Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents

5
Sign in to get full access
Overview
- This paper presents "Agent Hospital," a simulated hospital environment designed to evaluate medical agents and their decision-making capabilities.
- The goal is to create a realistic testbed for developing and testing artificial intelligence (AI) agents that can assist in clinical decision-making and patient care.
- The paper explores the use of evolvable medical agents, which can adapt and improve their performance over time through interactions within the simulated hospital setting.
Plain English Explanation
The researchers have created a virtual hospital environment called "Agent Hospital" to study how AI-based medical agents can be developed and tested. The idea is to build a realistic simulation that can serve as a testbed for these AI systems, allowing them to interact with virtual patients and healthcare professionals in a controlled setting.
The key innovation is the use of "evolvable medical agents" - AI agents that can learn and improve their decision-making abilities over time through their experiences within the simulated hospital. This could be a powerful approach for creating AI systems that can eventually assist human healthcare providers in real-world settings, by allowing the agents to learn and adapt in a safe, simulated environment before being deployed in the field.
By constructing this virtual hospital, the researchers aim to accelerate the development of AI-powered medical decision support systems that could potentially enhance patient care and outcomes. This relates to the work described in the paper "Leveraging Large Language Model as Simulated Patients".
Technical Explanation
The paper introduces the "Agent Hospital" framework, which is designed to serve as a simulated hospital environment for evaluating the performance of medical AI agents. This virtual hospital includes various departments, staff roles, and patient cases that the AI agents can interact with and learn from.
A key aspect of the Agent Hospital is the use of "evolvable medical agents" - AI systems that can adapt and improve their decision-making capabilities over time through their experiences within the simulated setting. These agents are trained using reinforcement learning techniques, where they receive feedback and rewards based on the outcomes of their actions, allowing them to optimize their strategies.
The paper also discusses the integration of large language models, which can be leveraged to simulate realistic patient interactions and conversations. This relates to the work described in the paper "Autonomous Artificial Intelligence Agents for Clinical Decision-Making". Additionally, the authors explore techniques for automatically generating high-quality medical simulation scenarios to further enrich the training environment. This relates to the paper "Automated Generation of High-Quality Medical Simulation Scenarios".
By creating this simulated hospital ecosystem, the researchers aim to provide a platform for developing and evaluating AI agents that can assist in clinical decision-making and patient care. This relates to the work described in the paper "Adaptive Collaboration Strategy for LLMs in Medical Decision-Making" and the paper "CT-Agent: Clinical Trial Multi-Agent Large Language Model"](https://aimodels.fyi/papers/arxiv/ct-agent-clinical-trial-multi-agent-large).
Critical Analysis
The paper presents a novel and ambitious approach to creating a simulated hospital environment for the development and testing of medical AI agents. The use of evolvable agents that can adapt and improve their performance through interactions within the simulated setting is a promising direction, as it could lead to more robust and clinically applicable AI systems.
However, the researchers acknowledge that there are significant challenges in accurately replicating the complex and dynamic nature of a real-world hospital environment. Ensuring the fidelity and representativeness of the simulated scenarios and patient cases is crucial for the insights gained from the Agent Hospital to be truly applicable to real-world medical decision-making.
Additionally, the paper does not address potential ethical concerns or biases that may arise from the development and deployment of such AI systems in healthcare. The authors should consider discussing the importance of transparency, accountability, and fairness in the design and evaluation of the medical AI agents.
Further research is needed to explore the scalability and generalizability of the Agent Hospital framework, as well as its ability to capture the nuances and uncertainties inherent in clinical decision-making. Collaborations with healthcare professionals and regulatory bodies may also be necessary to ensure the responsible development and integration of these AI-powered systems into real-world hospital settings.
Conclusion
The "Agent Hospital" framework presented in this paper represents a significant step forward in the development of AI-powered medical decision support systems. By creating a simulated hospital environment that allows for the evolution and evaluation of medical agents, the researchers aim to accelerate the progress of this important field.
The use of evolvable agents and the integration of large language models and automated scenario generation techniques are particularly promising directions that could lead to more robust and clinically relevant AI systems. However, the paper also highlights the need to address the challenges of accurately replicating the complexities of real-world hospital settings and to consider the ethical implications of deploying such AI systems in healthcare.
