Advancing the Robustness of Large Language Models through Self-Denoised Smoothing
2404.12274
0
0
💬
Abstract
Although large language models (LLMs) have achieved significant success, their vulnerability to adversarial perturbations, including recent jailbreak attacks, has raised considerable concerns. However, the increasing size of these models and their limited access make improving their robustness a challenging task. Among various defense strategies, randomized smoothing has shown great potential for LLMs, as it does not require full access to the model's parameters or fine-tuning via adversarial training. However, randomized smoothing involves adding noise to the input before model prediction, and the final model's robustness largely depends on the model's performance on these noise corrupted data. Its effectiveness is often limited by the model's sub-optimal performance on noisy data. To address this issue, we propose to leverage the multitasking nature of LLMs to first denoise the noisy inputs and then to make predictions based on these denoised versions. We call this procedure self-denoised smoothing. Unlike previous denoised smoothing techniques in computer vision, which require training a separate model to enhance the robustness of LLMs, our method offers significantly better efficiency and flexibility. Our experimental results indicate that our method surpasses existing methods in both empirical and certified robustness in defending against adversarial attacks for both downstream tasks and human alignments (i.e., jailbreak attacks). Our code is publicly available at https://github.com/UCSB-NLP-Chang/SelfDenoise
Create account to get full access
Overview
- This paper proposes a new technique called "self-denoised smoothing" to improve the robustness of large language models (LLMs) to noisy inputs.
- The authors show that their method can significantly improve the performance of LLMs on adversarial and natural corruptions while maintaining high accuracy on clean data.
- The paper also presents theoretical guarantees for the proposed technique and demonstrates its effectiveness through extensive experiments.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and perform a variety of other language-related tasks. However, these models can be vulnerable to "adversarial attacks," where small, imperceptible changes to the input text can cause the model to make mistakes.
The researchers in this paper developed a new technique called "self-denoised smoothing" to make LLMs more robust to these types of attacks. The key idea is to train the model to be less sensitive to small changes in the input by adding a bit of "noise" (random variations) to the training data and then having the model learn to "denoise" or remove this noise.
This process of "self-denoised smoothing" helps the model become more resilient to the kinds of small changes that adversaries might try to exploit. The researchers show that their method can significantly improve the performance of LLMs on both adversarial attacks and more natural types of input corruption, while still maintaining the model's high accuracy on clean, unmodified data.
The paper also provides theoretical analysis to explain why this technique works and demonstrates its effectiveness through a series of experiments. Overall, this research represents an important step towards making large language models more robust and reliable, which is crucial as these models become more widely used in real-world applications.
Technical Explanation
The paper proposes a new technique called "self-denoised smoothing" to improve the robustness of large language models (LLMs) to adversarial and natural corruptions. The key idea is to augment the training data with noise (random perturbations) and then have the model learn to "denoise" or remove this noise during training.
Specifically, the authors introduce a new training objective that encourages the model to produce similar outputs for the original input and its noisy version. This self-denoising process helps the model become less sensitive to small changes in the input, making it more robust to adversarial attacks and natural corruptions.
The paper provides theoretical analysis to show that this self-denoised smoothing technique can provably improve the model's robustness. The authors also demonstrate the effectiveness of their approach through extensive experiments on a variety of LLM architectures and benchmark tasks, including language modeling, question answering, and text classification.
The results show that self-denoised smoothing can significantly improve the performance of LLMs on adversarial and natural corruptions while maintaining high accuracy on clean data. For example, the authors report that their method can improve the robustness of the GPT-3 model by up to 20 percentage points on common corruption benchmarks.
Critical Analysis
The paper presents a well-designed and thorough study on improving the robustness of large language models through self-denoised smoothing. The authors provide strong theoretical justification for their approach and demonstrate its effectiveness across multiple LLM architectures and tasks.
However, the paper does acknowledge some limitations and areas for further research. For instance, the authors note that their method may be less effective for very large models or datasets, as the computational overhead of the self-denoising process could become prohibitive. Additionally, the paper does not explore the impact of self-denoised smoothing on the interpretability or fairness of LLMs, which are important considerations for real-world applications.
Another potential concern is that the proposed technique may not be able to address all types of adversarial attacks, such as those that rely on more complex, structural changes to the input text. The authors suggest that combining self-denoised smoothing with other robustness techniques could be a promising direction for future research.
