Adversarial Attacks on Large Language Models in Medicine
2406.12259
0
0
💬
Abstract
The integration of Large Language Models (LLMs) into healthcare applications offers promising advancements in medical diagnostics, treatment recommendations, and patient care. However, the susceptibility of LLMs to adversarial attacks poses a significant threat, potentially leading to harmful outcomes in delicate medical contexts. This study investigates the vulnerability of LLMs to two types of adversarial attacks in three medical tasks. Utilizing real-world patient data, we demonstrate that both open-source and proprietary LLMs are susceptible to manipulation across multiple tasks. This research further reveals that domain-specific tasks demand more adversarial data in model fine-tuning than general domain tasks for effective attack execution, especially for more capable models. We discover that while integrating adversarial data does not markedly degrade overall model performance on medical benchmarks, it does lead to noticeable shifts in fine-tuned model weights, suggesting a potential pathway for detecting and countering model attacks. This research highlights the urgent need for robust security measures and the development of defensive mechanisms to safeguard LLMs in medical applications, to ensure their safe and effective deployment in healthcare settings.
Create account to get full access
Overview
- The paper examines the vulnerability of Large Language Models (LLMs) to adversarial attacks in the context of healthcare applications.
- It investigates the susceptibility of LLMs to two types of adversarial attacks across three medical tasks, using real-world patient data.
- The research highlights the urgent need for robust security measures and the development of defensive mechanisms to ensure the safe and effective deployment of LLMs in healthcare settings.
Plain English Explanation
Large Language Models (LLMs) are powerful AI systems that can understand and generate human-like text. These models have shown great promise in the healthcare field, with potential applications in medical diagnostics, treatment recommendations, and patient care. However, the paper reveals that these models are vulnerable to adversarial attacks, which are deliberate attempts to manipulate the model's behavior in harmful ways.
The researchers in this study used real-world patient data to test the susceptibility of both open-source and proprietary LLMs to two types of adversarial attacks across three different medical tasks. They found that these models can be tricked into making incorrect or even dangerous decisions, which could potentially lead to harmful outcomes for patients.
Interestingly, the researchers discovered that tasks specific to the medical domain require more adversarial data to effectively attack the models, compared to general domain tasks. This suggests that more capable models may be more vulnerable in specialized medical contexts.
While integrating adversarial data into the model training process did not significantly degrade overall performance on medical benchmarks, it did lead to noticeable changes in the model's internal weights. This finding suggests a potential way to detect and counter these types of attacks, which is crucial for ensuring the safe and effective use of LLMs in healthcare applications.
Technical Explanation
The paper investigates the vulnerability of LLMs to two types of adversarial attacks in three medical tasks: disease diagnosis, treatment recommendation, and clinical note generation. The researchers used real-world patient data to test the susceptibility of both open-source and proprietary LLMs to these attacks.
Their experiments revealed that LLMs are indeed vulnerable to manipulation across multiple medical tasks. Notably, the researchers found that domain-specific tasks, such as those in the medical domain, require more adversarial data in the model fine-tuning process to effectively execute an attack, compared to general domain tasks.
This suggests that more capable models, which are often used in specialized medical applications, may be more vulnerable to adversarial attacks in these contexts. The researchers also discovered that while integrating adversarial data into the model training process did not significantly degrade overall performance on medical benchmarks, it did lead to noticeable shifts in the fine-tuned model weights.
This finding points to a potential pathway for detecting and countering these types of attacks, which is crucial for ensuring the safe and effective deployment of LLMs in healthcare settings.
Critical Analysis
The paper provides valuable insights into the vulnerability of LLMs to adversarial attacks in the healthcare domain. However, it is important to note that the researchers focused on only two types of adversarial attacks and three specific medical tasks. There may be other types of attacks or tasks that were not explored in this study, and the susceptibility of LLMs may vary in these cases.
Additionally, the paper does not provide a comprehensive analysis of the potential impact of these attacks on patient outcomes or the healthcare system as a whole. While the researchers highlight the urgent need for robust security measures, they do not offer detailed recommendations or strategies for developing effective defensive mechanisms.
