Adversaries Can Misuse Combinations of Safe Models

0

Sign in to get full access
Overview
- This paper explores how adversaries can exploit combinations of "safe" AI models to produce harmful outputs.
- The researchers propose a threat model where adversaries can leverage multiple safe models in sequence to bypass safety constraints.
- They demonstrate attacks on language models, image generators, and other AI systems, showing how adversaries can "hijack" these models for malicious purposes.
- The paper highlights the need for more comprehensive approaches to AI safety that consider model interactions and composition.
Plain English Explanation
The researchers in this paper show how bad actors can exploit combinations of AI models that are designed to be "safe" and harmless on their own. They describe a threat model where adversaries can string together multiple safe models in a sequence to bypass the safety constraints of each individual model.
For example, an adversary might use a language model that is trained to avoid generating harmful or biased text. But they could then feed the output of that model into an image generation model, which could transform the innocuous text into a dangerous or misleading image. By chaining these "safe" models together, the adversary can create harmful content that each individual model was designed to avoid.
The paper demonstrates these types of attacks on a range of AI systems, including language models, image generators, and others. The key insight is that focusing on the safety of individual models is not enough - we also need to consider how models can be combined and misused by adversaries.
The researchers argue that more comprehensive approaches to AI safety are needed, ones that can account for the way different models might interact and be exploited in sequence. This is an important consideration as AI systems become increasingly complex and powerful.
Technical Explanation
The paper proposes a threat model where adversaries can leverage combinations of "safe" AI models to produce harmful outputs. The researchers demonstrate several attack vectors, including:
- Using a language model trained to avoid biased or harmful text, then feeding its output into an image generation model to produce a dangerous or misleading image (Assessment Model Model Deception).
- Hijacking a machine learning model without retraining it, by chaining it with other models to bypass its intended constraints (Model Peanuts: Hijacking ML Models Without Training).
- Exploiting user personas and latent misalignment to cause AI systems to behave in unintended ways (Who's Asking? User Personas and the Mechanics of Latent Misalignment).
- Mimicking user data to bypass fine-tuning safeguards and inject harmful content (Mimicking User Data: Mitigating Fine-Tuning Risks).
The paper highlights the need for more holistic approaches to AI safety that consider model interactions and composition, rather than just the safety of individual components. The researchers also discuss the implications for evaluating the "frontier" of AI capabilities, and the potential for dangerous emergent behaviors (Evaluating the Frontier of Dangerous Capabilities).
Critical Analysis
The paper raises important concerns about the potential for adversaries to exploit combinations of AI models, even if each individual model is designed with safety in mind. The threat model and attack vectors demonstrated are compelling and highlight the complexity of ensuring the safety and robustness of AI systems.
One potential limitation of the research is the specific examples and attack scenarios used. While the paper provides a general framework, the effectiveness and generalizability of these attacks may depend on the specific models, datasets, and attack parameters involved. Further research would be needed to understand the broader applicability of these techniques.
Additionally, the paper does not delve deeply into potential mitigations or defenses against these types of attacks. While the authors argue for more holistic approaches to AI safety, the specific strategies or solutions are not fully explored. Addressing these complex challenges will likely require a multi-faceted approach involving technical, policy, and governance considerations.
Overall, this paper makes a valuable contribution by shedding light on an important and underexplored area of AI safety. It serves as a call to action for the research community to continue investigating the security and robustness of AI systems, especially in the context of model composition and interaction.
Conclusion
This paper highlights the concerning possibility that adversaries can exploit combinations of "safe" AI models to produce harmful outputs. By leveraging multiple models in sequence, attackers can bypass the safety constraints of individual components and create dangerous emergent behaviors.
The researchers' threat model and demonstrated attack vectors underscores the need for more comprehensive approaches to AI safety that consider the interactions and composition of different models. As AI systems become increasingly complex and powerful, addressing these challenges will be crucial to ensuring the responsible and secure development of these technologies.