Overall, this paper represents an important contribution to the field of large language model robustness, and the self-denoised smoothing approach could be a valuable tool for improving the reliability and safety of these powerful AI systems. However, as with any research, further investigation and validation will be necessary to fully understand the implications and limitations of this technique.
Conclusion
This paper presents a novel technique called "self-denoised smoothing" that can significantly improve the robustness of large language models (LLMs) to adversarial and natural corruptions. By augmenting the training data with noise and having the model learn to denoise its outputs, the authors show that LLMs can become less sensitive to small, imperceptible changes in the input while maintaining high accuracy on clean data.
The theoretical analysis and extensive experiments in the paper provide strong evidence for the effectiveness of this approach, which could be an important step towards making LLMs more reliable and trustworthy for a wide range of real-world applications. However, the authors also acknowledge some limitations and areas for further research, such as the scalability of the technique and its impact on other model properties like interpretability and fairness.
Overall, this work represents a valuable contribution to the ongoing efforts to improve the robustness and safety of large language models, which are becoming increasingly influential in our digital world. As these powerful AI systems continue to advance, research like this will be crucial for ensuring they can be deployed in a responsible and reliable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Alexander Robey, Eric Wong, Hamed Hassani, George J. Pappas
0
0
Despite efforts to align large language models (LLMs) with human intentions, widely-used LLMs such as GPT, Llama, and Claude are susceptible to jailbreaking attacks, wherein an adversary fools a targeted LLM into generating objectionable content. To address this vulnerability, we propose SmoothLLM, the first algorithm designed to mitigate jailbreaking attacks. Based on our finding that adversarially-generated prompts are brittle to character-level changes, our defense randomly perturbs multiple copies of a given input prompt, and then aggregates the corresponding predictions to detect adversarial inputs. Across a range of popular LLMs, SmoothLLM sets the state-of-the-art for robustness against the GCG, PAIR, RandomSearch, and AmpleGCG jailbreaks. SmoothLLM is also resistant against adaptive GCG attacks, exhibits a small, though non-negligible trade-off between robustness and nominal performance, and is compatible with any LLM. Our code is publicly available at url{https://github.com/arobey1/smooth-llm}.
6/17/2024
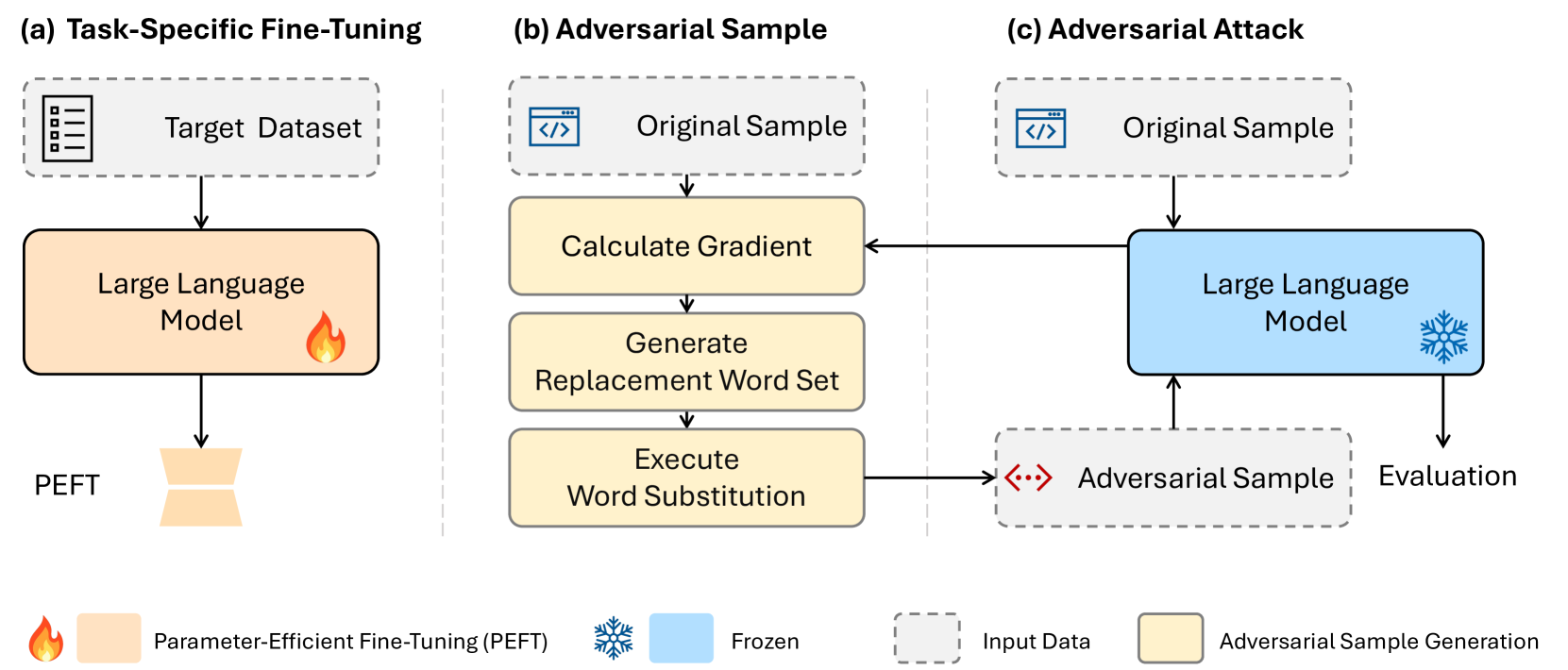
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
0
0
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
5/7/2024
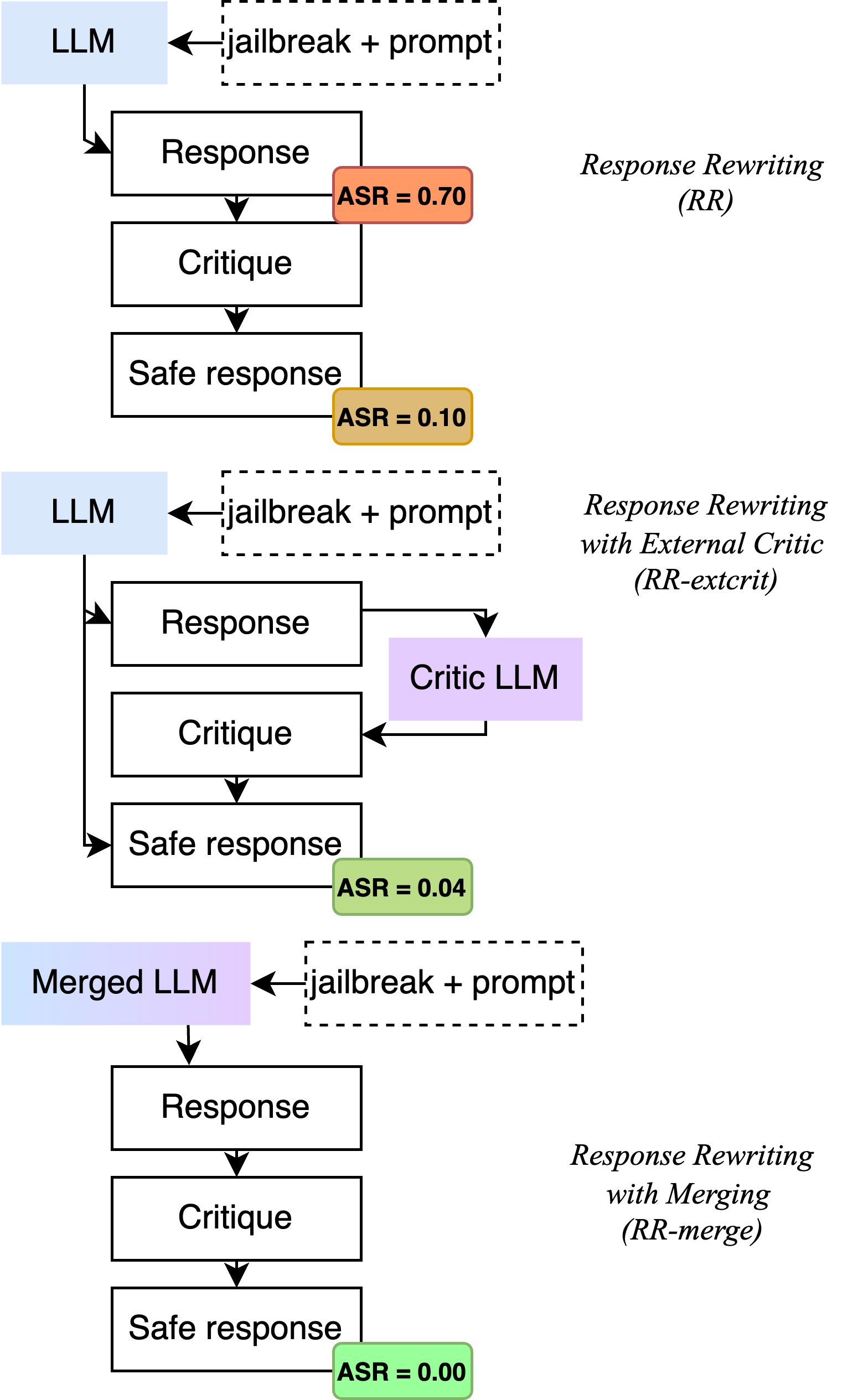
Merging Improves Self-Critique Against Jailbreak Attacks
Victor Gallego
0
0
The robustness of large language models (LLMs) against adversarial manipulations, such as jailbreak attacks, remains a significant challenge. In this work, we propose an approach that enhances the self-critique capability of the LLM and further fine-tunes it over sanitized synthetic data. This is done with the addition of an external critic model that can be merged with the original, thus bolstering self-critique capabilities and improving the robustness of the LLMs response to adversarial prompts. Our results demonstrate that the combination of merging and self-critique can reduce the attack success rate of adversaries significantly, thus offering a promising defense mechanism against jailbreak attacks. Code, data and models released at https://github.com/vicgalle/merging-self-critique-jailbreaks .
