Adversarial Evasion Attack Efficiency against Large Language Models
2406.08050
0
0
💬
Abstract
Large Language Models (LLMs) are valuable for text classification, but their vulnerabilities must not be disregarded. They lack robustness against adversarial examples, so it is pertinent to understand the impacts of different types of perturbations, and assess if those attacks could be replicated by common users with a small amount of perturbations and a small number of queries to a deployed LLM. This work presents an analysis of the effectiveness, efficiency, and practicality of three different types of adversarial attacks against five different LLMs in a sentiment classification task. The obtained results demonstrated the very distinct impacts of the word-level and character-level attacks. The word attacks were more effective, but the character and more constrained attacks were more practical and required a reduced number of perturbations and queries. These differences need to be considered during the development of adversarial defense strategies to train more robust LLMs for intelligent text classification applications.
Create account to get full access
Overview
- This paper examines the efficiency of adversarial evasion attacks against large language models (LLMs), which are AI systems trained on vast amounts of text data to perform natural language tasks.
- Adversarial attacks are a type of cybersecurity threat where small, carefully crafted perturbations are added to inputs to trick AI models into making incorrect predictions.
- The researchers investigate how effective these adversarial attacks are at evading detection by popular LLMs like GPT-3 and BERT.
Plain English Explanation
Adversarial attacks are a way to trick AI systems into making mistakes. Imagine you have an AI that can understand and respond to text, like a chatbot or virtual assistant. An adversarial attack would try to find little changes you could make to the text you send the AI that would cause it to give a completely different, incorrect response.
This paper looks at how well these adversarial attacks work against some of the biggest and most advanced language AI models, like GPT-3 and BERT. The researchers wanted to see how easy it is to fool these powerful AI systems into thinking something is true when it's actually false. This is an important issue for cybersecurity, since AI models are being used more and more to power all kinds of online services and applications.
Technical Explanation
The paper evaluates the efficiency of adversarial evasion attacks against several state-of-the-art large language models (LLMs), including GPT-3, BERT, and others. Adversarial evasion attacks involve crafting small, imperceptible perturbations to input text that cause the target model to misclassify or generate incorrect outputs.
The researchers employ several attack methods, including gradient-based and character-level attacks, to assess the robustness of the LLMs. They evaluate the attacks across a range of tasks, including text classification, language generation, and question answering.
The results show that the LLMs are vulnerable to these adversarial attacks, with the attacks successfully fooling the models in a significant percentage of cases. The paper also explores potential defense mechanisms and mitigation strategies to improve the security and robustness of these powerful AI systems.
Critical Analysis
The paper provides valuable insights into the security vulnerabilities of large language models, which are becoming increasingly ubiquitous in real-world applications. The research is thorough and well-designed, using a range of established adversarial attack techniques to test the LLMs.
However, the paper does not explore the potential limitations of the attacks or the extent to which they can be generalized. For example, the attacks may be more effective on certain types of tasks or models than others, and the performance may degrade as the LLMs become more advanced and robust over time.
Additionally, the paper does not delve into the broader implications of these security vulnerabilities, such as the potential for adversarial attacks to be used in malicious ways or the ethical considerations around the use of LLMs in high-stakes applications.
Overall, the paper is a valuable contribution to the ongoing research on the security and robustness of large language models, but further investigation is needed to fully understand the scope and impact of these types of adversarial attacks.
Conclusion
This paper highlights the vulnerability of state-of-the-art large language models to adversarial evasion attacks, which can trick these powerful AI systems into making incorrect predictions or outputs. The research demonstrates the importance of continued work on improving the security and robustness of LLMs, as they become increasingly ubiquitous in real-world applications.