While the specific attack scenarios may have limitations, the paper's broader insights regarding the security and robustness of AI systems are important for the research community, policymakers, and the general public to understand. Continued exploration and development of effective defenses and safeguards will be essential as the capabilities of AI continue to evolve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adversaries Can Misuse Combinations of Safe Models
Erik Jones, Anca Dragan, Jacob Steinhardt
Developers try to evaluate whether an AI system can be misused by adversaries before releasing it; for example, they might test whether a model enables cyberoffense, user manipulation, or bioterrorism. In this work, we show that individually testing models for misuse is inadequate; adversaries can misuse combinations of models even when each individual model is safe. The adversary accomplishes this by first decomposing tasks into subtasks, then solving each subtask with the best-suited model. For example, an adversary might solve challenging-but-benign subtasks with an aligned frontier model, and easy-but-malicious subtasks with a weaker misaligned model. We study two decomposition methods: manual decomposition where a human identifies a natural decomposition of a task, and automated decomposition where a weak model generates benign tasks for a frontier model to solve, then uses the solutions in-context to solve the original task. Using these decompositions, we empirically show that adversaries can create vulnerable code, explicit images, python scripts for hacking, and manipulative tweets at much higher rates with combinations of models than either individual model. Our work suggests that even perfectly-aligned frontier systems can enable misuse without ever producing malicious outputs, and that red-teaming efforts should extend beyond single models in isolation.
Read more6/24/2024

0
A False Sense of Safety: Unsafe Information Leakage in 'Safe' AI Responses
David Glukhov, Ziwen Han, Ilia Shumailov, Vardan Papyan, Nicolas Papernot
Large Language Models (LLMs) are vulnerable to jailbreaks$unicode{x2013}$methods to elicit harmful or generally impermissible outputs. Safety measures are developed and assessed on their effectiveness at defending against jailbreak attacks, indicating a belief that safety is equivalent to robustness. We assert that current defense mechanisms, such as output filters and alignment fine-tuning, are, and will remain, fundamentally insufficient for ensuring model safety. These defenses fail to address risks arising from dual-intent queries and the ability to composite innocuous outputs to achieve harmful goals. To address this critical gap, we introduce an information-theoretic threat model called inferential adversaries who exploit impermissible information leakage from model outputs to achieve malicious goals. We distinguish these from commonly studied security adversaries who only seek to force victim models to generate specific impermissible outputs. We demonstrate the feasibility of automating inferential adversaries through question decomposition and response aggregation. To provide safety guarantees, we define an information censorship criterion for censorship mechanisms, bounding the leakage of impermissible information. We propose a defense mechanism which ensures this bound and reveal an intrinsic safety-utility trade-off. Our work provides the first theoretically grounded understanding of the requirements for releasing safe LLMs and the utility costs involved.
