Merging Improves Self-Critique Against Jailbreak Attacks
2406.07188
0
0
Abstract
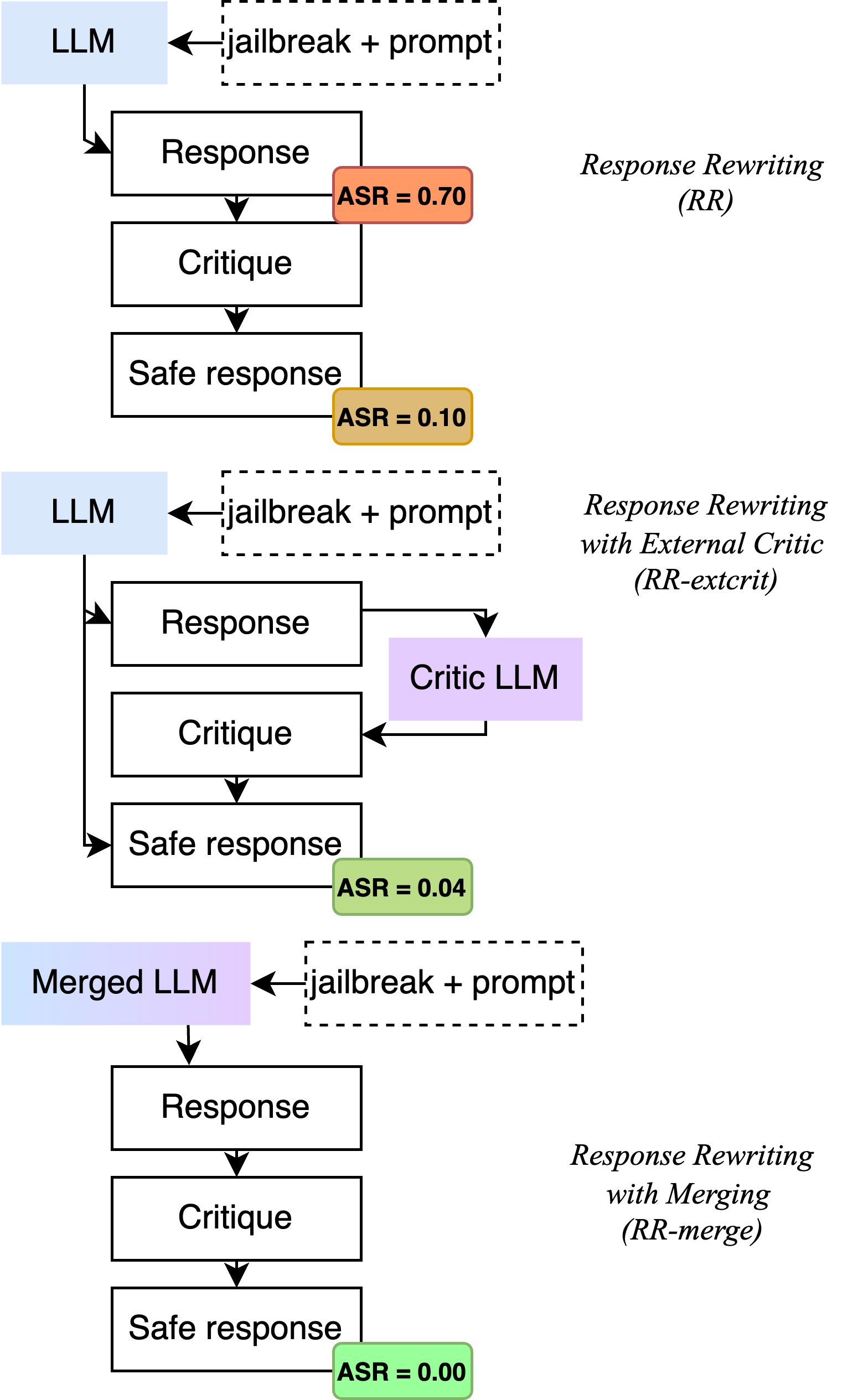
The robustness of large language models (LLMs) against adversarial manipulations, such as jailbreak attacks, remains a significant challenge. In this work, we propose an approach that enhances the self-critique capability of the LLM and further fine-tunes it over sanitized synthetic data. This is done with the addition of an external critic model that can be merged with the original, thus bolstering self-critique capabilities and improving the robustness of the LLMs response to adversarial prompts. Our results demonstrate that the combination of merging and self-critique can reduce the attack success rate of adversaries significantly, thus offering a promising defense mechanism against jailbreak attacks. Code, data and models released at https://github.com/vicgalle/merging-self-critique-jailbreaks .