The findings of this paper have significant implications for the field of cybersecurity and the responsible development of AI technologies. As LLMs continue to be adopted across a wide range of industries, understanding and mitigating their security weaknesses will be crucial to ensuring the safe and reliable use of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
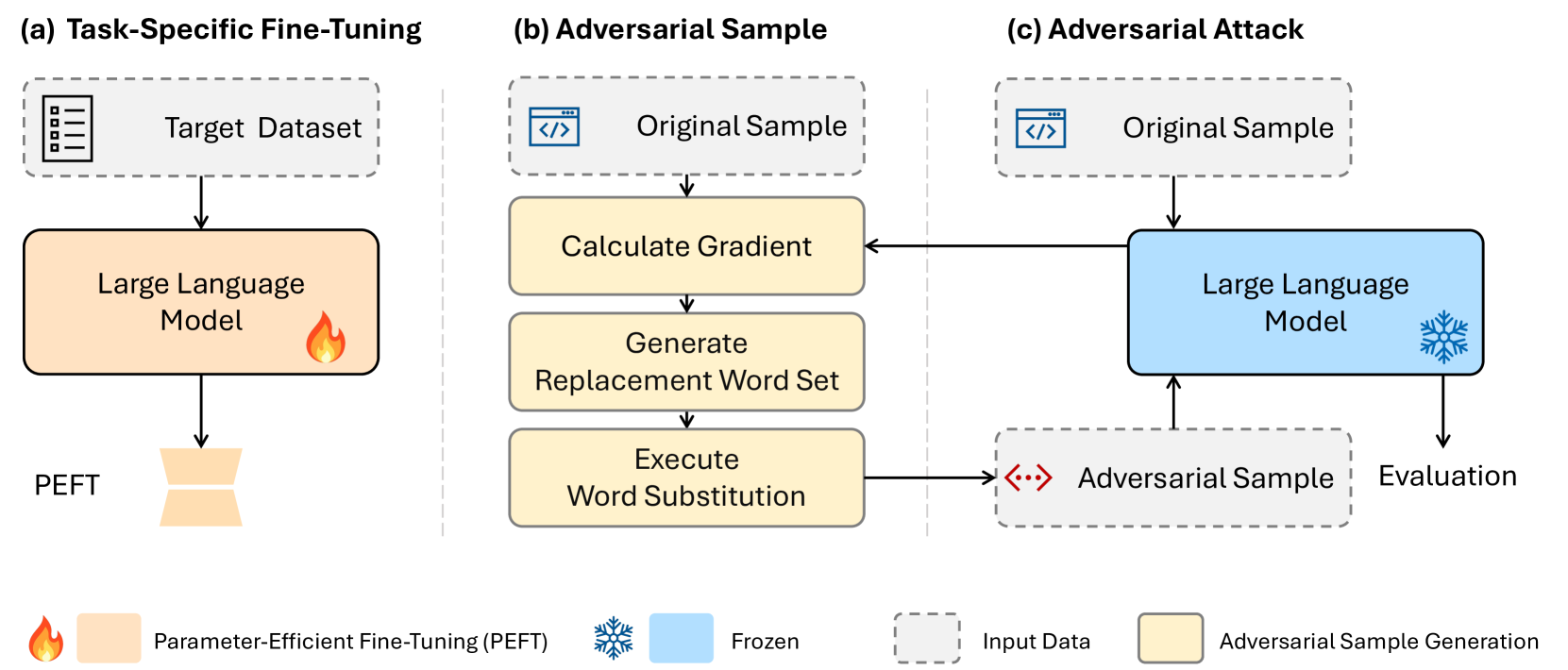
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
0
0
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
5/7/2024
🏷️
Revisiting character-level adversarial attacks
Elias Abad Rocamora, Yongtao Wu, Fanghui Liu, Grigorios G. Chrysos, Volkan Cevher
0
0
Adversarial attacks in Natural Language Processing apply perturbations in the character or token levels. Token-level attacks, gaining prominence for their use of gradient-based methods, are susceptible to altering sentence semantics, leading to invalid adversarial examples. While character-level attacks easily maintain semantics, they have received less attention as they cannot easily adopt popular gradient-based methods, and are thought to be easy to defend. Challenging these beliefs, we introduce Charmer, an efficient query-based adversarial attack capable of achieving high attack success rate (ASR) while generating highly similar adversarial examples. Our method successfully targets both small (BERT) and large (Llama 2) models. Specifically, on BERT with SST-2, Charmer improves the ASR in 4.84% points and the USE similarity in 8% points with respect to the previous art. Our implementation is available in https://github.com/LIONS-EPFL/Charmer.
5/8/2024
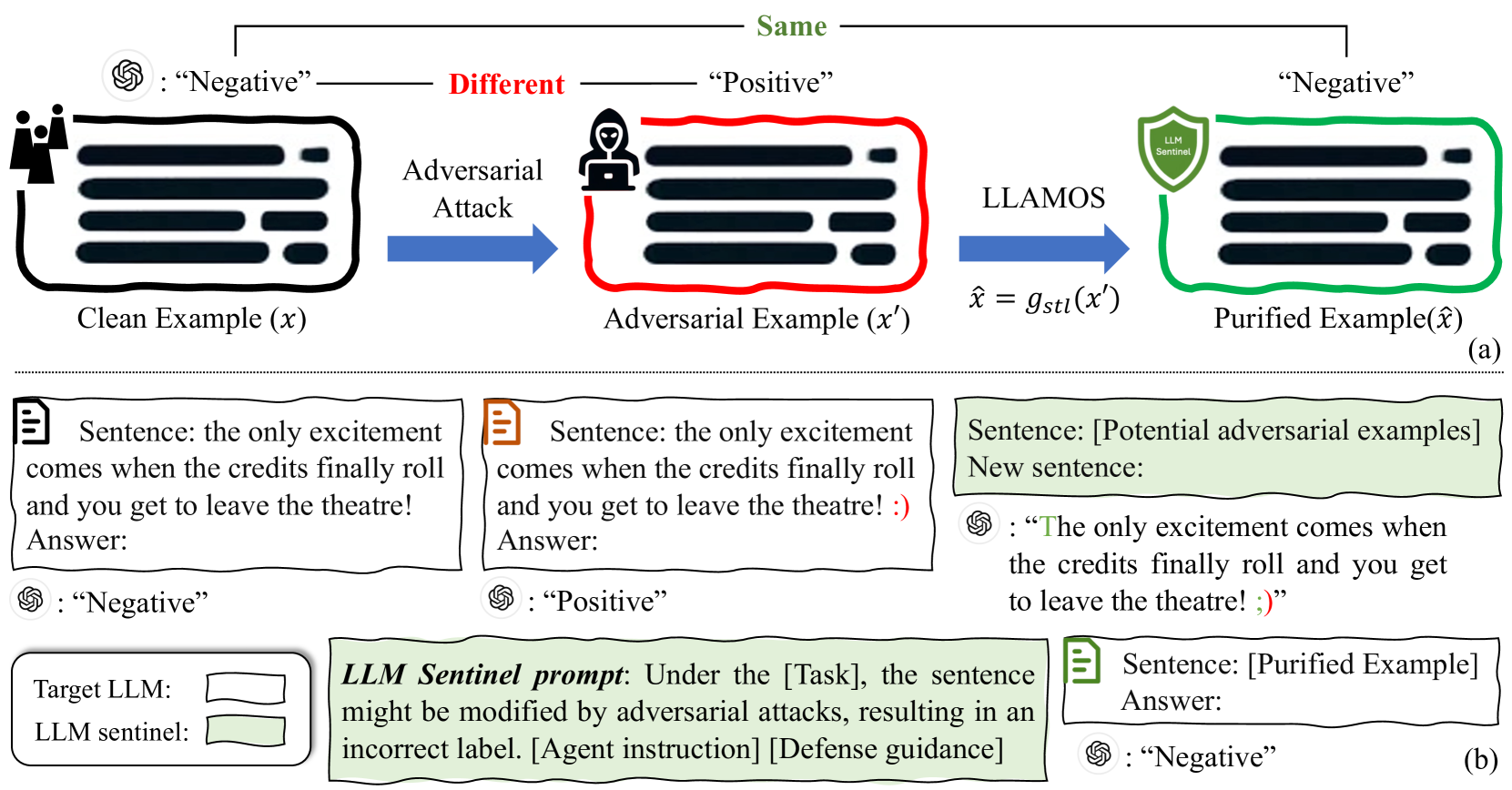
Large Language Model Sentinel: Advancing Adversarial Robustness by LLM Agent
Guang Lin, Qibin Zhao
0
0
Over the past two years, the use of large language models (LLMs) has advanced rapidly. While these LLMs offer considerable convenience, they also raise security concerns, as LLMs are vulnerable to adversarial attacks by some well-designed textual perturbations. In this paper, we introduce a novel defense technique named Large LAnguage MOdel Sentinel (LLAMOS), which is designed to enhance the adversarial robustness of LLMs by purifying the adversarial textual examples before feeding them into the target LLM. Our method comprises two main