Model for Peanuts: Hijacking ML Models without Training Access is Possible
2406.01708
0
0
Abstract
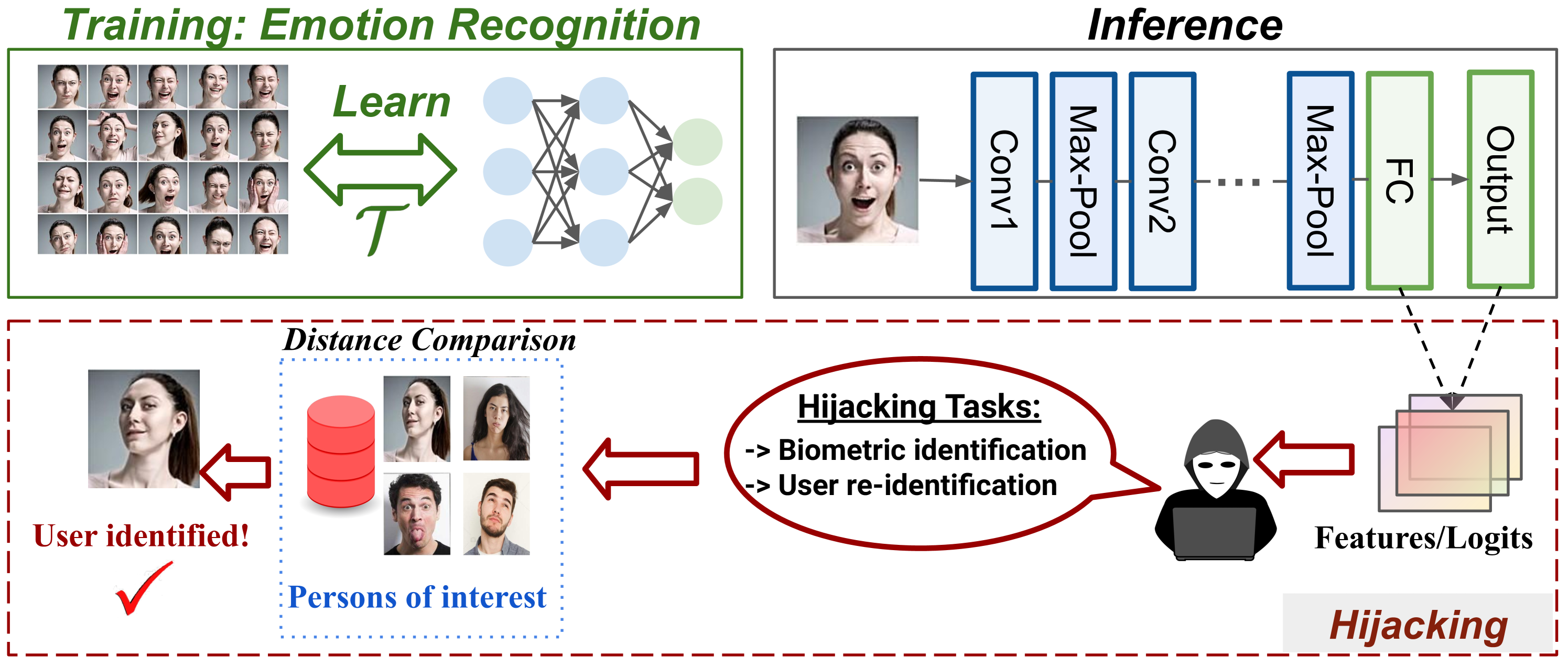
The massive deployment of Machine Learning (ML) models has been accompanied by the emergence of several attacks that threaten their trustworthiness and raise ethical and societal concerns such as invasion of privacy, discrimination risks, and lack of accountability. Model hijacking is one of these attacks, where the adversary aims to hijack a victim model to execute a different task than its original one. Model hijacking can cause accountability and security risks since a hijacked model owner can be framed for having their model offering illegal or unethical services. Prior state-of-the-art works consider model hijacking as a training time attack, whereby an adversary requires access to the ML model training to execute their attack. In this paper, we consider a stronger threat model where the attacker has no access to the training phase of the victim model. Our intuition is that ML models, typically over-parameterized, might (unintentionally) learn more than the intended task for they are trained. We propose a simple approach for model hijacking at inference time named SnatchML to classify unknown input samples using distance measures in the latent space of the victim model to previously known samples associated with the hijacking task classes. SnatchML empirically shows that benign pre-trained models can execute tasks that are semantically related to the initial task. Surprisingly, this can be true even for hijacking tasks unrelated to the original task. We also explore different methods to mitigate this risk. We first propose a novel approach we call meta-unlearning, designed to help the model unlearn a potentially malicious task while training on the original task dataset. We also provide insights on over-parameterization as one possible inherent factor that makes model hijacking easier, and we accordingly propose a compression-based countermeasure against this attack.