As the field of medical AI continues to advance, the Agent Hospital framework and the insights gained from this research could contribute to the development of AI-powered tools and technologies that can enhance patient care and improve healthcare outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
5
Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents
Junkai Li, Siyu Wang, Meng Zhang, Weitao Li, Yunghwei Lai, Xinhui Kang, Weizhi Ma, Yang Liu
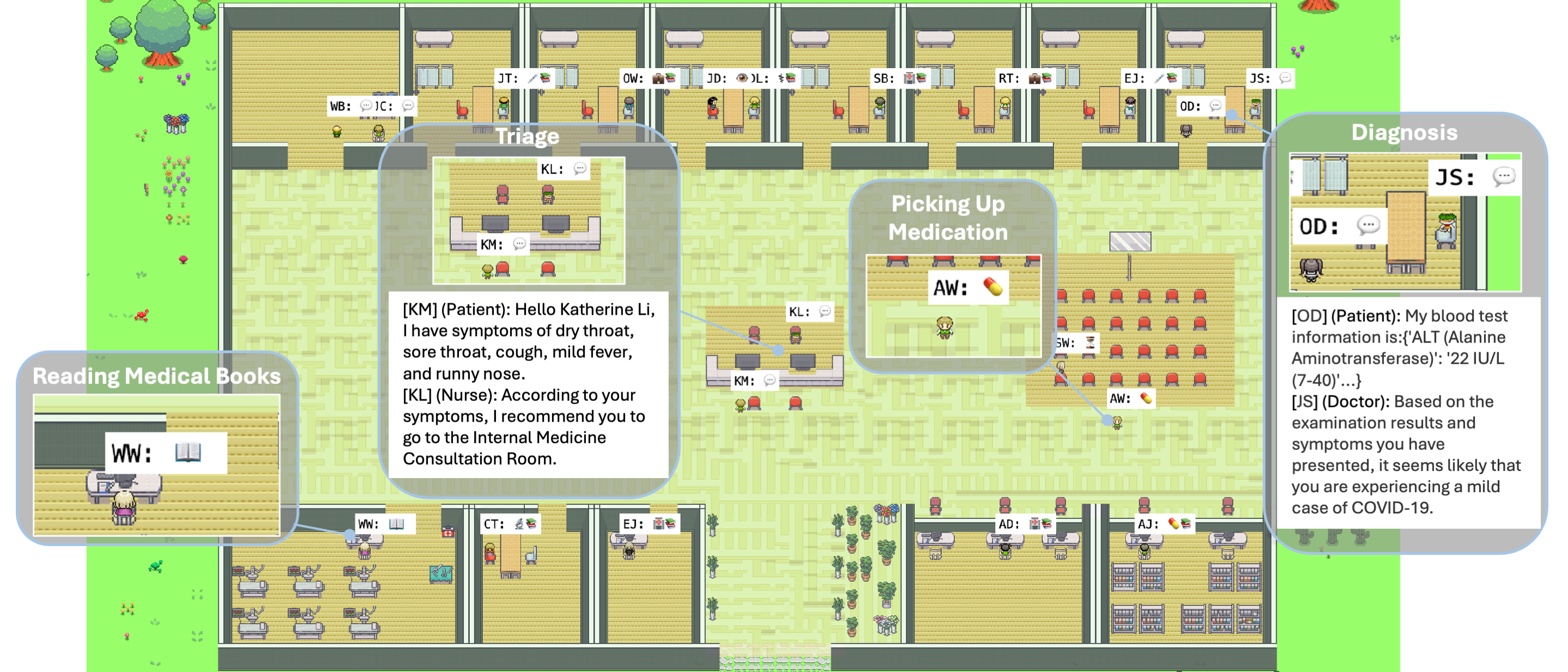
In this paper, we introduce a simulacrum of hospital called Agent Hospital that simulates the entire process of treating illness. All patients, nurses, and doctors are autonomous agents powered by large language models (LLMs). Our central goal is to enable a doctor agent to learn how to treat illness within the simulacrum. To do so, we propose a method called MedAgent-Zero. As the simulacrum can simulate disease onset and progression based on knowledge bases and LLMs, doctor agents can keep accumulating experience from both successful and unsuccessful cases. Simulation experiments show that the treatment performance of doctor agents consistently improves on various tasks. More interestingly, the knowledge the doctor agents have acquired in Agent Hospital is applicable to real-world medicare benchmarks. After treating around ten thousand patients (real-world doctors may take over two years), the evolved doctor agent achieves a state-of-the-art accuracy of 93.06% on a subset of the MedQA dataset that covers major respiratory diseases. This work paves the way for advancing the applications of LLM-powered agent techniques in medical scenarios.