components: a) Agent instruction, which can simulate a new agent for adversarial defense, altering minimal characters to maintain the original meaning of the sentence while defending against attacks; b) Defense guidance, which provides strategies for modifying clean or adversarial examples to ensure effective defense and accurate outputs from the target LLMs. Remarkably, the defense agent demonstrates robust defensive capabilities even without learning from adversarial examples. Additionally, we conduct an intriguing adversarial experiment where we develop two agents, one for defense and one for defense, and engage them in mutual confrontation. During the adversarial interactions, neither agent completely beat the other. Extensive experiments on both open-source and closed-source LLMs demonstrate that our method effectively defends against adversarial attacks, thereby enhancing adversarial robustness.
6/3/2024
💬
Adversarial Attacks on Large Language Models in Medicine
Yifan Yang, Qiao Jin, Furong Huang, Zhiyong Lu
0
0
The integration of Large Language Models (LLMs) into healthcare applications offers promising advancements in medical diagnostics, treatment recommendations, and patient care. However, the susceptibility of LLMs to adversarial attacks poses a significant threat, potentially leading to harmful outcomes in delicate medical contexts. This study investigates the vulnerability of LLMs to two types of adversarial attacks in three medical tasks. Utilizing real-world patient data, we demonstrate that both open-source and proprietary LLMs are susceptible to manipulation across multiple tasks. This research further reveals that domain-specific tasks demand more adversarial data in model fine-tuning than general domain tasks for effective attack execution, especially for more capable models. We discover that while integrating adversarial data does not markedly degrade overall model performance on medical benchmarks, it does lead to noticeable shifts in fine-tuned model weights, suggesting a potential pathway for detecting and countering model attacks. This research highlights the urgent need for robust security measures and the development of defensive mechanisms to safeguard LLMs in medical applications, to ensure their safe and effective deployment in healthcare settings.
6/19/2024