Create account to get full access
Overview
- The paper explores a technique called "model hijacking" that allows an attacker to obtain a functional copy of a machine learning model without access to the original training data or model parameters.
- This approach could enable adversaries to bypass the security and privacy protections of machine learning systems, posing a significant threat.
- The authors demonstrate the feasibility of this attack through experiments on various machine learning models and datasets.
Plain English Explanation
In this paper, the researchers investigate a concerning technique called "model hijacking." This allows someone to essentially steal a working copy of a machine learning model, without needing access to the original training data or model parameters.
This is a big deal because machine learning models often have security and privacy safeguards built-in to protect the sensitive information used to train them. Model hijacking could enable adversaries to bypass these protections, posing a serious threat.
The researchers show through experiments that this type of attack is feasible across different machine learning models and datasets. This means real-world machine learning systems could be vulnerable to having their models hijacked and misused.
Technical Explanation
The key insight behind the model hijacking attack is that the outputs of a machine learning model can be used to reconstruct a functional copy of that model, even without access to the original training data or model parameters.
The researchers demonstrate this by training a surrogate model that mimics the behavior of the target model using only query access. This surrogate model can then be used to execute a wide range of attacks, such as extracting the dataset used to train the original model or generating adversarial examples to control the behavior of the model.
The paper presents experiments on various machine learning tasks and model architectures, including image classification, language modeling, and graph neural networks. The results demonstrate the broad applicability of the model hijacking technique and its potential to compromise the security and privacy of real-world machine learning systems.
Critical Analysis
The researchers acknowledge several limitations and caveats to their work. For example, the model hijacking attack requires a large number of queries to the target model, which may be impractical in some real-world scenarios. Additionally, the fidelity of the surrogate model to the original may degrade as the target model becomes more complex.
Further research is needed to understand the full scope of the model hijacking threat and develop effective countermeasures. Techniques like "model unlearning" or more robust model architectures could potentially mitigate the risk of these attacks.
Overall, the paper makes a valuable contribution by highlighting a significant vulnerability in the security of machine learning systems. Researchers and practitioners in the field should take this threat seriously and work to develop robust solutions to protect against model hijacking attacks.
Conclusion
This paper presents a concerning technique called "model hijacking" that allows an attacker to obtain a functional copy of a machine learning model without access to the original training data or model parameters. The researchers demonstrate the feasibility of this attack through extensive experiments, showing that it poses a serious threat to the security and privacy of real-world machine learning systems.
While the attack has some practical limitations, the findings in this paper underscore the importance of developing robust defenses against model extraction and other model-based attacks. Continued research and innovation in this area will be crucial to ensuring the safe and trustworthy deployment of machine learning technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Beyond Labeling Oracles: What does it mean to steal ML models?