Further research is needed to fully understand the implications of LLM vulnerabilities in the medical domain and to devise comprehensive solutions to mitigate the risks. Nonetheless, this study represents an important step in addressing a critical issue that must be addressed for the safe and effective integration of LLMs in healthcare applications.
Conclusion
This paper sheds light on the vulnerability of Large Language Models (LLMs) to adversarial attacks in the context of healthcare applications. The researchers found that both open-source and proprietary LLMs are susceptible to manipulation across multiple medical tasks, with domain-specific tasks requiring more adversarial data to effectively execute an attack.
While integrating adversarial data did not significantly degrade overall model performance, it did lead to noticeable shifts in the fine-tuned model weights, suggesting a potential pathway for detecting and countering these types of attacks. This research highlights the urgent need for robust security measures and the development of defensive mechanisms to ensure the safe and effective deployment of LLMs in healthcare settings.
As these powerful AI systems continue to be integrated into medical applications, addressing their vulnerabilities and ensuring their trustworthiness will be crucial for maintaining the integrity of the healthcare system and protecting patient wellbeing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
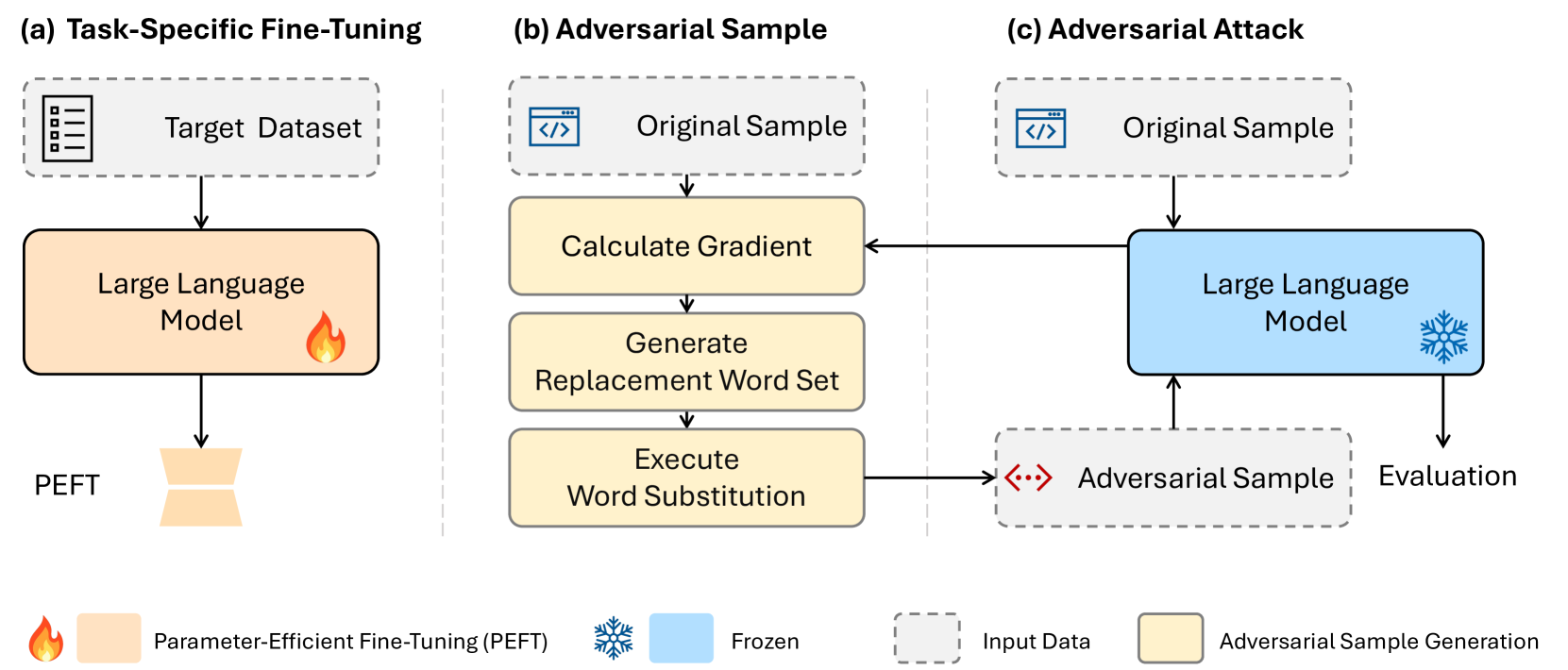
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
0
0
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
5/7/2024
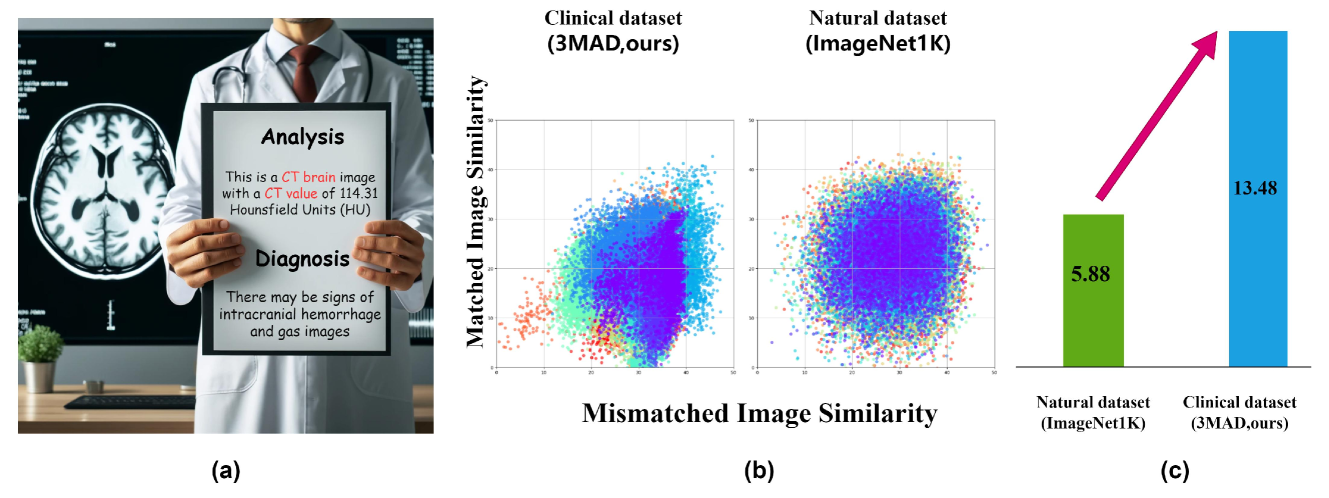
Cross-Modality Jailbreak and Mismatched Attacks on Medical Multimodal Large Language Models
Xijie Huang, Xinyuan Wang, Hantao Zhang, Jiawen Xi, Jingkun An, Hao Wang, Chengwei Pan
0
0