6/12/2024
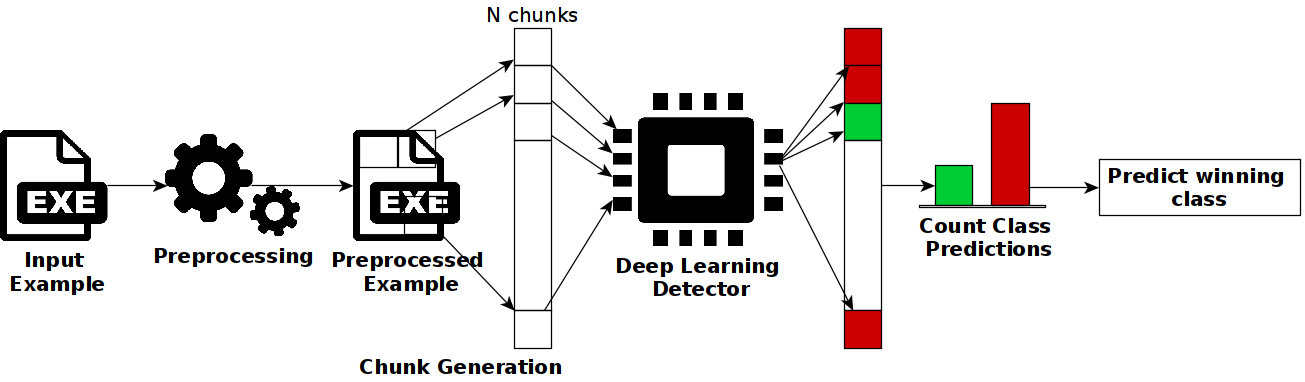
Certified Adversarial Robustness of Machine Learning-based Malware Detectors via (De)Randomized Smoothing
Daniel Gibert, Luca Demetrio, Giulio Zizzo, Quan Le, Jordi Planes, Battista Biggio
0
0
Deep learning-based malware detection systems are vulnerable to adversarial EXEmples - carefully-crafted malicious programs that evade detection with minimal perturbation. As such, the community is dedicating effort to develop mechanisms to defend against adversarial EXEmples. However, current randomized smoothing-based defenses are still vulnerable to attacks that inject blocks of adversarial content. In this paper, we introduce a certifiable defense against patch attacks that guarantees, for a given executable and an adversarial patch size, no adversarial EXEmple exist. Our method is inspired by (de)randomized smoothing which provides deterministic robustness certificates. During training, a base classifier is trained using subsets of continguous bytes. At inference time, our defense splits the executable into non-overlapping chunks, classifies each chunk independently, and computes the final prediction through majority voting to minimize the influence of injected content. Furthermore, we introduce a preprocessing step that fixes the size of the sections and headers to a multiple of the chunk size. As a consequence, the injected content is confined to an integer number of chunks without tampering the other chunks containing the real bytes of the input examples, allowing us to extend our certified robustness guarantees to content insertion attacks. We perform an extensive ablation study, by comparing our defense with randomized smoothing-based defenses against a plethora of content manipulation attacks and neural network architectures. Results show that our method exhibits unmatched robustness against strong content-insertion attacks, outperforming randomized smoothing-based defenses in the literature.
5/2/2024