Avital Shafran, Ilia Shumailov, Murat A. Erdogdu, Nicolas Papernot
0
0
Model extraction attacks are designed to steal trained models with only query access, as is often provided through APIs that ML-as-a-Service providers offer. Machine Learning (ML) models are expensive to train, in part because data is hard to obtain, and a primary incentive for model extraction is to acquire a model while incurring less cost than training from scratch. Literature on model extraction commonly claims or presumes that the attacker is able to save on both data acquisition and labeling costs. We thoroughly evaluate this assumption and find that the attacker often does not. This is because current attacks implicitly rely on the adversary being able to sample from the victim model's data distribution. We thoroughly research factors influencing the success of model extraction. We discover that prior knowledge of the attacker, i.e., access to in-distribution data, dominates other factors like the attack policy the adversary follows to choose which queries to make to the victim model API. Our findings urge the community to redefine the adversarial goals of ME attacks as current evaluation methods misinterpret the ME performance.
6/14/2024
🖼️
Image Hijacks: Adversarial Images can Control Generative Models at Runtime
Luke Bailey, Euan Ong, Stuart Russell, Scott Emmons
0
0
Are foundation models secure against malicious actors? In this work, we focus on the image input to a vision-language model (VLM). We discover image hijacks, adversarial images that control the behaviour of VLMs at inference time, and introduce the general Behaviour Matching algorithm for training image hijacks. From this, we derive the Prompt Matching method, allowing us to train hijacks matching the behaviour of an arbitrary user-defined text prompt (e.g. 'the Eiffel Tower is now located in Rome') using a generic, off-the-shelf dataset unrelated to our choice of prompt. We use Behaviour Matching to craft hijacks for four types of attack, forcing VLMs to generate outputs of the adversary's choice, leak information from their context window, override their safety training, and believe false statements. We study these attacks against LLaVA, a state-of-the-art VLM based on CLIP and LLaMA-2, and find that all attack types achieve a success rate of over 80%. Moreover, our attacks are automated and require only small image perturbations.
4/24/2024

Reconstruction Attacks on Machine Unlearning: Simple Models are Vulnerable
Martin Bertran, Shuai Tang, Michael Kearns, Jamie Morgenstern, Aaron Roth, Zhiwei Steven Wu
0
0
Machine unlearning is motivated by desire for data autonomy: a person can request to have their data's influence removed from deployed models, and those models should be updated as if they were retrained without the person's data. We show that, counter-intuitively, these updates expose individuals to high-accuracy reconstruction attacks which allow the attacker to recover their data in its entirety, even when the original models are so simple that privacy risk might not otherwise have been a concern. We show how to mount a near-perfect attack on the deleted data point from linear regression models. We then generalize our attack to other loss functions and architectures, and empirically demonstrate the effectiveness of our attacks across a wide range of datasets (capturing both tabular and image data). Our work highlights that privacy risk is significant even for extremely simple model classes when individuals can request deletion of their data from the model.
5/31/2024
💬
Hijacking Large Language Models via Adversarial In-Context Learning
Yao Qiang, Xiangyu Zhou, Dongxiao Zhu
0
0
In-context learning (ICL) has emerged as a powerful paradigm leveraging LLMs for specific downstream tasks by utilizing labeled examples as demonstrations (demos) in the precondition prompts. Despite its promising performance, ICL suffers from instability with the choice and arrangement of examples. Additionally, crafted adversarial attacks pose a notable threat to the robustness of ICL. However, existing attacks are either easy to detect, rely on external models, or lack specificity towards ICL. This work introduces a novel transferable attack against ICL to address these issues, aiming to hijack LLMs to generate the target response or jailbreak. Our hijacking attack leverages a gradient-based prompt search method to learn and append imperceptible adversarial suffixes to the in-context demos without directly contaminating the user queries. Comprehensive experimental results across different generation and jailbreaking tasks highlight the effectiveness of our hijacking attack, resulting in distracted attention towards adversarial tokens and consequently leading to unwanted target outputs. We also propose a defense strategy against hijacking attacks through the use of extra clean demos, which enhances the robustness of LLMs during ICL. Broadly, this work reveals the significant security vulnerabilities of LLMs and emphasizes the necessity for in-depth studies on their robustness.
6/18/2024