Read more5/7/2024
🤖
0
AI Hospital: Benchmarking Large Language Models in a Multi-agent Medical Interaction Simulator
Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xi, Fei Huang, Jingren Zhou
Artificial intelligence has significantly advanced healthcare, particularly through large language models (LLMs) that excel in medical question answering benchmarks. However, their real-world clinical application remains limited due to the complexities of doctor-patient interactions. To address this, we introduce textbf{AI Hospital}, a multi-agent framework simulating dynamic medical interactions between emph{Doctor} as player and NPCs including emph{Patient}, emph{Examiner}, emph{Chief Physician}. This setup allows for realistic assessments of LLMs in clinical scenarios. We develop the Multi-View Medical Evaluation (MVME) benchmark, utilizing high-quality Chinese medical records and NPCs to evaluate LLMs' performance in symptom collection, examination recommendations, and diagnoses. Additionally, a dispute resolution collaborative mechanism is proposed to enhance diagnostic accuracy through iterative discussions. Despite improvements, current LLMs exhibit significant performance gaps in multi-turn interactions compared to one-step approaches. Our findings highlight the need for further research to bridge these gaps and improve LLMs' clinical diagnostic capabilities. Our data, code, and experimental results are all open-sourced at url{https://github.com/LibertFan/AI_Hospital}.
Read more7/1/2024
🤖
0
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, Michael Moor
Diagnosing and managing a patient is a complex, sequential decision making process that requires physicians to obtain information -- such as which tests to perform -- and to act upon it. Recent advances in artificial intelligence (AI) and large language models (LLMs) promise to profoundly impact clinical care. However, current evaluation schemes overrely on static medical question-answering benchmarks, falling short on interactive decision-making that is required in real-life clinical work. Here, we present AgentClinic: a multimodal benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments. In our benchmark, the doctor agent must uncover the patient's diagnosis through dialogue and active data collection. We present two open medical agent benchmarks: a multimodal image and dialogue environment, AgentClinic-NEJM, and a dialogue-only environment, AgentClinic-MedQA. We embed cognitive and implicit biases both in patient and doctor agents to emulate realistic interactions between biased agents. We find that introducing bias leads to large reductions in diagnostic accuracy of the doctor agents, as well as reduced compliance, confidence, and follow-up consultation willingness in patient agents. Evaluating a suite of state-of-the-art LLMs, we find that several models that excel in benchmarks like MedQA are performing poorly in AgentClinic-MedQA. We find that the LLM used in the patient agent is an important factor for performance in the AgentClinic benchmark. We show that both having limited interactions as well as too many interaction reduces diagnostic accuracy in doctor agents. The code and data for this work is publicly available at https://AgentClinic.github.io.
Read more6/3/2024
💬
0
MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, Mark Gerstein
Large language models (LLMs), despite their remarkable progress across various general domains, encounter significant barriers in medicine and healthcare. This field faces unique challenges such as domain-specific terminologies and reasoning over specialized knowledge. To address these issues, we propose MedAgents, a novel multi-disciplinary collaboration framework for the medical domain. MedAgents leverages LLM-based agents in a role-playing setting that participate in a collaborative multi-round discussion, thereby enhancing LLM proficiency and reasoning capabilities. This training-free framework encompasses five critical steps: gathering domain experts, proposing individual analyses, summarising these analyses into a report, iterating over discussions until a consensus is reached, and ultimately making a decision. Our work focuses on the zero-shot setting, which is applicable in real-world scenarios. Experimental results on nine datasets (MedQA, MedMCQA, PubMedQA, and six subtasks from MMLU) establish that our proposed MedAgents framework excels at mining and harnessing the medical expertise within LLMs, as well as extending its reasoning abilities. Our code can be found at https://github.com/gersteinlab/MedAgents.
Read more6/6/2024