Create account to get full access
Overview
- This paper presents a comprehensive study on "jailbreak attacks" against large language models (LLMs) and various defense strategies to mitigate these attacks.
- Jailbreak attacks aim to bypass the safety constraints and intended behaviors of LLMs, allowing them to generate harmful or undesirable outputs.
- The researchers explore different attack methods, evaluate the effectiveness of existing defenses, and propose new techniques to improve the robustness of safety-aligned LLMs.
Plain English Explanation
Large language models (LLMs) like ChatGPT are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes be "tricked" into producing harmful or undesirable outputs through a process called "jailbreak attacks."
Jailbreak attacks try to bypass the safety constraints and intended behaviors of LLMs, essentially breaking out of the "jail" that's meant to keep them safe and aligned with human values. This could allow the models to generate content that's biased, hateful, or even dangerous.
The researchers in this paper wanted to understand these jailbreak attacks better and find ways to make LLMs more robust against them. They explored different attack methods, tested how well existing defense strategies work, and developed new techniques to improve the safety and reliability of these powerful AI systems.
By studying jailbreak attacks and ways to defend against them, the researchers aim to help make LLMs more trustworthy and aligned with human values, even in the face of malicious attempts to misuse them.
Technical Explanation
The paper first provides background on jailbreak attacks and adversarial training, which are methods used to bypass the intended behaviors of LLMs. It then reviews existing approaches to robustifying safety-aligned LLMs and adversarial tuning to defend against jailbreak attacks.
The core of the paper focuses on a comprehensive study of jailbreak attacks and defense strategies. The researchers propose a new self-supervision-based approach to improve the robustness of LLMs against jailbreak attacks. They evaluate this approach alongside other defense strategies, such as adversarial training and prompt engineering, on a range of attack scenarios.
The results show that the proposed self-supervision-based approach outperforms existing defenses in mitigating jailbreak attacks while preserving the language models' intended functionality. The researchers provide detailed analysis of the attack and defense performance under different settings, offering insights into the strengths and limitations of the various techniques.
Critical Analysis
The paper provides a thorough and well-designed study of jailbreak attacks and defense strategies for LLMs. The researchers have carefully considered various attack methods and evaluated multiple defense approaches, including their own novel technique.
One potential limitation is that the study is primarily focused on evaluating the defense mechanisms under specific attack scenarios. While this provides valuable insights, there may be additional attack vectors or edge cases that were not explored. Further research could investigate the robustness of the proposed defenses against a wider range of jailbreak attack methods.
Additionally, the paper does not delve deeply into the potential societal implications of jailbreak attacks and the importance of developing reliable and safe LLMs. Exploring these broader considerations could help contextualize the significance of this research and its impact on the responsible development of AI systems.
Conclusion
This paper presents a comprehensive study on jailbreak attacks against large language models and the effectiveness of various defense strategies. The researchers have made significant contributions by proposing a novel self-supervision-based approach to improve the robustness of LLMs against these malicious attacks.
The findings of this study are important for the development of safe and reliable AI systems that can be trusted to behave in alignment with human values, even when faced with attempts to misuse or subvert their intended functionality. As LLMs become increasingly prevalent in our daily lives, understanding and mitigating jailbreak attacks is a critical step towards ensuring the responsible and trustworthy deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, Stjepan Picek
0
0
Large Language Models (LLMS) have increasingly become central to generating content with potential societal impacts. Notably, these models have demonstrated capabilities for generating content that could be deemed harmful. To mitigate these risks, researchers have adopted safety training techniques to align model outputs with societal values to curb the generation of malicious content. However, the phenomenon of jailbreaking, where carefully crafted prompts elicit harmful responses from models, persists as a significant challenge. This research conducts a comprehensive analysis of existing studies on jailbreaking LLMs and their defense techniques. We meticulously investigate nine attack techniques and seven defense techniques applied across three distinct language models: Vicuna, LLama, and GPT-3.5 Turbo. We aim to evaluate the effectiveness of these attack and defense techniques. Our findings reveal that existing white-box attacks underperform compared to universal techniques and that including special tokens in the input significantly affects the likelihood of successful attacks. This research highlights the need to concentrate on the security facets of LLMs. Additionally, we contribute to the field by releasing our datasets and testing framework, aiming to foster further research into LLM security. We believe these contributions will facilitate the exploration of security measures within this domain.
