and expand its real-world applicability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Solution for Language-Enhanced Image New Category Discovery
Haonan Xu, Dian Chao, Xiangyu Wu, Zhonghua Wan, Yang Yang
Treating texts as images, combining prompts with textual labels for prompt tuning, and leveraging the alignment properties of CLIP have been successfully applied in zero-shot multi-label image recognition. Nonetheless, relying solely on textual labels to store visual information is insufficient for representing the diversity of visual objects. In this paper, we propose reversing the training process of CLIP and introducing the concept of Pseudo Visual Prompts. These prompts are initialized for each object category and pre-trained on large-scale, low-cost sentence data generated by large language models. This process mines the aligned visual information in CLIP and stores it in class-specific visual prompts. We then employ contrastive learning to transfer the stored visual information to the textual labels, enhancing their visual representation capacity. Additionally, we introduce a dual-adapter module that simultaneously leverages knowledge from the original CLIP and new learning knowledge derived from downstream datasets. Benefiting from the pseudo visual prompts, our method surpasses the state-of-the-art not only on clean annotated text data but also on pseudo text data generated by large language models.
Read more7/9/2024

0
TAI++: Text as Image for Multi-Label Image Classification by Co-Learning Transferable Prompt
Xiangyu Wu, Qing-Yuan Jiang, Yang Yang, Yi-Feng Wu, Qing-Guo Chen, Jianfeng Lu
The recent introduction of prompt tuning based on pre-trained vision-language models has dramatically improved the performance of multi-label image classification. However, some existing strategies that have been explored still have drawbacks, i.e., either exploiting massive labeled visual data at a high cost or using text data only for text prompt tuning and thus failing to learn the diversity of visual knowledge. Hence, the application scenarios of these methods are limited. In this paper, we propose a pseudo-visual prompt~(PVP) module for implicit visual prompt tuning to address this problem. Specifically, we first learn the pseudo-visual prompt for each category, mining diverse visual knowledge by the well-aligned space of pre-trained vision-language models. Then, a co-learning strategy with a dual-adapter module is designed to transfer visual knowledge from pseudo-visual prompt to text prompt, enhancing their visual representation abilities. Experimental results on VOC2007, MS-COCO, and NUSWIDE datasets demonstrate that our method can surpass state-of-the-art~(SOTA) methods across various settings for multi-label image classification tasks. The code is available at https://github.com/njustkmg/PVP.
Read more5/14/2024

0
CLEFT: Language-Image Contrastive Learning with Efficient Large Language Model and Prompt Fine-Tuning
Yuexi Du, Brian Chang, Nicha C. Dvornek
Recent advancements in Contrastive Language-Image Pre-training (CLIP) have demonstrated notable success in self-supervised representation learning across various tasks. However, the existing CLIP-like approaches often demand extensive GPU resources and prolonged training times due to the considerable size of the model and dataset, making them poor for medical applications, in which large datasets are not always common. Meanwhile, the language model prompts are mainly manually derived from labels tied to images, potentially overlooking the richness of information within training samples. We introduce a novel language-image Contrastive Learning method with an Efficient large language model and prompt Fine-Tuning (CLEFT) that harnesses the strengths of the extensive pre-trained language and visual models. Furthermore, we present an efficient strategy for learning context-based prompts that mitigates the gap between informative clinical diagnostic data and simple class labels. Our method demonstrates state-of-the-art performance on multiple chest X-ray and mammography datasets compared with various baselines. The proposed parameter efficient framework can reduce the total trainable model size by 39% and reduce the trainable language model to only 4% compared with the current BERT encoder.
Read more7/31/2024
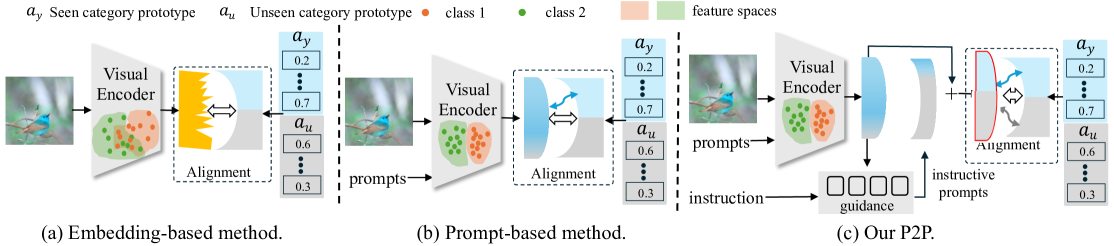
0
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Man Liu, Huihui Bai, Feng Li, Chunjie Zhang, Yunchao Wei, Meng Wang, Tat-Seng Chua, Yao Zhao
Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a textbf{P}rompt-to-textbf{P}rompt generation methodology (textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Read more6/6/2024