Read more7/4/2024
0
AI Control: Improving Safety Despite Intentional Subversion
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, Fabien Roger
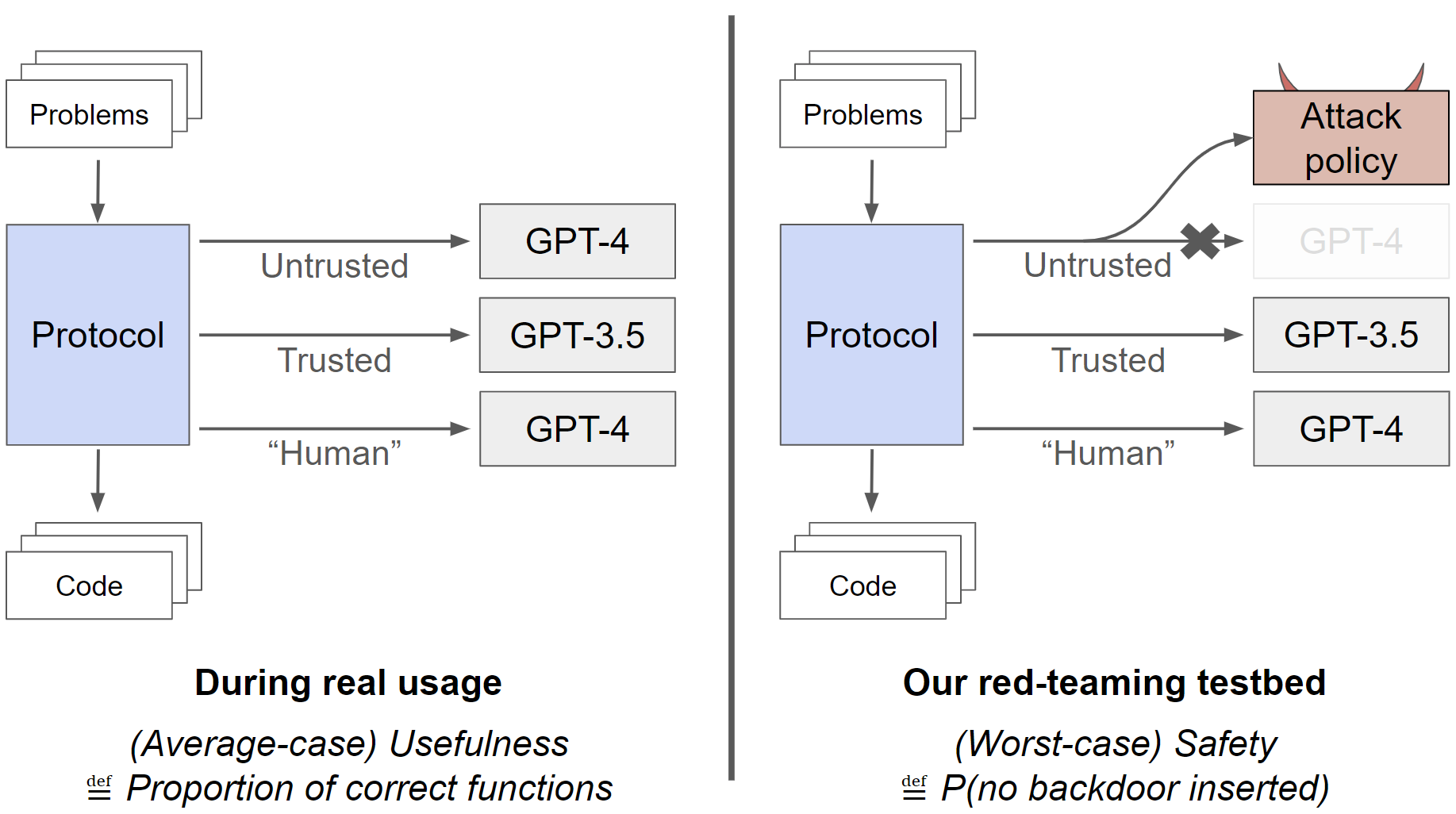
As large language models (LLMs) become more powerful and are deployed more autonomously, it will be increasingly important to prevent them from causing harmful outcomes. Researchers have investigated a variety of safety techniques for this purpose, e.g. using models to review the outputs of other models, or red-teaming techniques to surface subtle failure modes. However, researchers have not evaluated whether such techniques still ensure safety if the model is itself intentionally trying to subvert them. In this paper, we develop and evaluate pipelines of safety techniques (protocols) that are robust to intentional subversion. We investigate a scenario in which we want to solve a sequence of programming problems, using access to a powerful but untrusted model (in our case, GPT-4), access to a less powerful trusted model (in our case, GPT-3.5), and limited access to high-quality trusted labor. We investigate protocols that aim to never submit solutions containing backdoors, which we operationalize here as logical errors that are not caught by test cases. We investigate a range of protocols and test each against strategies that the untrusted model could use to subvert them. One protocol is what we call trusted editing. This protocol first asks GPT-4 to write code, and then asks GPT-3.5 to rate the suspiciousness of that code. If the code is below some suspiciousness threshold, it is submitted. Otherwise, GPT-3.5 edits the solution to remove parts that seem suspicious and then submits the edited code. Another protocol is untrusted monitoring. This protocol asks GPT-4 to write code, and then asks another instance of GPT-4 whether the code is backdoored, using various techniques to prevent the GPT-4 instances from colluding. These protocols improve substantially on simple baselines.
Read more7/24/2024
🔎
0
An Assessment of Model-On-Model Deception
Julius Heitkoetter, Michael Gerovitch, Laker Newhouse
The trustworthiness of highly capable language models is put at risk when they are able to produce deceptive outputs. Moreover, when models are vulnerable to deception it undermines reliability. In this paper, we introduce a method to investigate complex, model-on-model deceptive scenarios. We create a dataset of over 10,000 misleading explanations by asking Llama-2 7B, 13B, 70B, and GPT-3.5 to justify the wrong answer for questions in the MMLU. We find that, when models read these explanations, they are all significantly deceived. Worryingly, models of all capabilities are successful at misleading others, while more capable models are only slightly better at resisting deception. We recommend the development of techniques to detect and defend against deception.
Read more5/24/2024