Security concerns related to Large Language Models (LLMs) have been extensively explored, yet the safety implications for Multimodal Large Language Models (MLLMs), particularly in medical contexts (MedMLLMs), remain insufficiently studied. This paper delves into the underexplored security vulnerabilities of MedMLLMs, especially when deployed in clinical environments where the accuracy and relevance of question-and-answer interactions are critically tested against complex medical challenges. By combining existing clinical medical data with atypical natural phenomena, we redefine two types of attacks: mismatched malicious attack (2M-attack) and optimized mismatched malicious attack (O2M-attack). Using our own constructed voluminous 3MAD dataset, which covers a wide range of medical image modalities and harmful medical scenarios, we conduct a comprehensive analysis and propose the MCM optimization method, which significantly enhances the attack success rate on MedMLLMs. Evaluations with this dataset and novel attack methods, including white-box attacks on LLaVA-Med and transfer attacks on four other state-of-the-art models, indicate that even MedMLLMs designed with enhanced security features are vulnerable to security breaches. Our work underscores the urgent need for a concerted effort to implement robust security measures and enhance the safety and efficacy of open-source MedMLLMs, particularly given the potential severity of jailbreak attacks and other malicious or clinically significant exploits in medical settings. For further research and replication, anonymous access to our code is available at https://github.com/dirtycomputer/O2M_attack. Warning: Medical large model jailbreaking may generate content that includes unverified diagnoses and treatment recommendations. Always consult professional medical advice.
6/3/2024
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024