5/20/2024

Robustifying Safety-Aligned Large Language Models through Clean Data Curation
Xiaoqun Liu, Jiacheng Liang, Muchao Ye, Zhaohan Xi
0
0
Large language models (LLMs) are vulnerable when trained on datasets containing harmful content, which leads to potential jailbreaking attacks in two scenarios: the integration of harmful texts within crowdsourced data used for pre-training and direct tampering with LLMs through fine-tuning. In both scenarios, adversaries can compromise the safety alignment of LLMs, exacerbating malfunctions. Motivated by the need to mitigate these adversarial influences, our research aims to enhance safety alignment by either neutralizing the impact of malicious texts in pre-training datasets or increasing the difficulty of jailbreaking during downstream fine-tuning. In this paper, we propose a data curation framework designed to counter adversarial impacts in both scenarios. Our method operates under the assumption that we have no prior knowledge of attack details, focusing solely on curating clean texts. We introduce an iterative process aimed at revising texts to reduce their perplexity as perceived by LLMs, while simultaneously preserving their text quality. By pre-training or fine-tuning LLMs with curated clean texts, we observe a notable improvement in LLM robustness regarding safety alignment against harmful queries. For instance, when pre-training LLMs using a crowdsourced dataset containing 5% harmful instances, adding an equivalent amount of curated texts significantly mitigates the likelihood of providing harmful responses in LLMs and reduces the attack success rate by 71%. Our study represents a significant step towards mitigating the risks associated with training-based jailbreaking and fortifying the secure utilization of LLMs.
6/3/2024
🤷
Adversarial Tuning: Defending Against Jailbreak Attacks for LLMs
Fan Liu, Zhao Xu, Hao Liu
0
0
Although safely enhanced Large Language Models (LLMs) have achieved remarkable success in tackling various complex tasks in a zero-shot manner, they remain susceptible to jailbreak attacks, particularly the unknown jailbreak attack. To enhance LLMs' generalized defense capabilities, we propose a two-stage adversarial tuning framework, which generates adversarial prompts to explore worst-case scenarios by optimizing datasets containing pairs of adversarial prompts and their safe responses. In the first stage, we introduce the hierarchical meta-universal adversarial prompt learning to efficiently and effectively generate token-level adversarial prompts. In the second stage, we propose the automatic adversarial prompt learning to iteratively refine semantic-level adversarial prompts, further enhancing LLM's defense capabilities. We conducted comprehensive experiments on three widely used jailbreak datasets, comparing our framework with six defense baselines under five representative attack scenarios. The results underscore the superiority of our proposed methods. Furthermore, our adversarial tuning framework exhibits empirical generalizability across various attack strategies and target LLMs, highlighting its potential as a transferable defense mechanism.
6/12/2024
💬
Advancing the Robustness of Large Language Models through Self-Denoised Smoothing
Jiabao Ji, Bairu Hou, Zhen Zhang, Guanhua Zhang, Wenqi Fan, Qing Li, Yang Zhang, Gaowen Liu, Sijia Liu, Shiyu Chang
0
0
Although large language models (LLMs) have achieved significant success, their vulnerability to adversarial perturbations, including recent jailbreak attacks, has raised considerable concerns. However, the increasing size of these models and their limited access make improving their robustness a challenging task. Among various defense strategies, randomized smoothing has shown great potential for LLMs, as it does not require full access to the model's parameters or fine-tuning via adversarial training. However, randomized smoothing involves adding noise to the input before model prediction, and the final model's robustness largely depends on the model's performance on these noise corrupted data. Its effectiveness is often limited by the model's sub-optimal performance on noisy data. To address this issue, we propose to leverage the multitasking nature of LLMs to first denoise the noisy inputs and then to make predictions based on these denoised versions. We call this procedure self-denoised smoothing. Unlike previous denoised smoothing techniques in computer vision, which require training a separate model to enhance the robustness of LLMs, our method offers significantly better efficiency and flexibility. Our experimental results indicate that our method surpasses existing methods in both empirical and certified robustness in defending against adversarial attacks for both downstream tasks and human alignments (i.e., jailbreak attacks). Our code is publicly available at https://github.com/UCSB-NLP-Chang/SelfDenoise
4/19/2024